看下你那个tikv-detail 下GC几个监控面板 时间长点
compact 释放空间那是针对drop和truncate操作,detele后compact 不释放空间,只是插入新数据能复用原来的region了
对于delete来说,这个操作基本没意义
插入要不用batch,要不就拆分sql一次一部分数据,insert into…select 非常吃内存,很容易oom
人家是delete 你让人insert。
学习下 GC 和 gc in compaction filter ,另外从哪里看的复用原来的region 这个说法
https://docs.pingcap.com/zh/tidb/stable/garbage-collection-overview
https://docs.pingcap.com/zh/tidb/stable/garbage-collection-configuration#gc-in-compaction-filter-机制

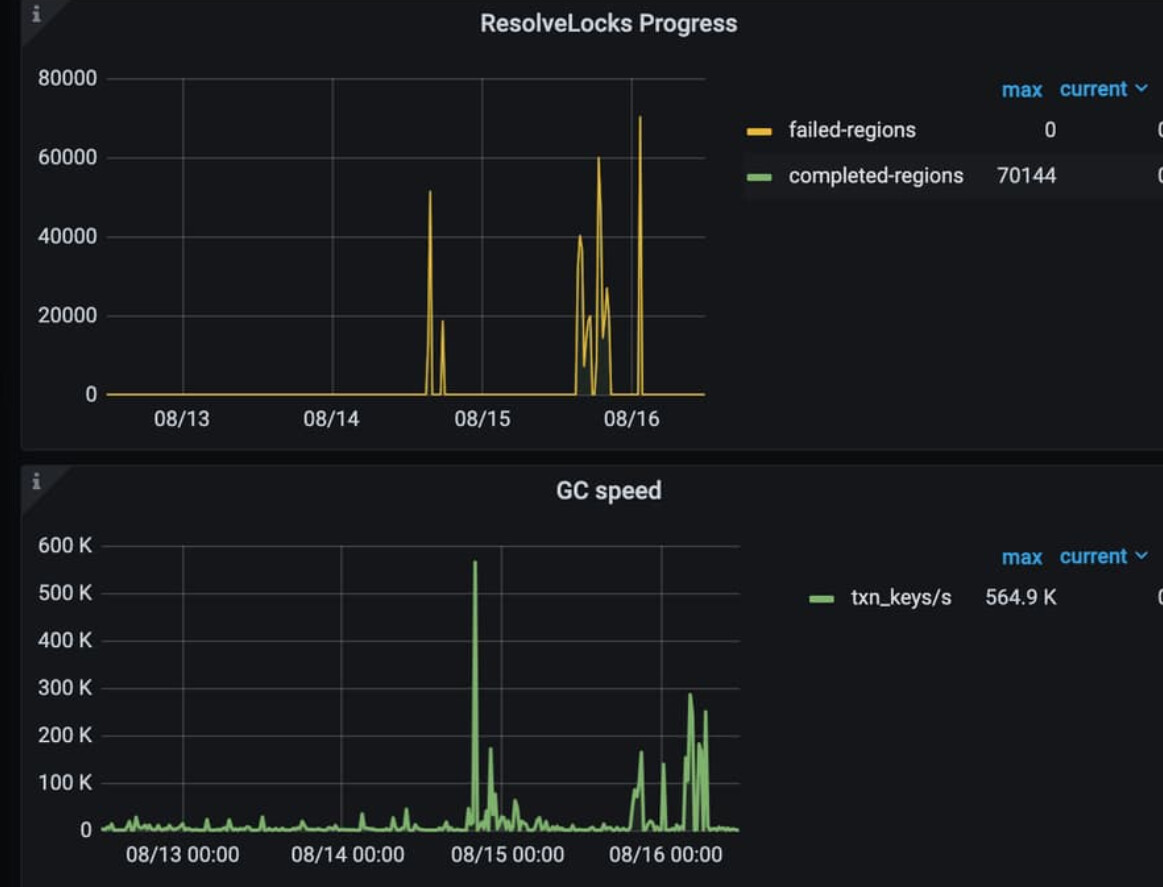
看这个截图你的gc是正常进行的,以下几个建议前面也说过
1、 tidb 有 非事务DML 根据指定的列和行数分批次DML,串行,这个和前面执行delelete sql是不一样的,没有大量的mvcc版本读取,性能比较稳定,你的版本是6.5.1可以用这个。
2. gc in compaction filter后 ,mvcc版本的数据gc是随着compact进行的,过来safepoint interval后看不到马上有GC
3. region合并时有阈值条件的,
max-merge-region-keys max-merge-region-size 达到这个值后相邻的region才会合并,向右合并,不相邻的合并不了,哪怕没数据,另外如果有tiflash ,也会影响合并。