【 TiDB 使用环境】生产环境 /测试/
【 TiDB 版本】TiDB v5.3.0、BR v5.3.0
【复现路径】
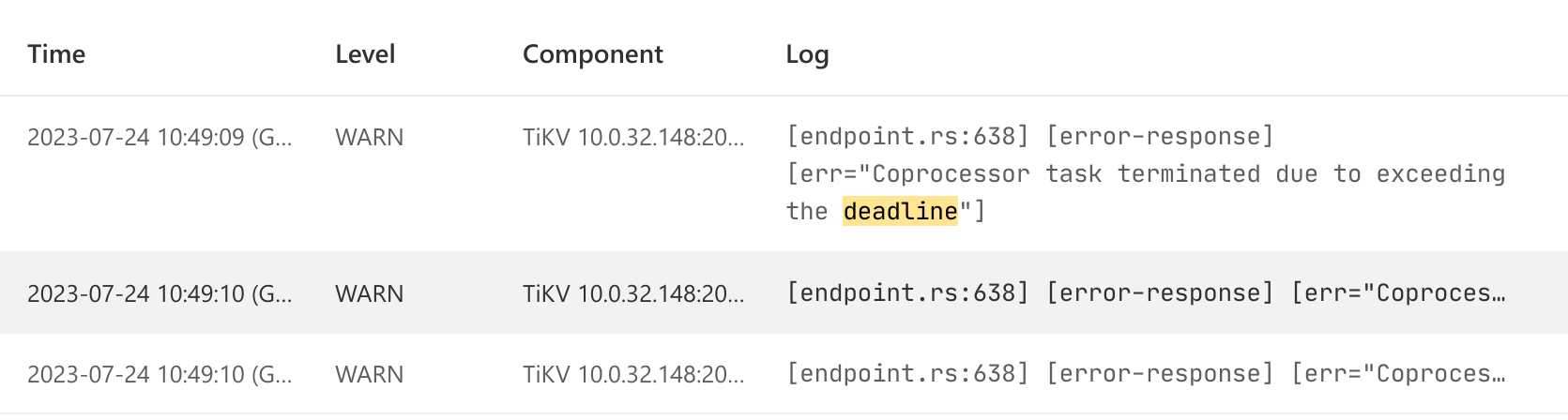
将生产环境的全量备份集做恢复测试时,报错 Coprocessor task terminated due to exceeding the deadline。
【遇到的问题:问题现象及影响】
Full restore <----------------------------------------------------------------------------------------------------------------------------------..............................................> 73.56%
Full restore <-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------> 100.00%
[2023/07/24 11:05:53.139 +08:00] [INFO] [collector.go:65] ["Full restore failed summary"] [total-ranges=46104] [ranges-succeed=46104] [ranges-failed=0] [restore-checksum=5h11m42.859911719s] [split-region=1m47.011917972s] [restore-ranges=30688]
Error: other error: Coprocessor task terminated due to exceeding the deadline
["Full restore failed summary"] [total-ranges=46104] [ranges-succeed=46104] [ranges-failed=0] [restore-checksum=5h11m42.859911719s] [split-region=1m47.011917972s] [restore-ranges=30688]
[2023/07/24 11:05:53.139 +08:00] [ERROR] [restore.go:34] ["failed to restore"] [error="other error: Coprocessor task terminated due to exceeding the deadline"]
【资源配置】
1、生产环境(物理机部署)
3TiDB(64C/256G)、3TiKV(64C/256G)、3PD(64C/64G)
2、测试环境(PVE 虚拟化部署)
3TiDB(4C/8G)、3TiKV(4C/8G)、3PD(4C/4G)
3、数据量
快照大小 265G。
4、执行的恢复指令
export PD_ADDR="10.0.32.145:2379"
export BAKDIR="/tidb-bak/20230716"
nohup tiup br restore full --pd "${PD_ADDR}" --storage "local://${BAKDIR}" --ratelimit 64 --log-file restorefull_`date +%Y%m%d`.log &
【附件:截图/日志/监控】
dashboard 中关于 TiKV 的报错日至如下: