【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.0 2tidb 2pd 3tikv
【复现路径】tidb节点的内存一直增大不释放,内存占用完后导致节点重启,见红框所示。
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
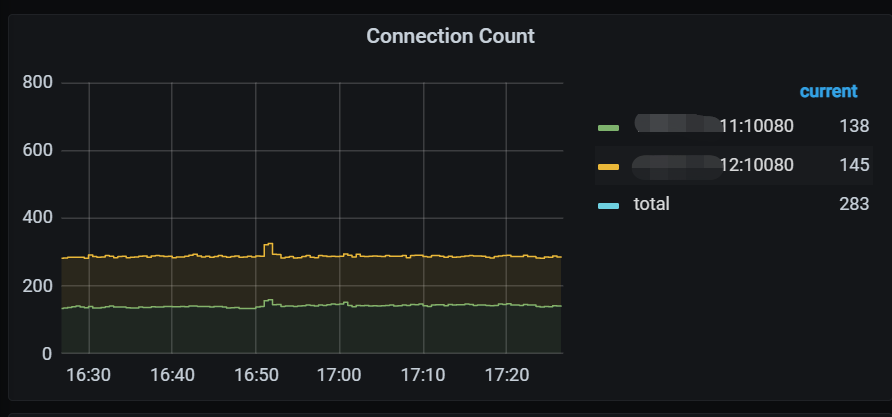
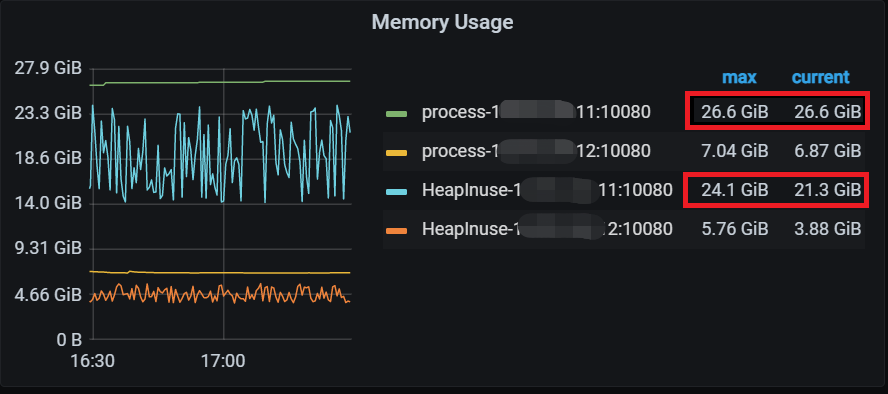
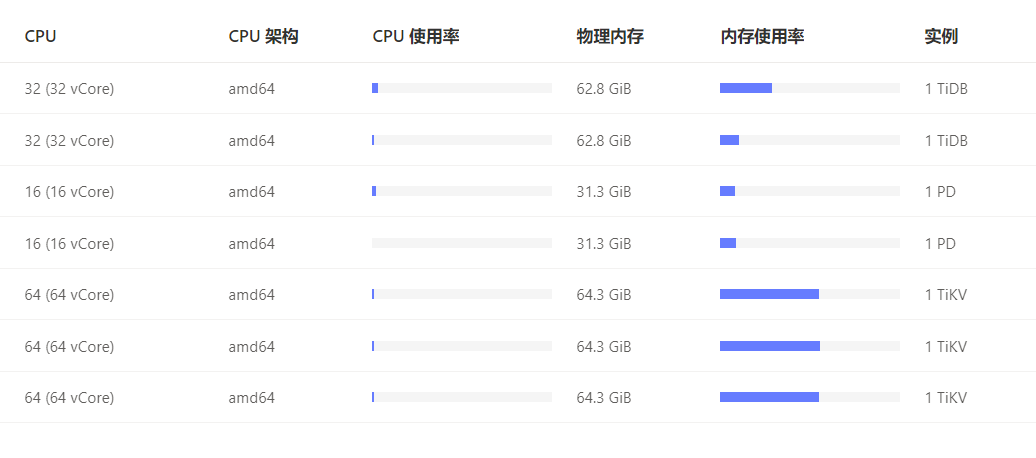
https://docs.pingcap.com/zh/tidb/stable/configure-memory-usage#tidb-内存控制文档
试试调整下 tidb_mem_quota_query,再看看具体哪个sql占用的
tidb server 内存耗尽是正常现象,多监控慢SQL,合理安排读写分离,一般都是读造成的,读写分离后,出现内存耗尽提前手工干预即可
要看下这个内存增长是不是在你重启tidb后一直持续上升的,如果是持续上升,可能是这个版本的一个bug导致, 将tidb_analyze_version设置成1试一下。
tidb 节点的内存是受 GC 周期调度来释放内存的
参考文档,描述原理和配置
https://docs.pingcap.com/zh/tidb/stable/dev-guide-timeouts-in-tidb#gc-超时
https://docs.pingcap.com/zh/tidb/stable/garbage-collection-overview
但是使用中的内存被释放掉,肯定不合理,能释放的肯定是已经不在使用中的内存了
那如果查询长期占用内存,会导致什么问题? 就无法释放咯
针对Slow query需要长期进行优化,减少内存的占用,另外 6.1.X 和 6.5.X 针对 内存释放进行了比较大的优化 (OOM 的情况有大量的减少),建议 POC 后升级…
已经设置tidb_analyze_version=1,观察了一段时间后内存还是增加不释放。
考虑下升级
升级到哪个版本呢,高版本不会出现这个问题吗?
生产环境pd起码要3个
请问下这个是根据什么来确定的?
pd的leader是选举出来的 你2个节点挂了一个 就没法选举了,2个节点的效果和单节点一样
超过内存限制或者时间限制的SQL直接干掉的脚本,这个比设置参数有效
for list in
/server/mysql5.7/bin/mysql -hXX.XX.XX.XX -p'password' -vvv -e " select id from INFORMATION_SCHEMA.processlist a where a.info is not null and (mem >=11474836480 or time >600);" |grep -Ev 'id|ID|iD|Id' |awk -F "|" '{print $2}'
do
echo $list
/server/mysql5.7/bin/mysql -hXX.XX.XX.XX -p’password’ -vvv -e “select id,time,info,mem from INFORMATION_SCHEMA.processlist a where id=$list and a.info is not null;;” > /sh/killlog/date +%s.log
/server/mysql5.7/bin/mysql -hXX.XX.XX.XX -p’password’ -vvv -e " kill tidb $list ;"
done;
用您这个语句查询了,没有符合要求的,有很多sleep状态的sql语句,设置5分钟断开空闲连接,连接数减少了,但是内存还是没有释放出来。
我这设置的是10G,你可以根据自己的需求修改条件的值,以便满足自己的需要