需求反馈 请清晰准确地描述问题场景、需求行为及背景信息,更有利于产品同学及时跟进需求
【需求涉及的问题场景】
TiDB 在运行过程中,可能会报这样、那样的错误。而错误信息仅仅是一段笼统的描述文字。可能官方开发人员根据报错信息,一眼就能定位主要的问题原因。但是,使用者看着笼统的错误信息,就很蒙逼,无从下手。
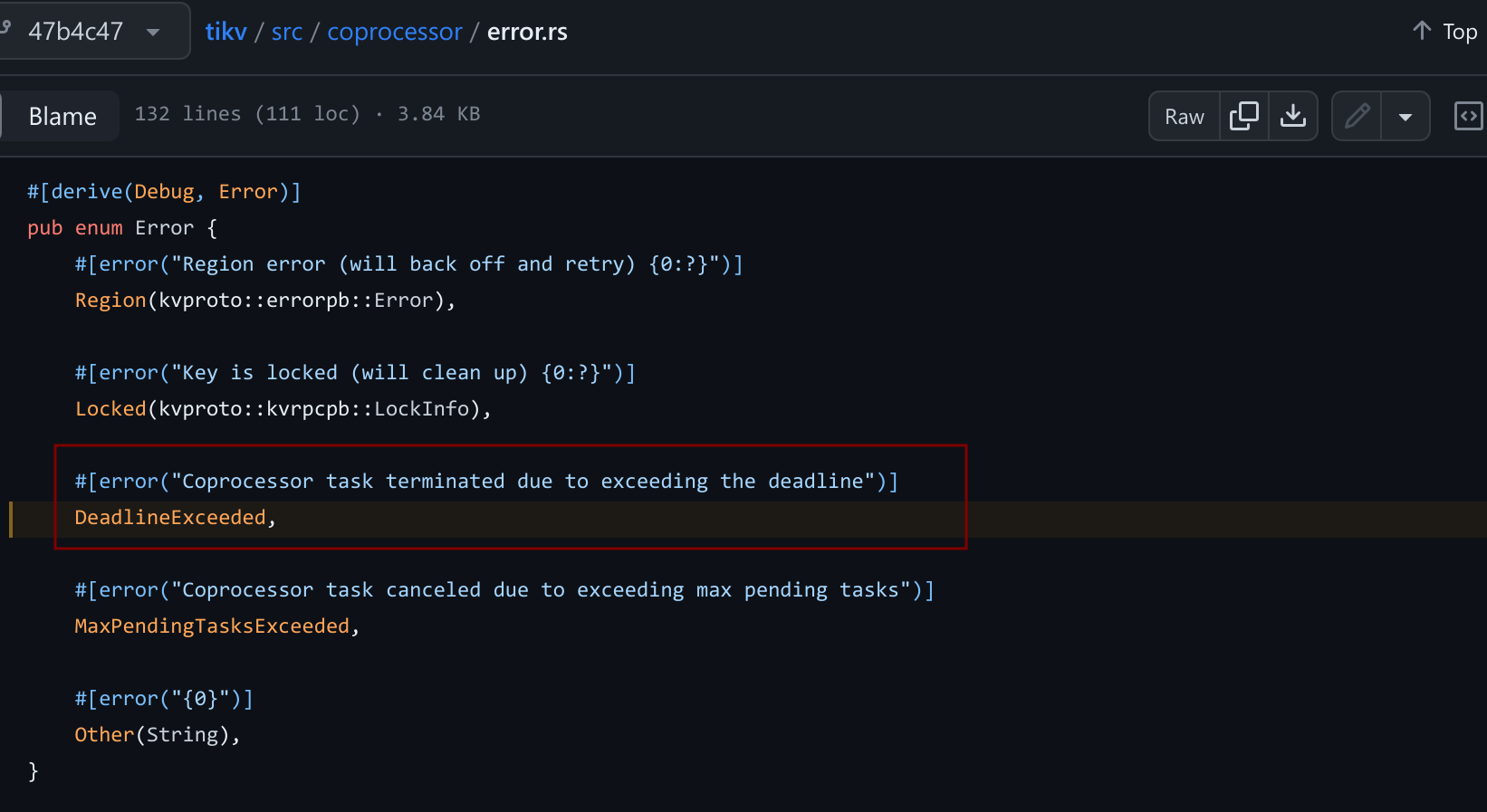
比如,这几天做生产环境的BR恢复测试时,就遇到报错 other error: Coprocessor task terminated due to exceeding the deadline。看着一脸蒙,这个other error 是个什么错误?是不是类似于 Python 中异常的基类(Exception),所有错误都可以归类为 other error?这个 deadline(最后期限)又是个啥?印象里,官方的 TiKV 视频教程中,也没提过这个 deadline 啊?和磁盘的调度队列 deadline、my-deadline 是否有关系?翻官方 github,找到关于 Coprocessor task terminated due to exceeding the deadline 的定义。