delete后虽然有用数据低于这个值,但是还有mvcc的数据在里面 也要算上的4. lsm tree 收缩空间 就靠compact,compact会清理rocksdb 内标记tombstone的数据(GC后的),有些数据在最底层光上层的compact 是清理不掉的,允许的话还是做手动compact(可以看下面测试):
tikv-ctl --host 10.172.65.156:20161 compact -c write -d kv --bottommost force 还有default cf
1 个赞
感谢解答
1:昨天已经按照你说的非事务dml进行删除了,执行的非常稳定,数据已经删完了
2:我现在手动compact 但是命令行直接卡在这没任何反应,这是命令打错了还是啥,另外–db用不了,在6.5.1这个版本好像只能用-d
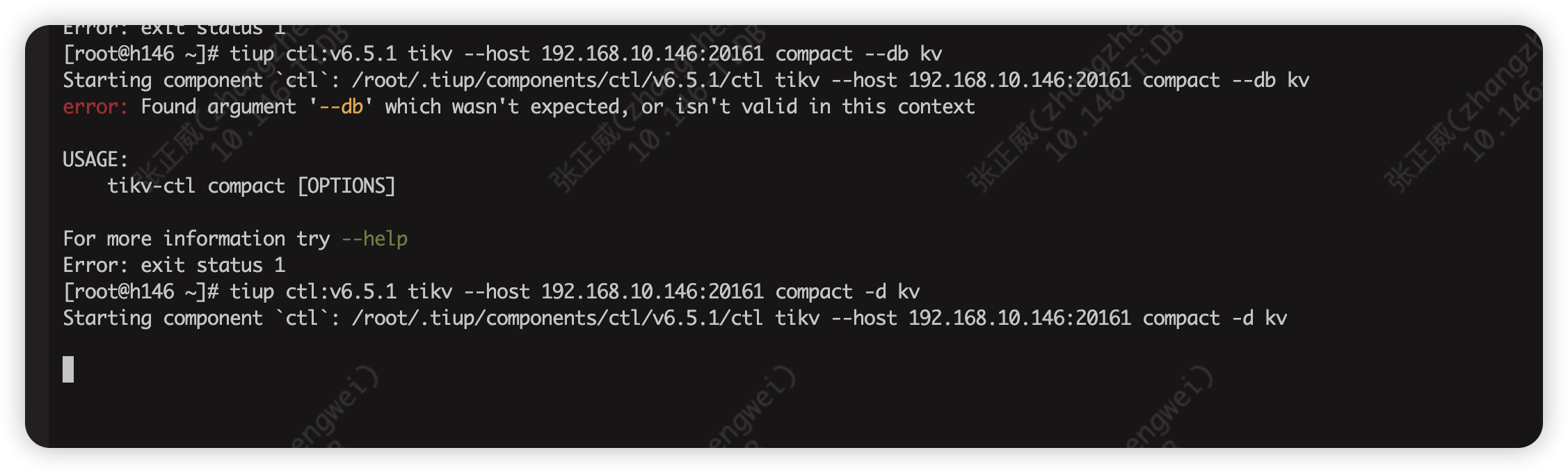
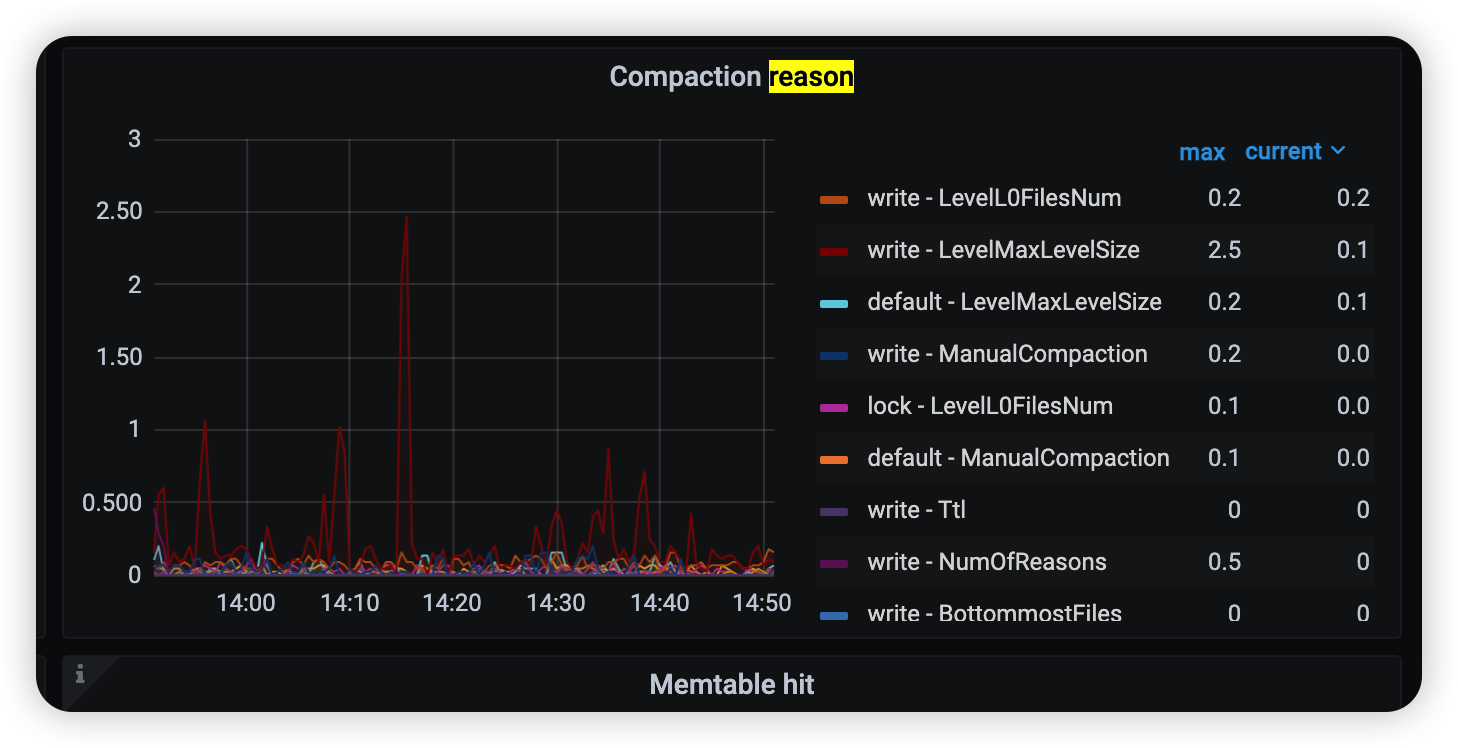
