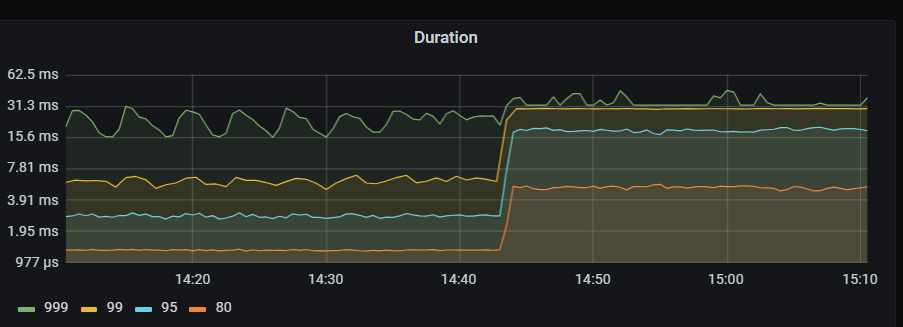
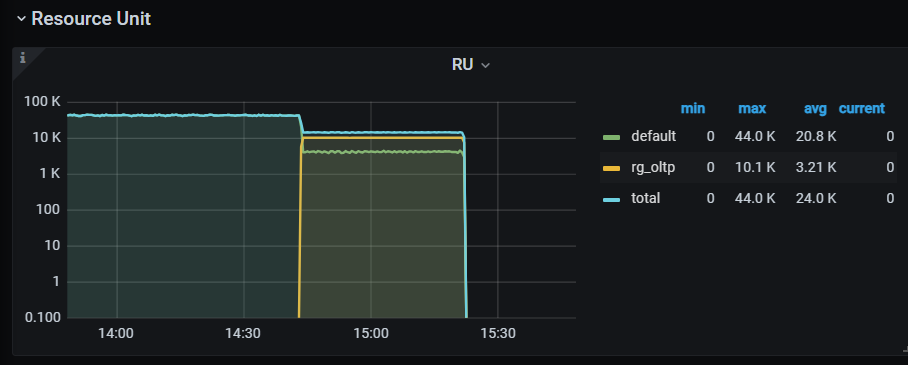
使用sysbench 32线程oltp_read_write测试,当这种资源组后 duration明显增高。如何能够排查出来是资源组导致的延迟增高,目前resource control监控还是一些总的 类似吞吐量的监控。 SQL 执行时间里也缺少等待资源组调度的时间,trace 里是不是也需要加入相关信息,比如像oracle上有明显的resmgr:cpu quantum 资源组相关等待事件。
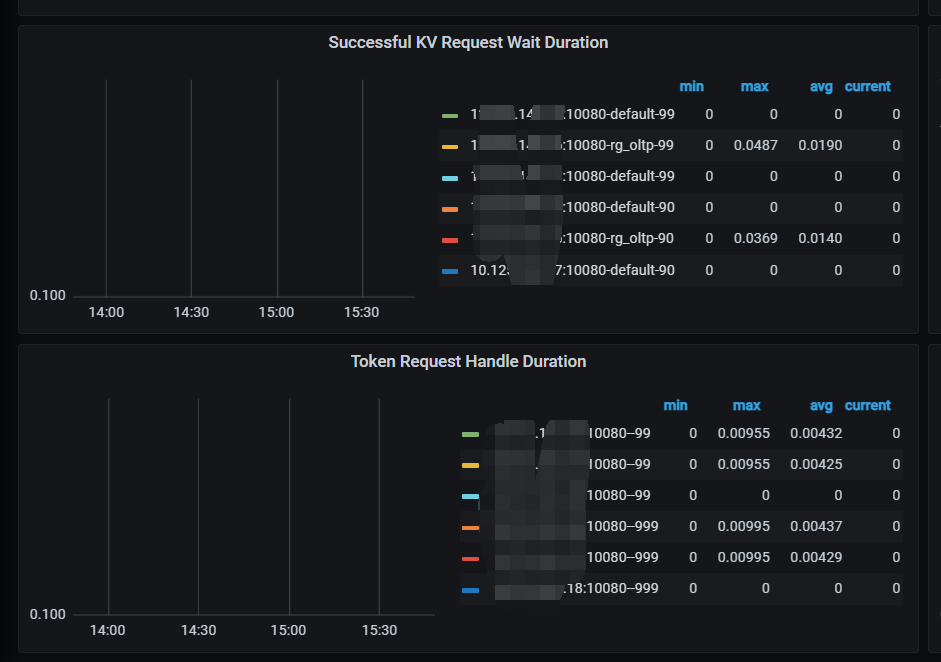
在 Resource control 面板中,Client 栏下有 Successful KV Request Wait Duration
