【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【遇到的问题:问题现象及影响】
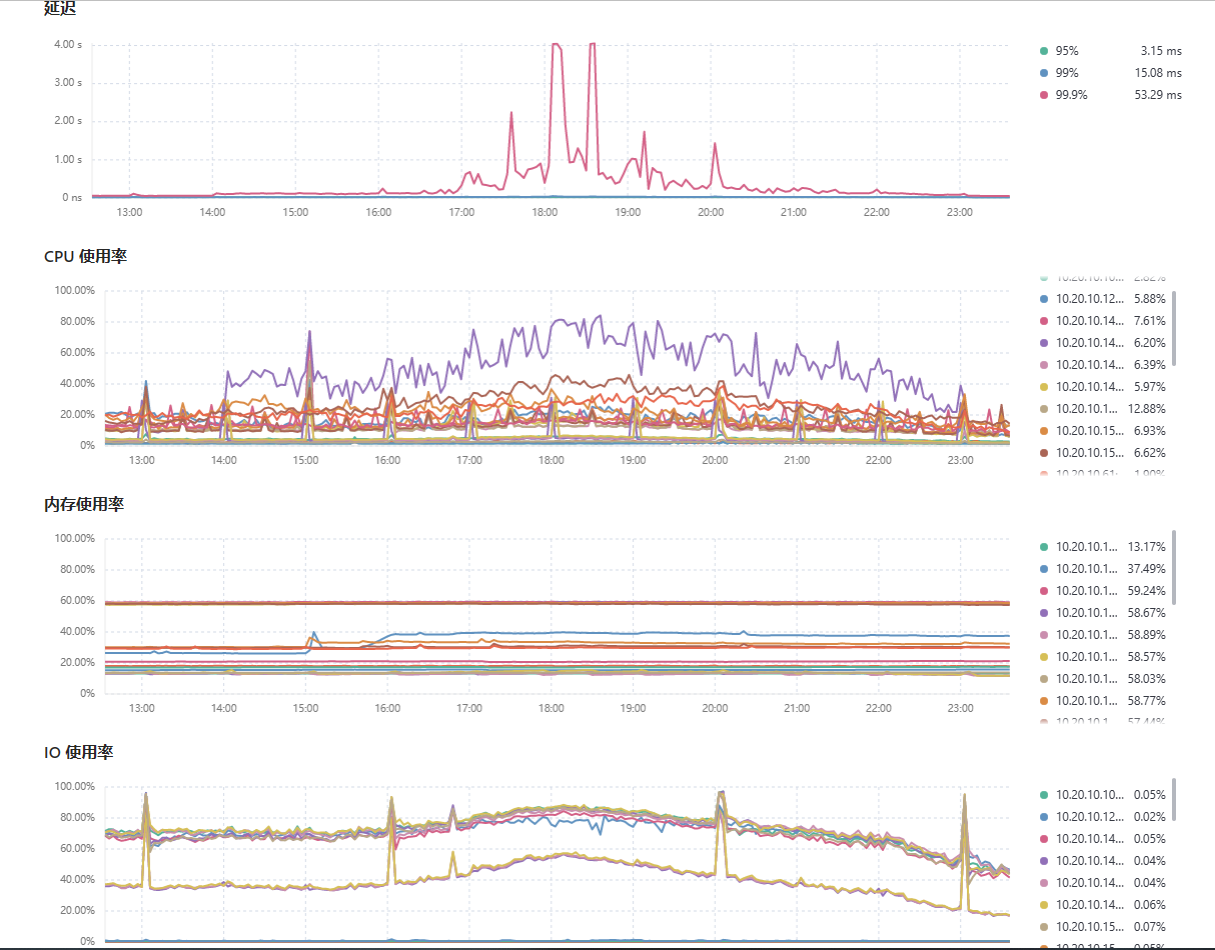
昨天下午2点开始有一个tikv节点的cpu突然升高,到17点的时候数据库延迟开始升高,一些查询平时只需要几十毫秒的sql变成了十几秒,请问有什么排查方向吗?
