xiexin
(荒岛)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.10
【复现路径】还原命令 br restore full --pd=“xx.xxx.xxx.xx:2379” --storage=“s3://${backup_file}” --s3.endpoint=“http://xxxx” --s3.region=“xxx” --send-credentials-to-tikv=true --log-file=/tmp/restore_20230525.log
【遇到的问题:问题现象及影响】使用BR的物理备份还原集群,还原的服务器数据分布不均 ,部分节点磁盘使用率100%导致还原失败。
源集群版本v4.0.9
目标集群版本v4.0.10
br版本v4.0.10
第一次还原,目标集群与源集群服务器数量相同,还原过程中,部分机器磁盘写满,还原失败
第二次还原,往目标集群扩容了2台tikv,还原过程中,部分机器磁盘写满,还原失败
【资源配置】
源集群v4.0.9拓扑:8台服务器(3T磁盘),3pd、3tidb、8tikv、3pump、1prometheus
目标集群v4.0.10拓扑:10台服务器(3T磁盘),3pd、3tidb、10tikv、6pump、1prometheus
【附件:截图/日志/监控】
源集群8台服务器数据盘使用率:
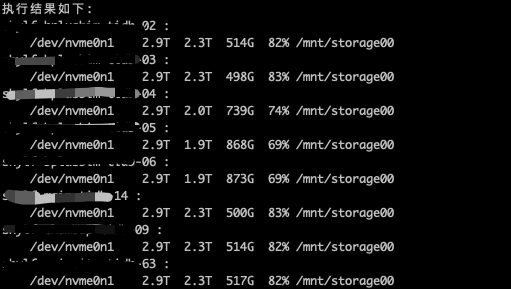
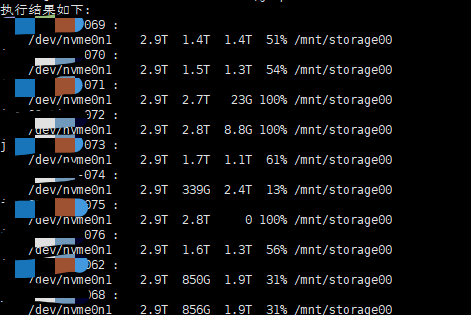
目标集群10台服务器数据盘使用率(第二次还原):
可以先通过监控看下 region 分布是否均衡:(cluster-overview - TiKV - region)
对了,尽量版本一致
源集群版本v4.0.9
目标集群版本v4.0.10
br版本v4.0.10
比如源集群版本是否可以升级为 4.0.10
xiexin
(荒岛)
5
就是为了版本升级所以做的数据迁移,region大小是差不多的,所以数据盘占用大的那些节点,region肯定更多,现在的问题是为啥还原的过程中,region分布差距这么大,其他节点还有空间,但是数据没有写入这些空闲节点。
原集群磁盘使用率80%+的是因为上面有额外的pump、prometheus节点,导致部分服务器磁盘使用率高点,region分布还是比较均匀的
xiexin
(荒岛)
8
目前的解决方案:
新集群扩容4tikv节点,共计14台服务器,使用BR还原,这次还原成功
然后再缩容节点。。
还原日志最后的成功信息:[“Full restore Success summary: total restore files: 341222, total success: 341222, total failed: 0, total take(Full restore time): 17h38m51.219922709s, total take(real time): 8h56m53.812512961s, total kv: 122530638751, total size(MB): 15156886.41, avg speed(MB/s): 238.57”] [“split region”=4h0m43.659493435s] [“restore checksum”=8h56m1.114043982s] [“restore ranges”=228924] [Size=5563286697035]
不好意思,好奇一个题外话题:
我见过许多大版本升级的确是迁移升级;
但是你这个小版本升级,也用迁移升级,是为啥啊?4.0.10 有特别不兼容的地方吗?
xiexin
(荒岛)
10
实际上是一个机房搬迁的需求,这里搬迁过程中,对目标TiDB集群版本做了一个小升级
system
(system)
关闭
11
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。