这个监控的单位是秒吧,前面截图贴了都是为0 没有曲线,看avg有0.019,我又把ru值降低到100后这个值比较明显了。感觉类似指标应该也增加到 tidb 监控、SQL执行时间统计里,能从上向下发现问题。 -
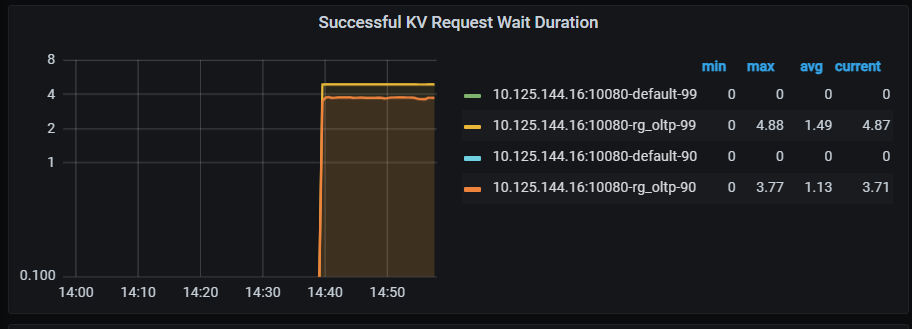
我们后续换一下单位。
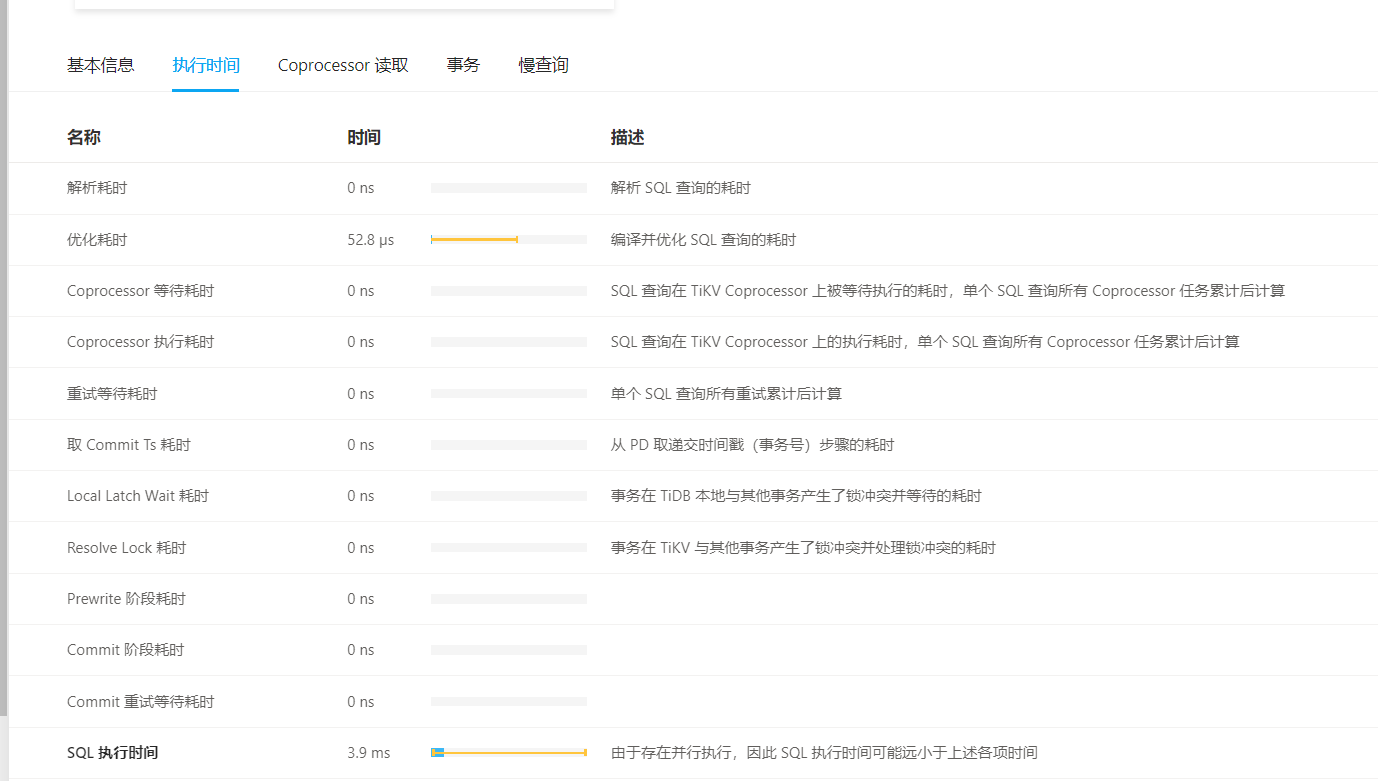
未来会将这里的等待时间 trace 一下,但是这个指标以 query 维度展示的话,需要明确一下定义和统计逻辑。
我的意思有2 方面 。1、 再tidb 监控页面 比如kv request那里或者哪能直接看到这些指标,可以快速定位是RU带来的问题 2、 再SQL执行的统计里也能展示出因为RU导致的时间消耗。或者你们已经有其他更好的方式也行。
仿佛目前在 TiDB 的监控页面中,确实没有直接显示资源组导致的延迟信息