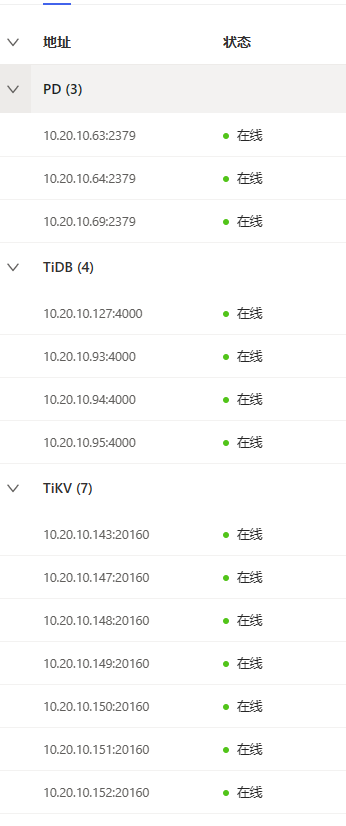
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【遇到的问题:问题现象及影响】
昨天下午2点开始有一个tikv节点的cpu突然升高,到17点的时候数据库延迟开始升高,一些查询平时只需要几十毫秒的sql变成了十几秒,请问有什么排查方向吗?
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
参考下这个
dashboard上有热点问题吗?另外拓扑结构发下,cpu高的这个tikv是不是混合部署啊?
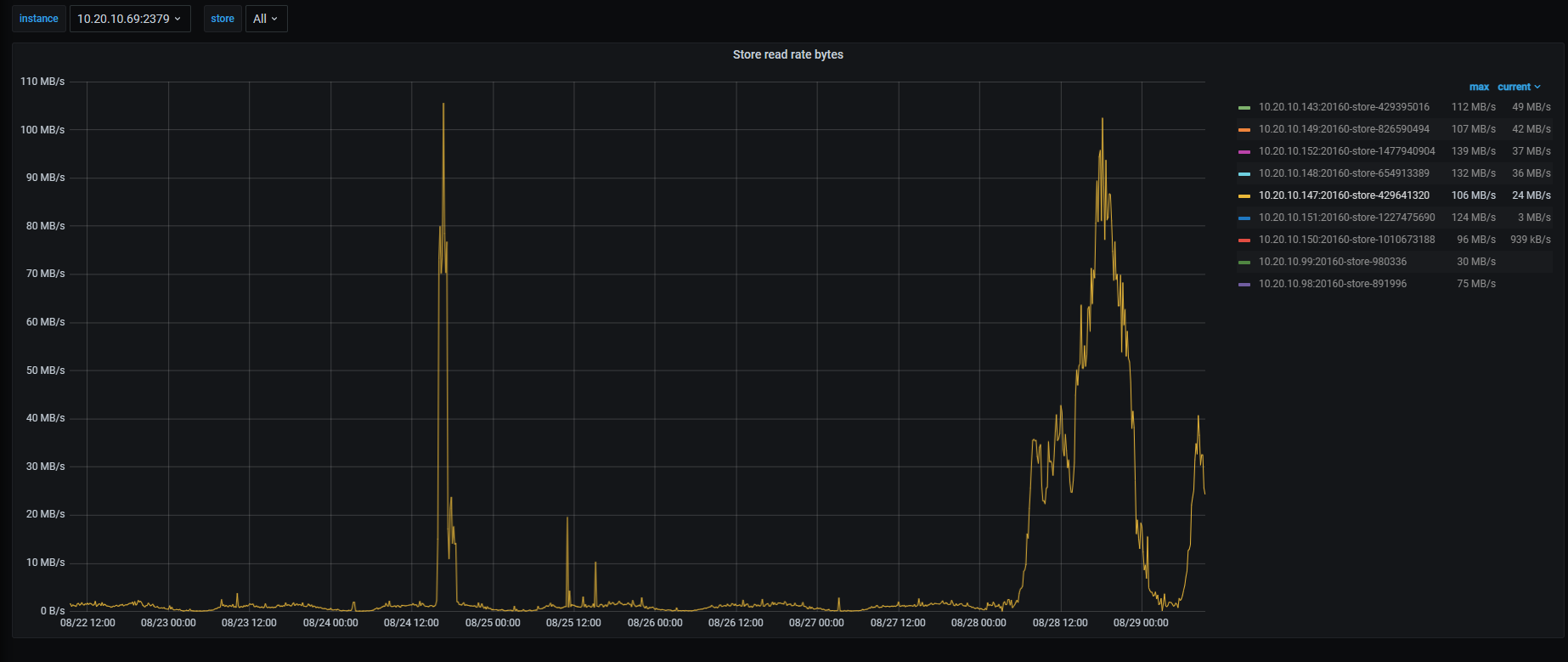
只有这个kv节点流量变大延迟变大,其他kv都正常的,kv这个日志也没看出来他在干嘛 就很奇怪
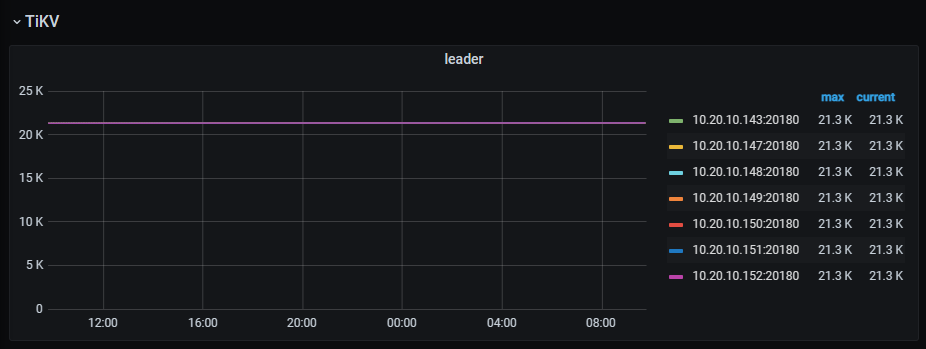
