你那些服务器上不存在的,丢失的。就是有问题的。找出这些文件对应region。不过你这奇怪啊,每个节点上都有问题。会不会没有可用的副本。只能试试看吧!

你这应该是磁盘有问题了,试试有损恢复吧。。。
专栏 - TiDB损坏多副本之有损恢复处理方法 | TiDB 社区
5个节点的盘同时出问题的可能性基本没有吧。。
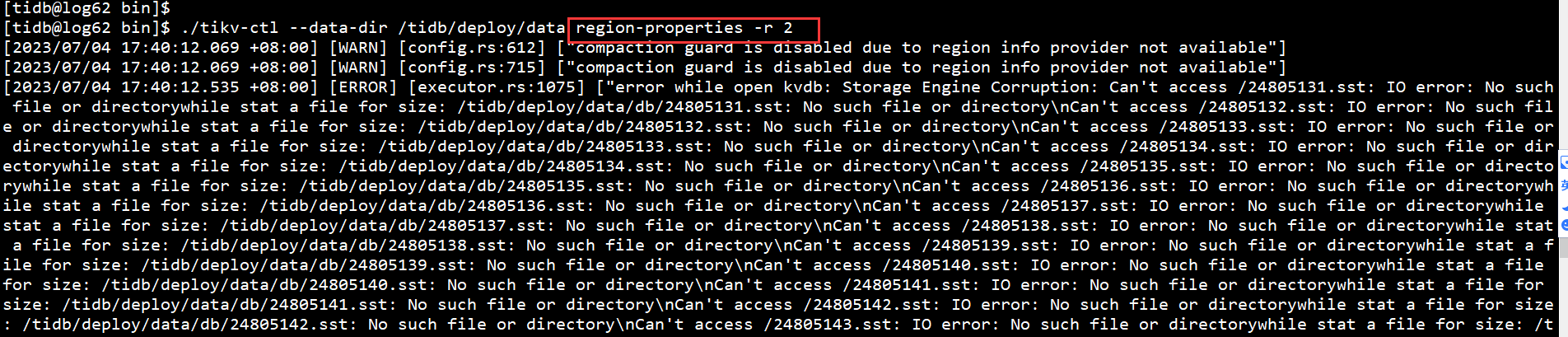
你所有节点启动都报sst找不到吗?
对所有节点
你原来有多少个节点呢!
检查一下防火墙吧,我遇到过一次重启后防火墙自动开启了,然后集体罢工了~
正常。
这个问题可能是由于硬件问题导致的,可以尝试以下步骤来解决:
-
首先,检查该节点的硬件是否正常,例如磁盘是否正常,网络是否正常等等。如果硬件有问题,需要先解决硬件问题。
-
如果硬件正常,可以尝试重启整个集群,看看是否可以解决问题。可以使用以下命令重启整个集群:
tiup cluster restart <cluster-name>其中,
<cluster-name>是你的 TiDB 集群的名称。 -
如果重启集群后仍然无法解决问题,可以尝试清理掉故障节点上的 region peer,然后重启 PD 集群和正常的 TiKV 节点。具体步骤如下:
-
清理掉故障节点上的 region peer:
tiup cluster exec <cluster-name> --command="pd-ctl -u <pd-address> operator add remove-down-peer <region-id> <store-id>"其中,
<pd-address>是 PD 的地址,<region-id>是要清理的 region 的 ID,<store-id>是故障节点的 ID。 -
重启 PD 集群:
tiup cluster restart <cluster-name> -R pd -
启动正常的 TiKV 节点:
tiup cluster start <cluster-name> -N <normal-tikv-address>其中,
<normal-tikv-address>是正常的 TiKV 节点的地址。
如果以上步骤都无法解决问题,可以尝试联系 TiDB 官方技术支持。
-
用tikv-ctl ldb -db=data/db repair修复试试
如果是生产 付费找官方
同时所有tikv出问题不应该吧
应该还是存储 文件系统上有些问题
官方回复:你必须用商业版,才能给你看。
不知道哪的问题,这个现象在我们迁移集群时又出现一次。批量写数据时,突然就sst丢失了。服务及服务器都没重启过。可能大约的确是5.4.3版本的bug。
开源版本也提供商业支持吧!