【 TiDB 使用环境】测试
【 TiDB 版本】
从V6.1.0升级到V6.5.0,再升级到V7.1.0
【复现路径】
一个3kw的表加索引测试。
[root@127.0.0.1][tpcc][08:40:23]> select version();
+--------------------+
| version() |
+--------------------+
| 5.7.25-TiDB-v7.1.0 |
+--------------------+
1 row in set (0.00 sec)
[root@127.0.0.1][tpcc][08:40:42]> select count(0) from tpcc.customer;
+----------+
| count(0) |
+----------+
| 30000000 |
+----------+
1 row in set (4.00 sec)
[root@127.0.0.1][tpcc][08:40:55]> set global tidb_ddl_reorg_worker_cnt=4;
Query OK, 0 rows affected (0.04 sec)
[root@127.0.0.1][tpcc][08:41:20]> show variables like 'tidb_ddl_%';
+--------------------------------+--------------+
| Variable_name | Value |
+--------------------------------+--------------+
| tidb_ddl_disk_quota | 107374182400 |
| tidb_ddl_enable_fast_reorg | ON |
| tidb_ddl_error_count_limit | 512 |
| tidb_ddl_flashback_concurrency | 64 |
| tidb_ddl_reorg_batch_size | 256 |
| tidb_ddl_reorg_priority | PRIORITY_LOW |
| tidb_ddl_reorg_worker_cnt | 4 |
+--------------------------------+--------------+
7 rows in set (0.01 sec)
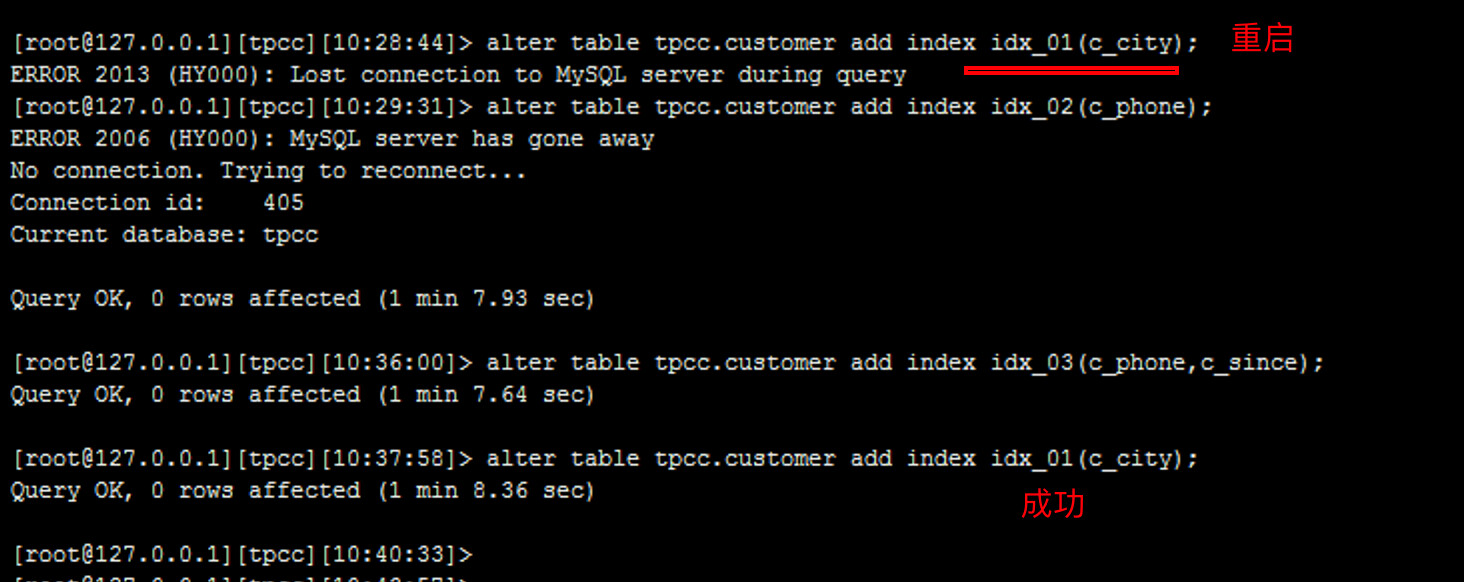
[root@127.0.0.1][tpcc][08:41:39]> alter table tpcc.customer add index idx_01(c_city);
ERROR 2013 (HY000): Lost connection to MySQL server during query
[root@127.0.0.1][tpcc][08:42:58]>
【遇到的问题:问题现象及影响】

TiDB Server不断重启,tidb_stderr.log日志如下:每次重启刷的日志都是下面这个。
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x110 pc=0x4917721]
goroutine 573 [running]:
github.com/pingcap/tidb/session.(*session).TxnInfo(0xc2f043e000)
/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/session/session.go:545 +0x141
github.com/pingcap/tidb/session.GetStartTSFromSession({0x546bfc0?, 0xc2f043e000?})
/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/session/session.go:3822 +0xce
github.com/pingcap/tidb/server.(*Server).GetInternalSessionStartTSList(0xc01ef2e480)
/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/server/server.go:960 +0x20c
github.com/pingcap/tidb/domain/infosync.(*InfoSyncer).ReportMinStartTS(0xc0002a0b40, {0x5d716a8, 0xc0006a2480})
/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/domain/infosync/info.go:802 +0x82
github.com/pingcap/tidb/domain.(*Domain).infoSyncerKeeper(0xc000d66680)
/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/domain/domain.go:671 +0x42a
github.com/pingcap/tidb/util.(*WaitGroupEnhancedWrapper).Run.func1()
/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/util/wait_group_wrapper.go:96 +0x77
created by github.com/pingcap/tidb/util.(*WaitGroupEnhancedWrapper).Run
/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/util/wait_group_wrapper.go:91 +0xcc
半小时已经重启30次了!!
【附件:截图/日志/监控】
tidb0626.log (3.4 MB)