leader分布情况,最近有变化吗?
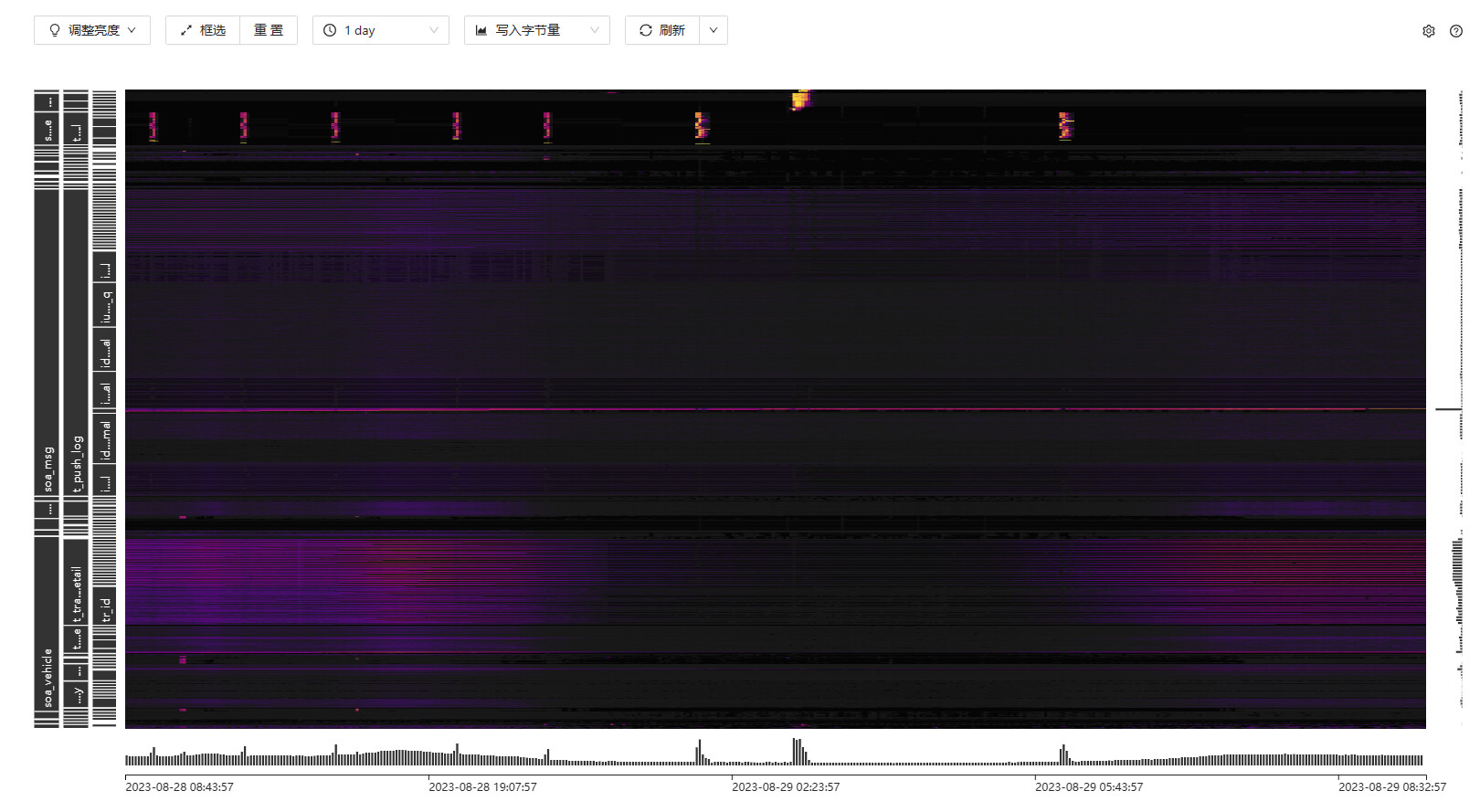
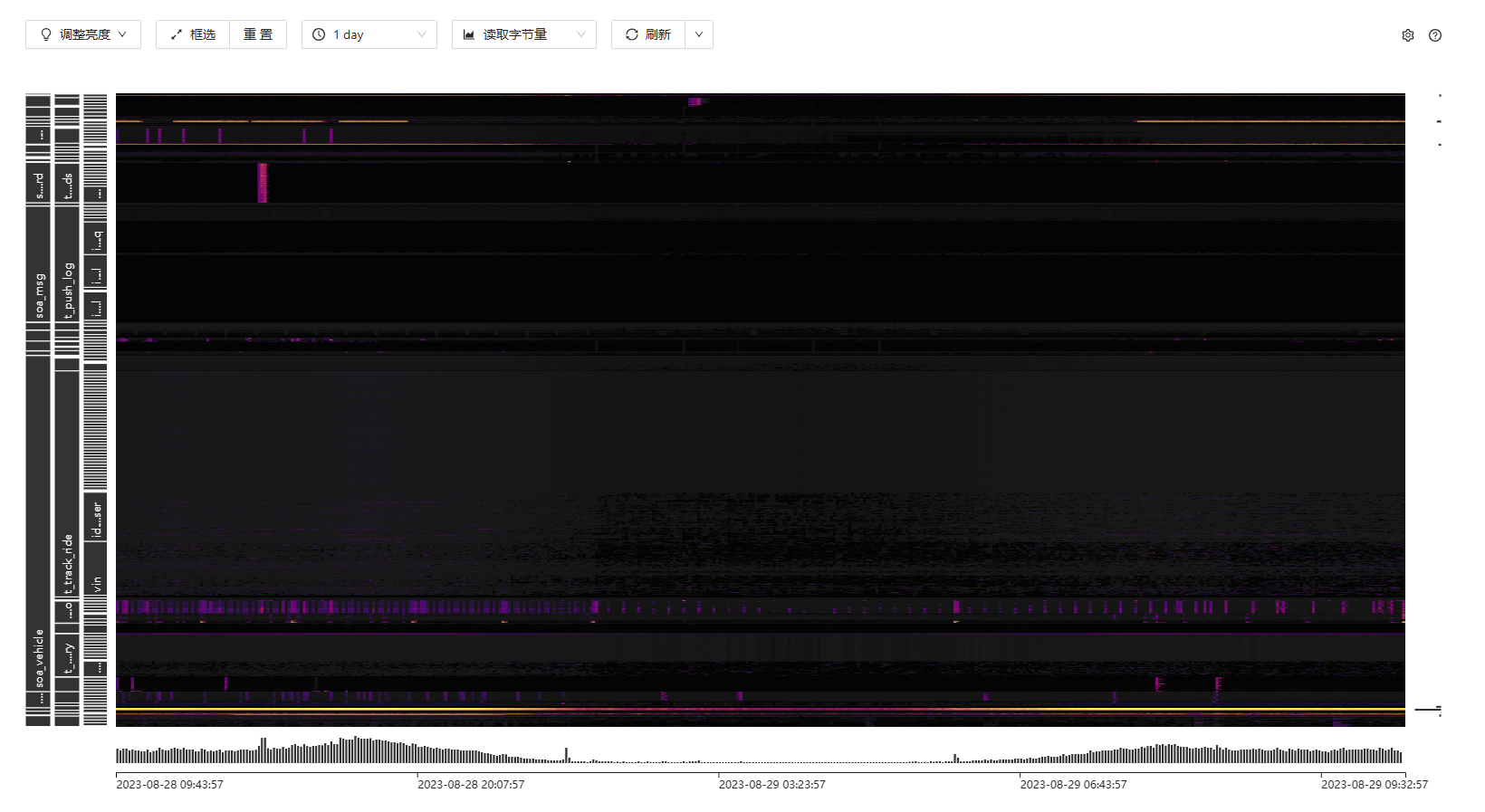
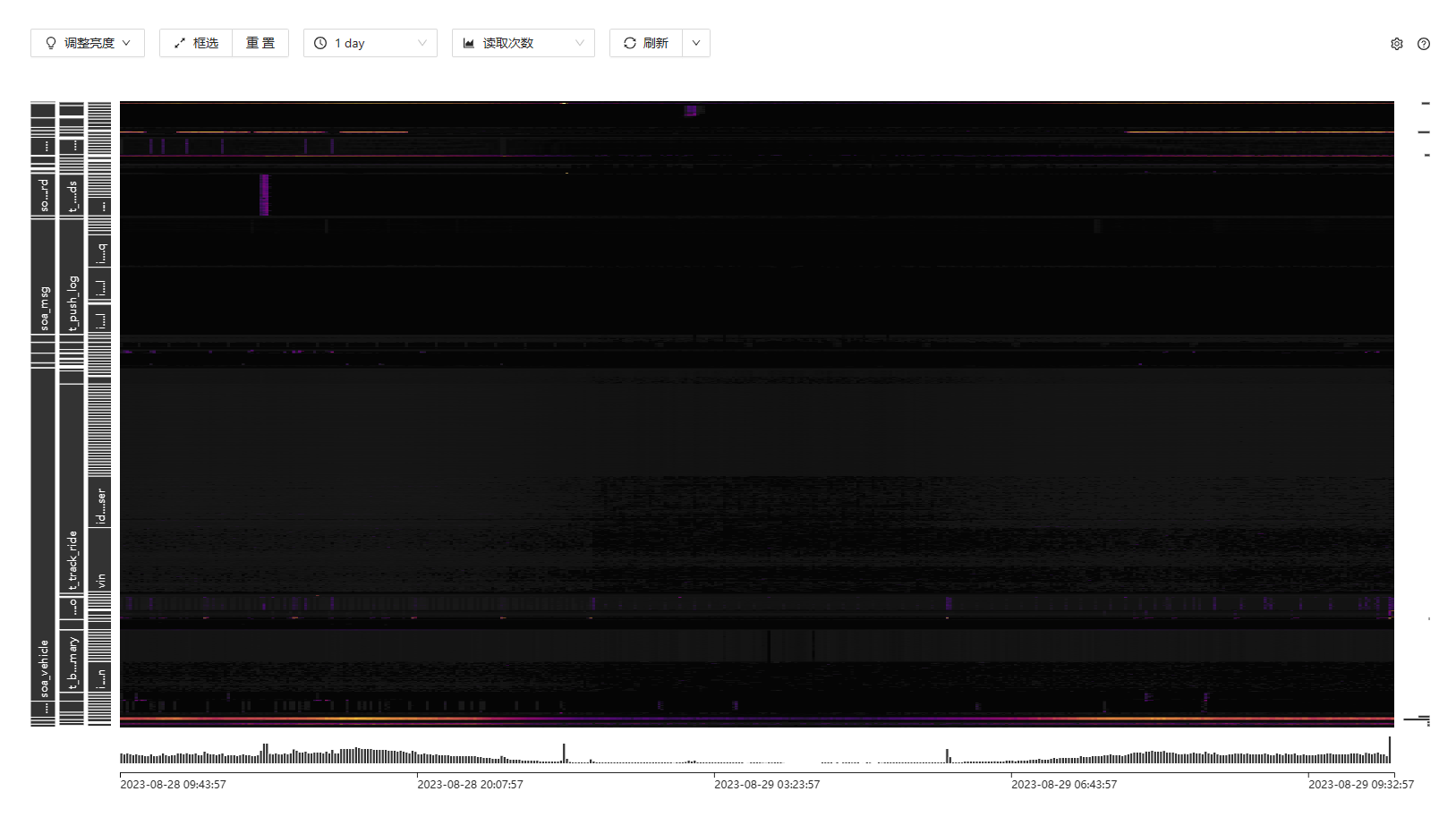
到dashboard 上看看在这个时段的读热点情况,推测是这方面的问题
