看你的查询,表数据是9000w,走索引是6w,那用索引走tikv也是有意义的。
我理解tiflash是你实在是加不上索引的情况下用这个。
你自己评估吧,如果感觉走tiflash更快,那就走tiflash,毕竟tiflash闲着也是闲着,能分担些tikv的压力也好。
看你的查询,表数据是9000w,走索引是6w,那用索引走tikv也是有意义的。
我理解tiflash是你实在是加不上索引的情况下用这个。
你自己评估吧,如果感觉走tiflash更快,那就走tiflash,毕竟tiflash闲着也是闲着,能分担些tikv的压力也好。
走tiflash了 肯定CPU会涨
既然tiflash cpu飙起来了,刚才我提到的增加batch就不需要调整了。
我现在走tiflash的话,这个sql查询需要11秒多,这个效率如果想要再提升有没有什么解决办法?
但是现在走tiflash也要11秒才可以检索出来,这个还有优化的办法吗?
explain analyze 的完整结果上传下
我感觉你还不如走tikv,然后优化优化索引,让筛选后的数据量更少一些。
写入要求不高的表,可以针对where条件加联合索引,速度会很快
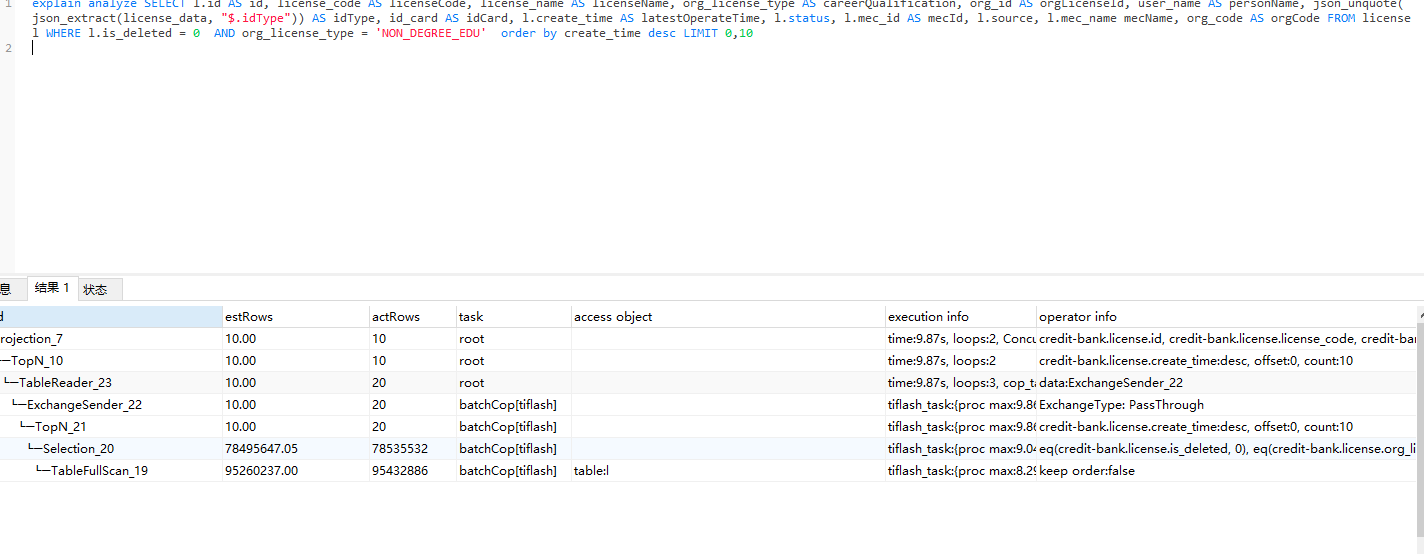
执行计划能复制下来吗 ,截图看不全
| Projection_7 | 10.00 | 10 | root | time:10s, loops:2, Concurrency:OFF | credit-bank.license.id, credit-bank.license.license_code, credit-bank.license.license_name, credit-bank.license.org_license_type, credit-bank.license.org_id, credit-bank.license.user_name, json_unquote(cast(json_extract(credit-bank.license.license_data, $.idType), var_string(16777216)))->Column#37, credit-bank.license.id_card, credit-bank.license.create_time, credit-bank.license.status, credit-bank.license.mec_id, credit-bank.license.source, credit-bank.license.mec_name, credit-bank.license.org_code | 18.7 KB | N/A | |
|---|---|---|---|---|---|---|---|---|
| └─TopN_10 | 10.00 | 10 | root | time:10s, loops:2 | credit-bank.license.create_time:desc, offset:0, count:10 | 13.2 KB | N/A | |
| └─TableReader_23 | 10.00 | 20 | root | time:10s, loops:3, cop_task: {num: 2, max: 0s, min: 0s, avg: 0s, p95: 0s, copr_cache_hit_ratio: 0.00} | data:ExchangeSender_22 | N/A | N/A | |
| └─ExchangeSender_22 | 10.00 | 20 | batchCop[tiflash] | tiflash_task:{proc max:10s, min:9.88s, p80:10s, p95:10s, iters:2, tasks:2, threads:10} | ExchangeType: PassThrough | N/A | N/A | |
