请问 show table status from db 的返回要 10s,show table status like ‘%t1%’ 也要 10s 才能返回,这是为什么

请问这个问题有优化的思路吗?
请问 show table status from db 的返回要 10s,show table status like ‘%t1%’ 也要 10s 才能返回,这是为什么
请问这个问题有优化的思路吗?
这个问题可能是由于表的数据量过大导致的,可以考虑以下优化措施:
增加 TiDB 集群的资源,例如增加 TiDB 节点、PD 节点、TiKV 节点等,以提高整个集群的处理能力。
调整 TiDB 集群的参数,例如调整 TiDB 的连接数、调整 TiKV 的 RaftStore 和 RocksDB 参数等,以提高整个集群的性能。
对表进行分区或分片,以减少单表数据量,从而提高查询性能。可以使用 TiDB 的分区表或者分片表功能,将表按照一定的规则进行分区或分片。
对表进行归档,将历史数据归档到其他存储介质中,从而减少单表数据量,提高查询性能。
调整查询语句,优化查询计划,例如使用索引、避免全表扫描等,以提高查询性能。
需要根据具体情况进行分析和优化,建议先通过 explain 分析查询语句的执行计划,找出瓶颈所在,再进行相应的优化。
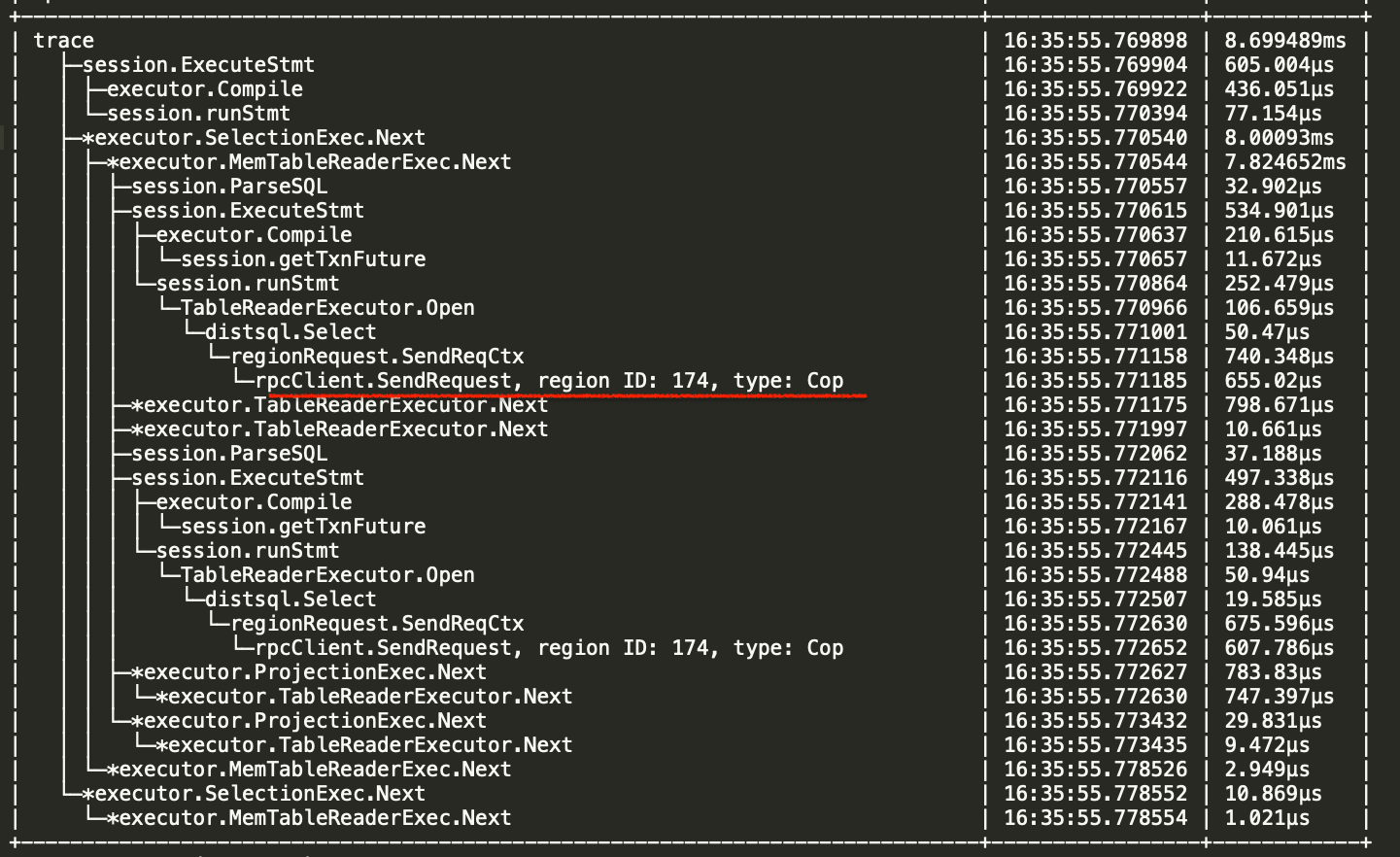
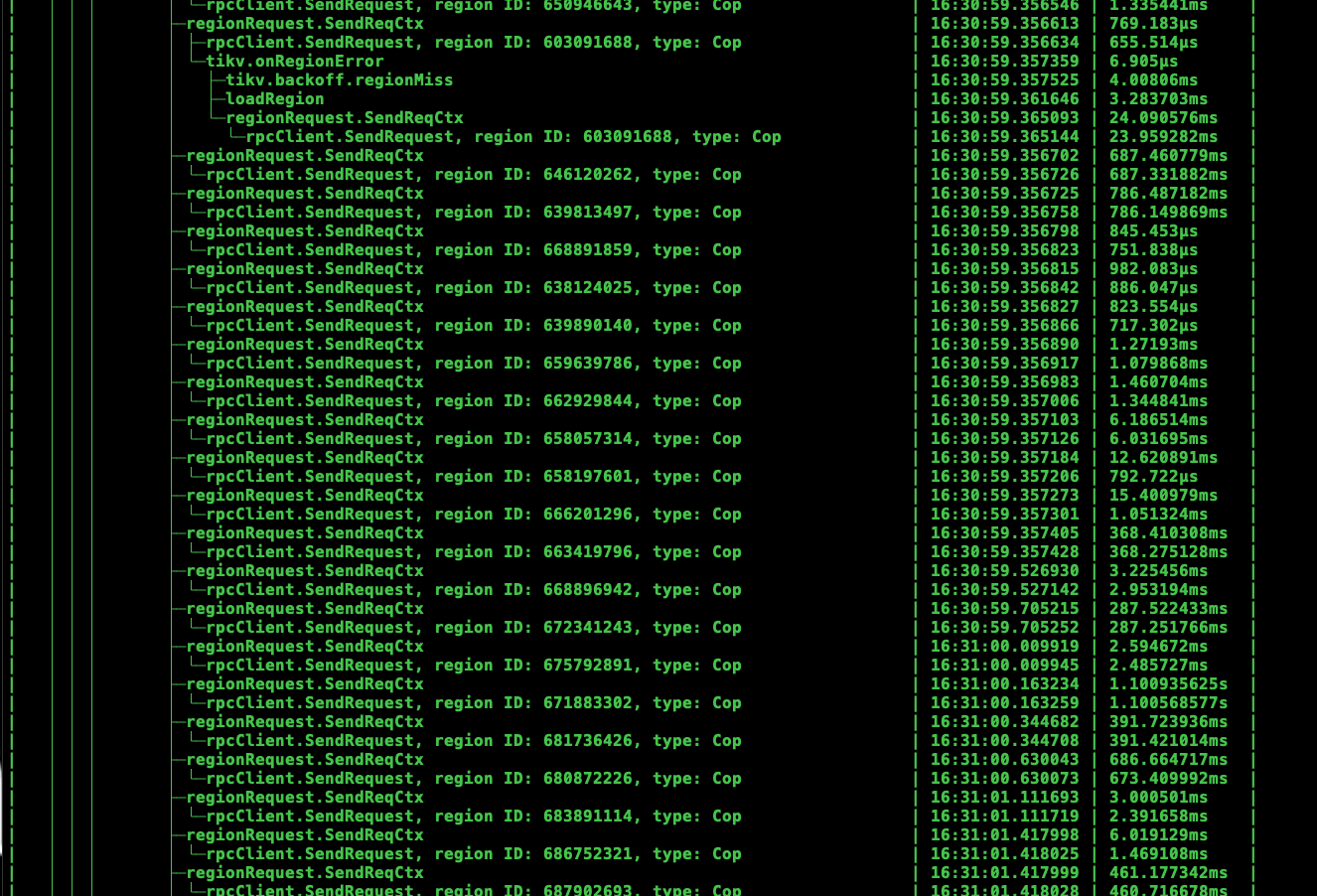
我 trace 了下 sql 发现对比了下,发现当查询 information_schema.tables 时的需要访问的 region 数非常多,下面是访问正常和不正常的截图
我有一个疑问 i_s.tables 是否放在内存中?