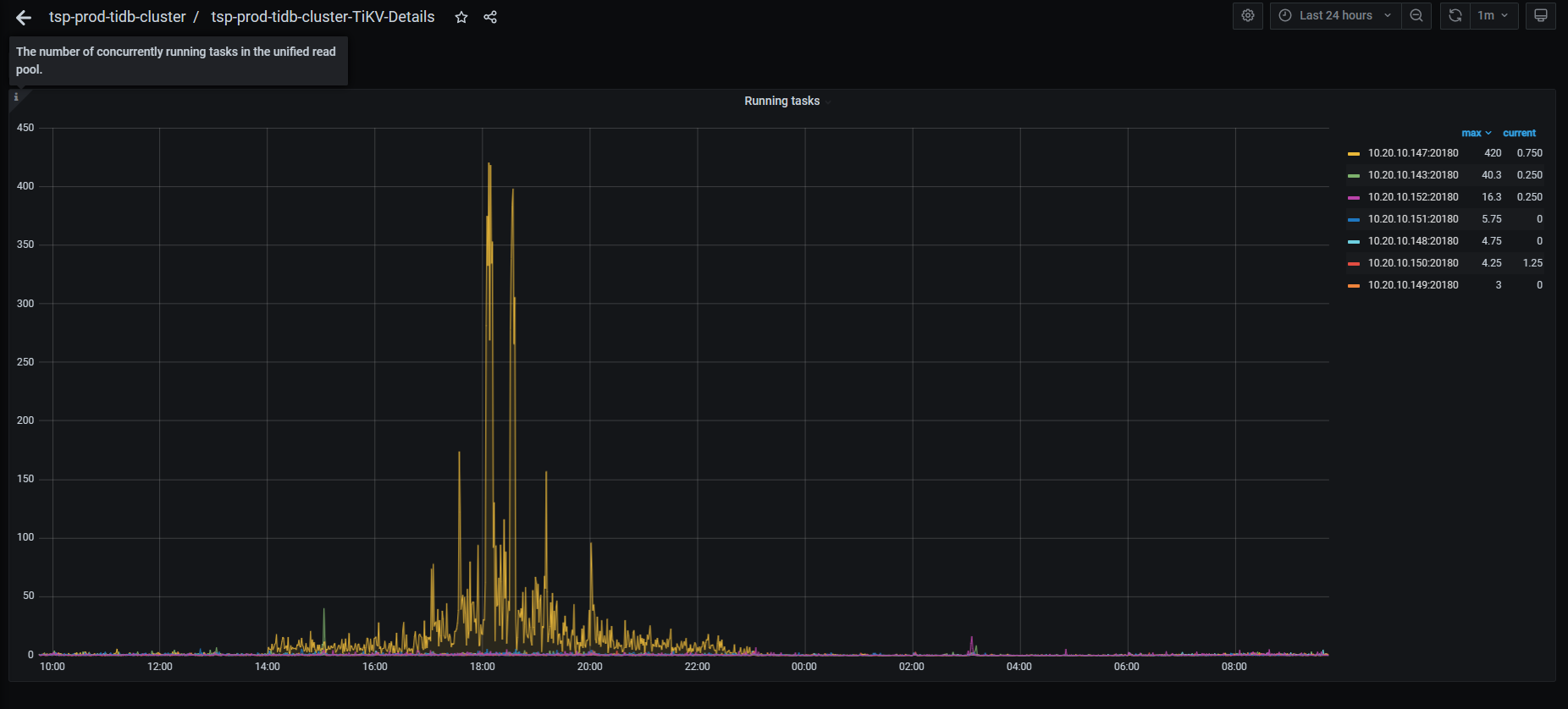
那还是读的问题, Unified Read Pool的中的并发运行的任务数量
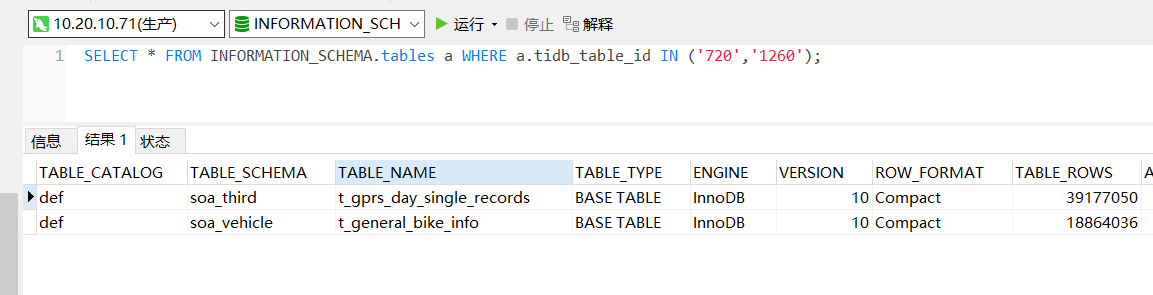
看一下这两个表 SELECT * FROM INFORMATION_SCHEMA.tables a WHERE a.tidb_table_id IN (‘720’,‘1260’);对应时间段的sql