参数不同可能是版本差异问题,业务不重要啊白天操作。 这不是卡住了 手动compact 耗时较长,可以看下tikv -detail → compaction reason 和其他compaction相关的监控
有办法停止吗 ctrl+c好像没用
或者不行的话我直接强制下线这个节点?
ctrl+c后 什么都没操作的情况下 过了十来分钟磁盘占用下降了 现在恢复正常,但是看compaction监控好像没发生什么变化,这是被停止了没执行下去么
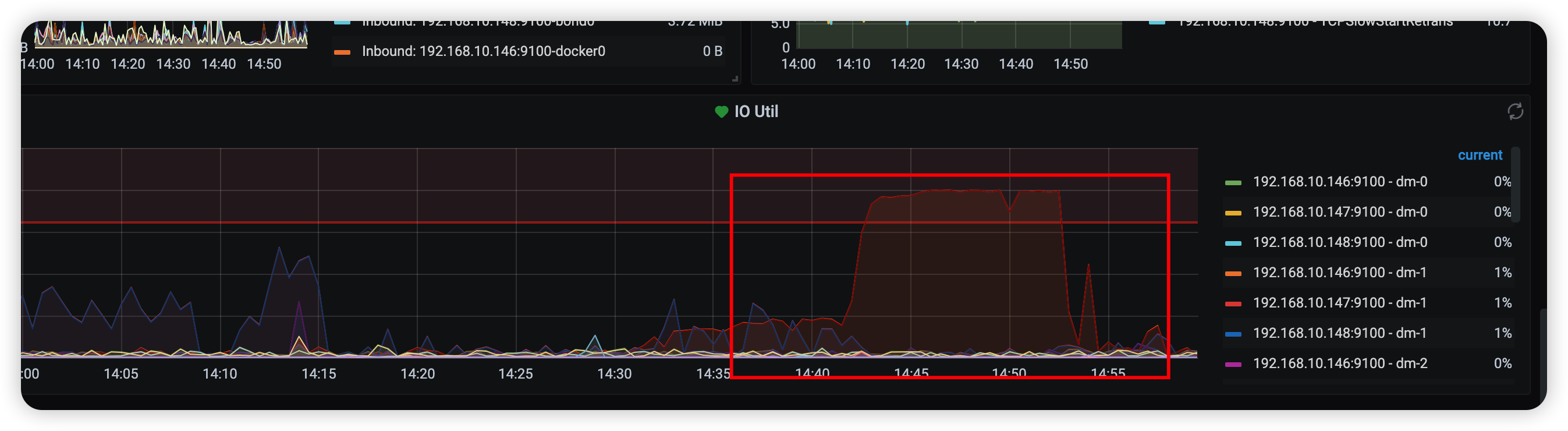
inserti into 回复的这个回答

gc你贴的问题解决不了任何问题,要不你建个大点表,detele删除所有数据看看gc到最后到底是region少了还是磁盘占用少了,只有drop truncate等操作才能真的回收空间
命令还在吗 直接kill吧 ,另外手动compact时得加下 --bottommost force 要不可能没效果