正常访问 i_s.tables 截图
访问慢的 i_s.tables 截图
在 TiDB 中,information_schema.tables 表是一个系统表,用于存储 TiDB 中所有表的元信息。当查询 information_schema.tables 表时,TiDB 会根据表的元信息来生成查询计划,并向相应的 region 发送 RPC 请求来获取数据。
对于您提到的访问正常和不正常的情况,可能是由于 TiDB 集群中的某些 region 出现了热点导致的。当某个 region 成为热点时,会导致该 region 上的请求量非常大,从而影响整个 TiDB 集群的性能。因此,需要及时识别和处理热点 region,以保证 TiDB 集群的稳定性和性能。
关于 information_schema.tables 表的访问逻辑,TiDB 会将该表的元信息存储在 PD 中,并在查询时从 PD 中获取元信息。具体来说,当查询 information_schema.tables 表时,TiDB 会向 PD 发送请求,获取所有表的元信息,并根据查询条件生成查询计划。然后,TiDB 会向相应的 region 发送 RPC 请求,获取符合条件的数据,并将其返回给客户端。
需要注意的是,由于 information_schema.tables 表的元信息存储在 PD 中,因此在查询该表时,可能会对 PD 造成一定的负载。为了减轻 PD 的负载,可以考虑使用缓存来缓存 information_schema.tables 表的元信息,从而减少对 PD 的访问次数。
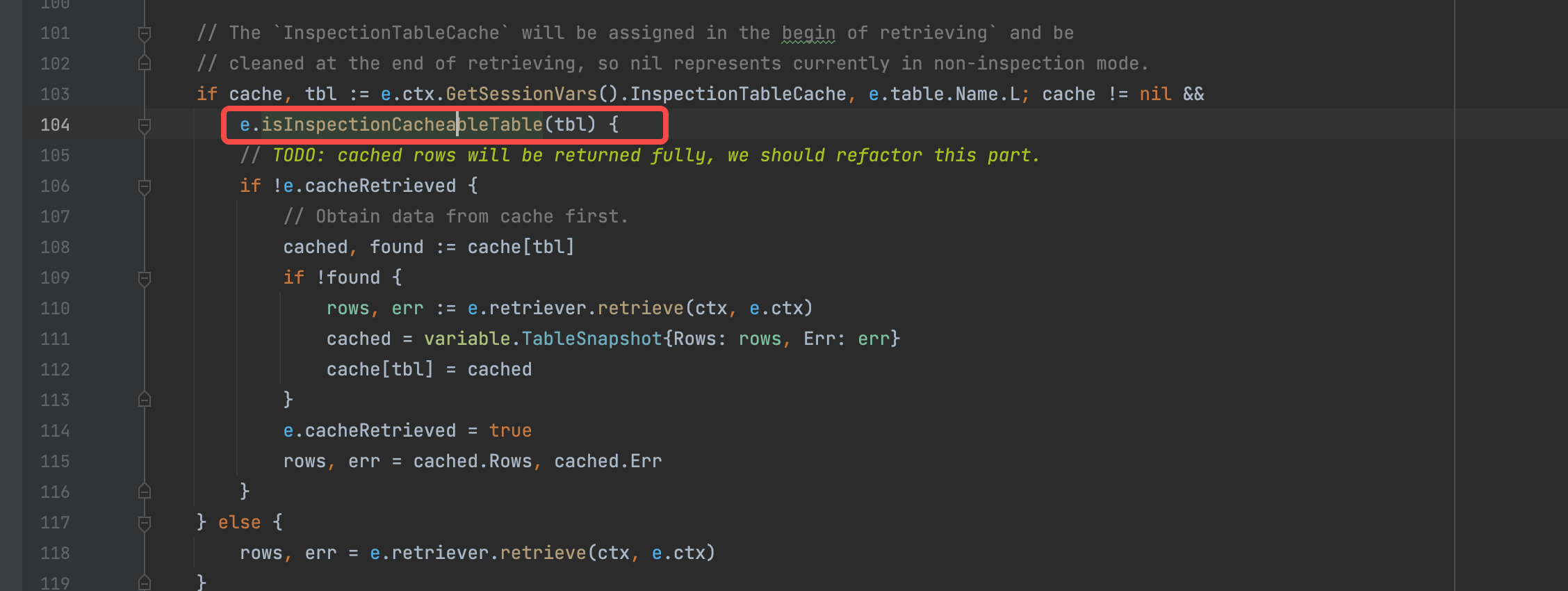
麻烦确认下这段代码是否要遍历所有 TiDB 节点上的 cache 信息,如果 TiDB 的计算节点过多是否会引起查询元信息慢的现象?