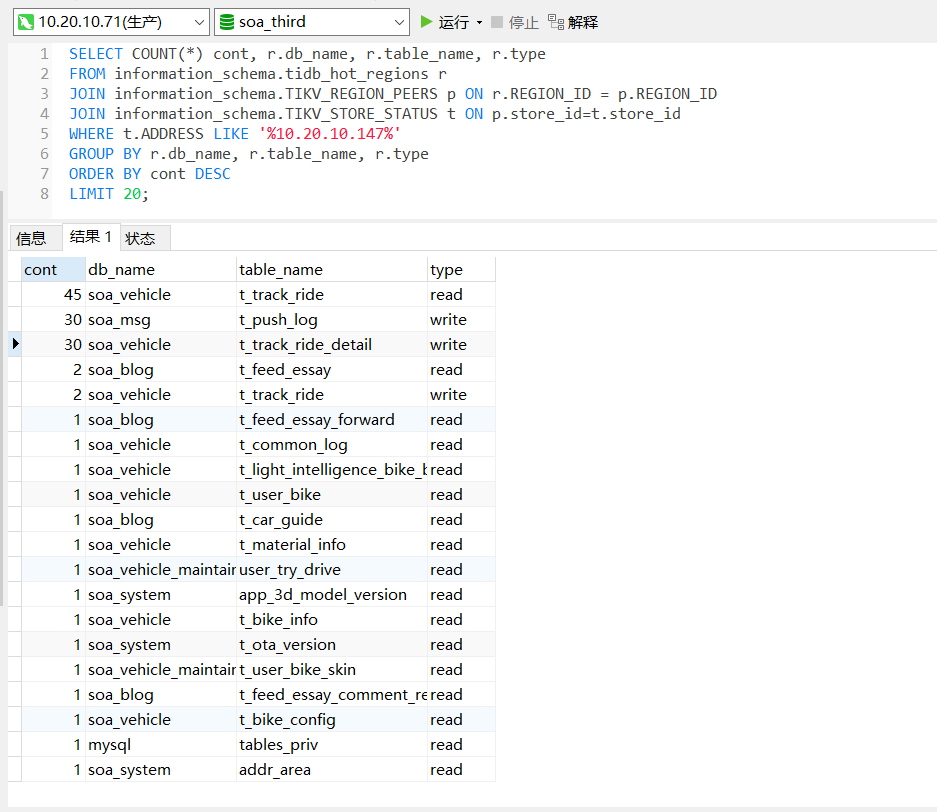
SELECT COUNT(), r.db_name, r.table_name, r.type
FROM information_schema.tidb_hot_regions r
JOIN information_schema.TIKV_REGION_PEERS p ON r.REGION_ID = p.REGION_ID
JOIN information_schema.TIKV_STORE_STATUS t ON p.store_id=t.store_id
WHERE t.ADDRESS LIKE ‘%10.20.10.147%’
GROUP BY r.db_name, r.table_name, r.type
ORDER BY COUNT() DESC
LIMIT 20;
看一下热点里面有上面那两个表吗?