我上面的回答编辑了下,贴了下图 现在恢复正常了
不太敢搞了 因为是从库 如果小影响的话无所谓的 结果差点集群就崩了 这东西就算放晚上也不好弄吧
直接磁盘100% sql的执行直接干到了30多s 如果加线程限制会有效果么
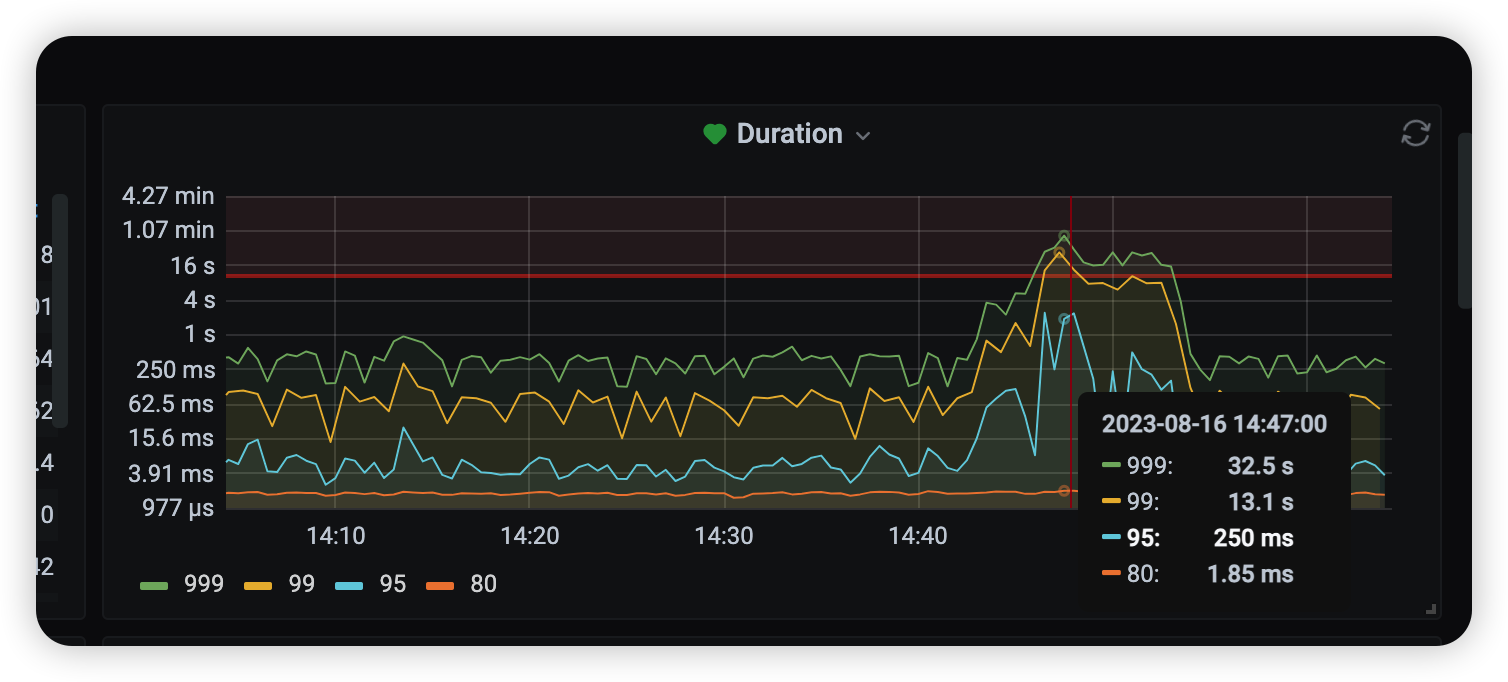
–threads 可以控制线程数,还有个限速参数 rocksdb.rate-bytes-per-sec


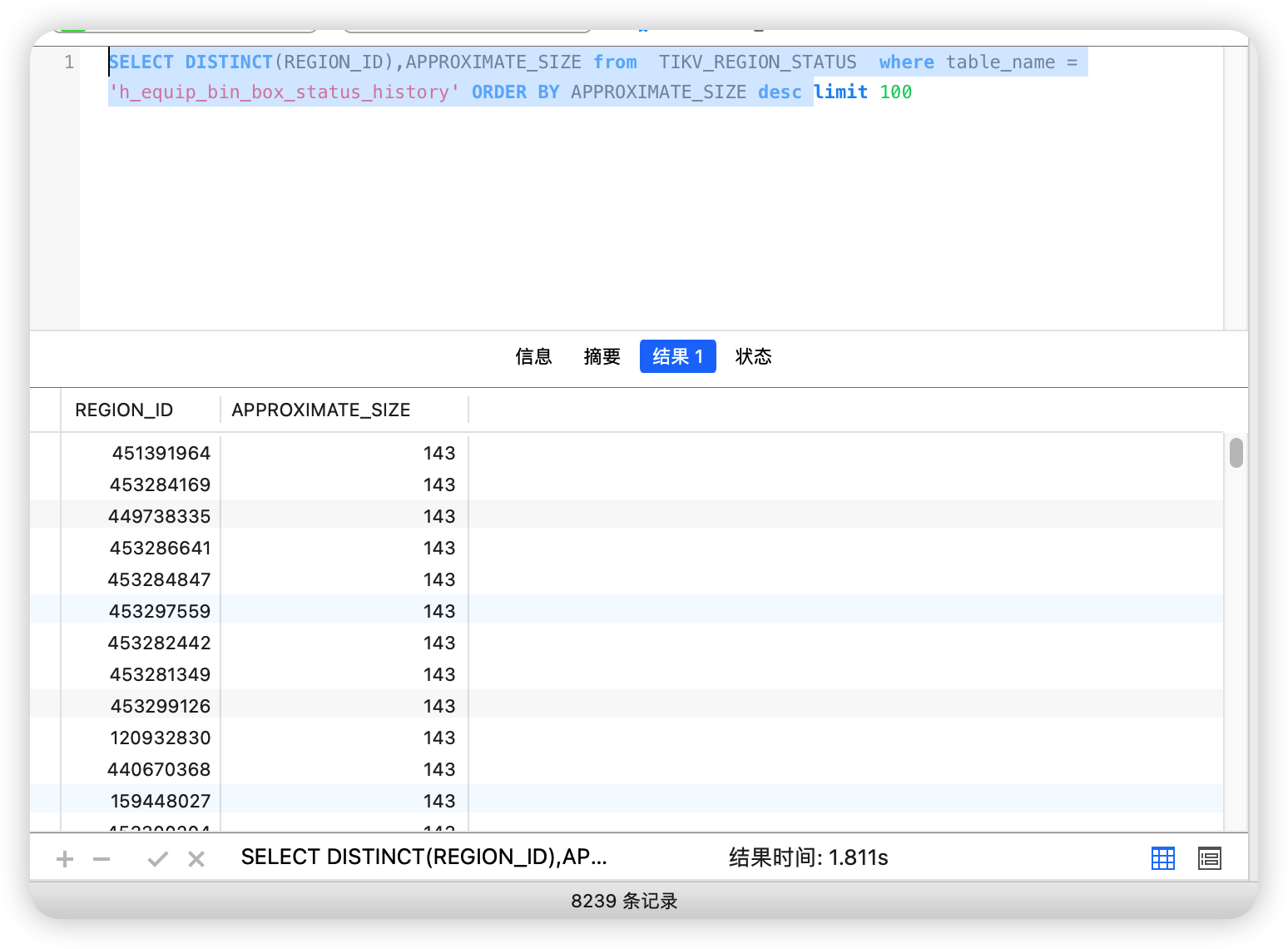
补充一下,compact可以按region来做,根据tikv_region_status获取region列表然后调用compact -r region_id 实现按表的compact,测试下来资源消耗要小于整tikv compact
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。