| └─TopN_21 | 10.00 | 20 | batchCop[tiflash] | tiflash_task:{proc max:10s, min:9.88s, p80:10s, p95:10s, iters:2, tasks:2, threads:2} | credit-bank.license.create_time:desc, offset:0, count:10 | N/A | N/A | |
| └─Selection_20 | 78495647.05 | 78535533 | batchCop[tiflash] | tiflash_task:{proc max:9.2s, min:8.82s, p80:9.2s, p95:9.2s, iters:1529, tasks:2, threads:10} | eq(credit-bank.license.is_deleted, 0), eq(credit-bank.license.org_license_type, NON_DEGREE_EDU) | N/A | N/A | |
| └─TableFullScan_19 | 95260237.00 | 95432887 | batchCop[tiflash] | table:l | tiflash_task:{proc max:8.37s, min:7.96s, p80:8.37s, p95:8.37s, iters:1626, tasks:2, threads:10} | keep order:false | N/A | N/A |
show variables like ‘%concurrency%’;
| innodb_commit_concurrency | 0 |
|---|---|
| innodb_concurrency_tickets | 5000 |
| innodb_thread_concurrency | 0 |
| thread_concurrency | 10 |
| tidb_build_stats_concurrency | 4 |
| tidb_checksum_table_concurrency | 4 |
| tidb_distsql_scan_concurrency | 15 |
| tidb_executor_concurrency | 5 |
| tidb_gc_concurrency | -1 |
| tidb_hash_join_concurrency | -1 |
| tidb_hashagg_final_concurrency | -1 |
| tidb_hashagg_partial_concurrency | -1 |
| tidb_index_lookup_concurrency | -1 |
| tidb_index_lookup_join_concurrency | -1 |
| tidb_index_serial_scan_concurrency | 1 |
| tidb_merge_join_concurrency | 1 |
| tidb_opt_concurrency_factor | 3 |
| tidb_opt_tiflash_concurrency_factor | 24 |
| tidb_projection_concurrency | -1 |
| tidb_streamagg_concurrency | 1 |
| tidb_window_concurrency | -1 |
目前能想到的扩CPU 换更快的盘
扩cpu增加tiflash节点可以吗?
理论上节点数增加能提升处理能力
你这sql才返回2条数据,走啥tiflash啊。加个组合索引就完事了
mec_id,create_time
看你发的走索引也是create_time列的索引,看你的结果猜测应该根据mec_id列能过滤完数据应该就几条。
你根据mec_id条件count下看看有多少行,这列是不是没索引,建个索引就完了。
弄个临时表,order by在临时表上做。