if cache, tbl := e.ctx.GetSessionVars().InspectionTableCache, e.table.Name.L; cache != nil &&
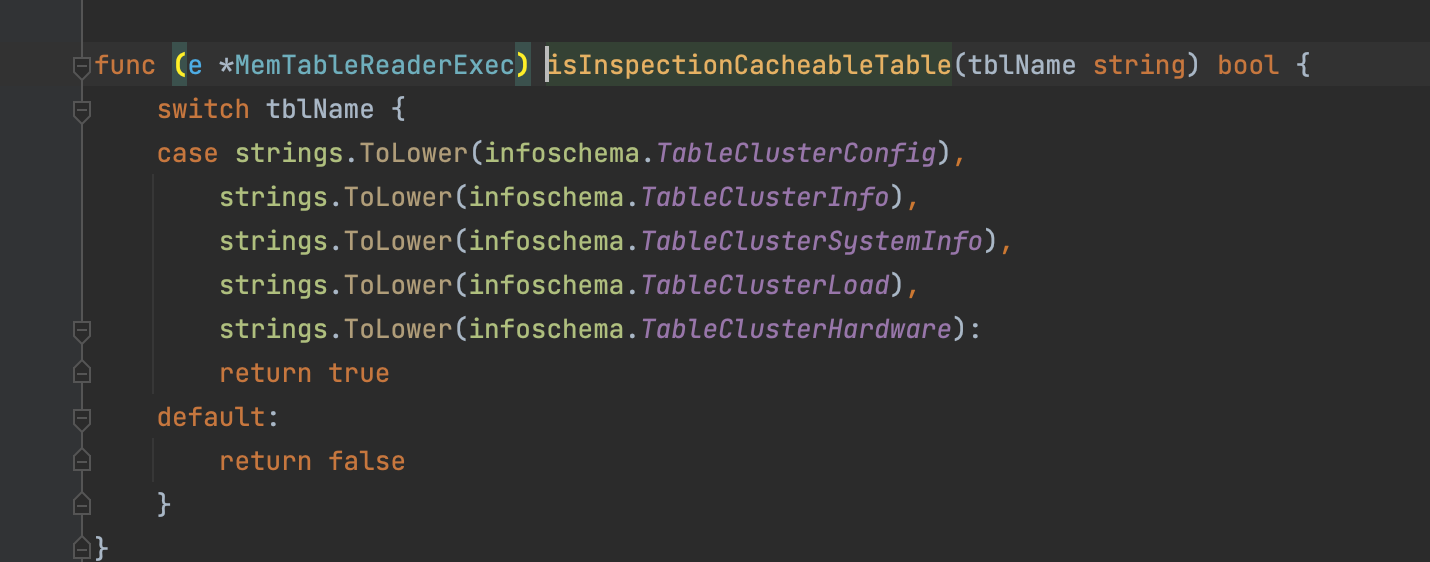
e.isInspectionCacheableTable(tbl) {
// TODO: cached rows will be returned fully, we should refactor this part.
if !e.cacheRetrieved {
// Obtain data from cache first.
cached, found := cache[tbl]
if !found {
rows, err := e.retriever.retrieve(ctx, e.ctx)
cached = variable.TableSnapshot{Rows: rows, Err: err}
cache[tbl] = cached
}
e.cacheRetrieved = true
rows, err = cached.Rows, cached.Err
}
} else {
rows, err = e.retriever.retrieve(ctx, e.ctx)
}
这段代码是用于检查是否可以从缓存中获取表的元信息,如果可以,则从缓存中获取数据。如果缓存中没有数据,则从存储中检索数据,并将其存储在缓存中以供下次使用。
这段代码并不需要遍历所有 TiDB 节点上的缓存信息,因为缓存是存储在当前 TiDB 节点上的。因此,无论 TiDB 节点的数量如何,都不会影响查询元信息的速度。
需要注意的是,如果缓存中没有数据,则需要从存储中检索数据,这可能会导致一定的延迟。但是,这种延迟通常是可以接受的,并且可以通过增加缓存的大小来减少。
从代码看没有命中 cache 就走到这个逻辑了 rows, err := e.retriever.retrieve(ctx, e.ctx),然后这些从磁盘中检索出来的数据被 tidb cache住 (e.cacheRetrieved = true),请问通过什么参数可以延长元信息被cache 的时间?
请问有最新的反馈吗
经观察,上面截图所用的时间也是 10s 左右,我尝试生产集群的整库用 br 备份/恢复到验证 tidb 集群,都是 5.4.1,两个集群数据量和表数量是一致的,验证集群就没有这个问题
数据分布不一样
tikv-ctl --host tikv_ip:20160 region-properties -r 671883302 看下这个输出