那看下热点都集中在147机器上吗?
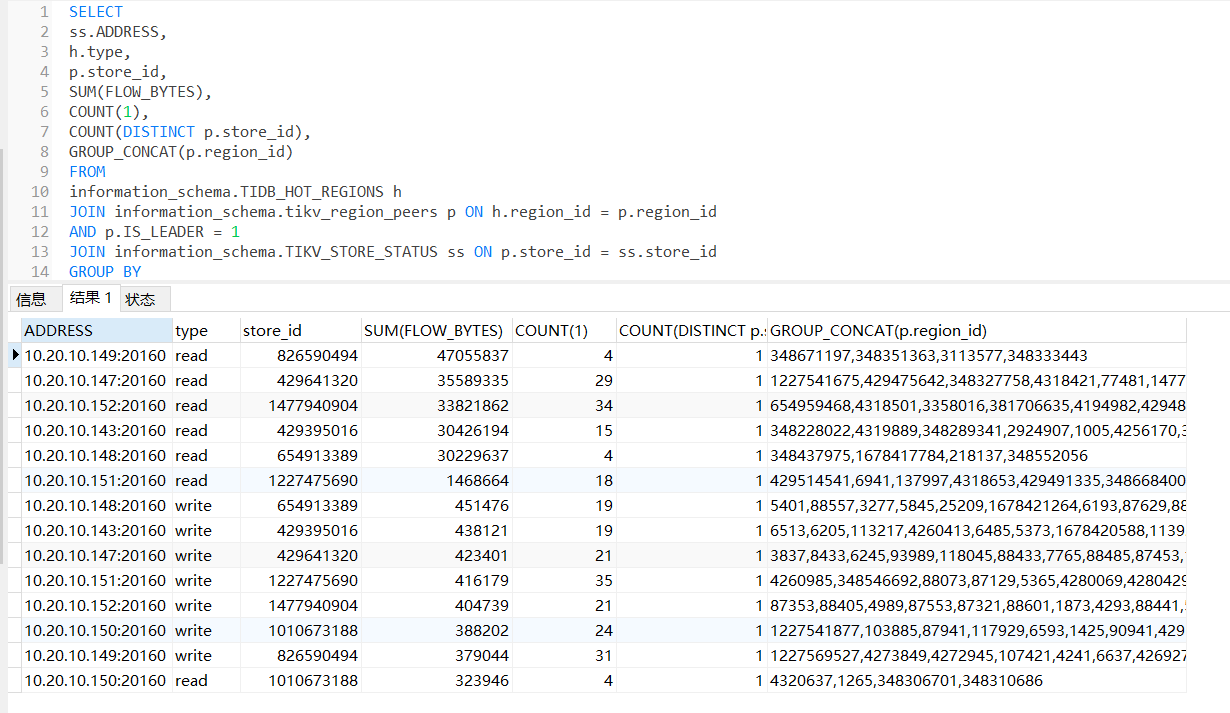
SELECT
ss.ADDRESS,
h.type,
p.store_id,
SUM(FLOW_BYTES),
COUNT(1),
COUNT(DISTINCT p.store_id),
GROUP_CONCAT(p.region_id)
FROM
information_schema.TIDB_HOT_REGIONS h
JOIN information_schema.tikv_region_peers p ON h.region_id = p.region_id
AND p.IS_LEADER = 1
JOIN information_schema.TIKV_STORE_STATUS ss ON p.store_id = ss.store_id
GROUP BY
h.type,
p.store_id,
ss.ADDRESS
ORDER BY
SUM(FLOW_BYTES) DESC;
今天下午2点监控下