【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
生产环境在做tikv 扩容的时候,中间出现了一点问题,查看监控时发现。 Overview 里面的Services Port Status 显示 tikv 的节点数和dashboard 显示的节点数不一致
【资源配置】
【附件:截图/日志/监控】
连得prometheus查的,可以tiup cluster reload -R prometheus
reload下普罗米修斯试下
grafana的数据来源于Prometheus,Grafana的datasource记录的就是对应tidb集群的prometheus地址。
可以在Grafana打开对应图的edit,查看对于的promql,然后拿promql在prometheus查询
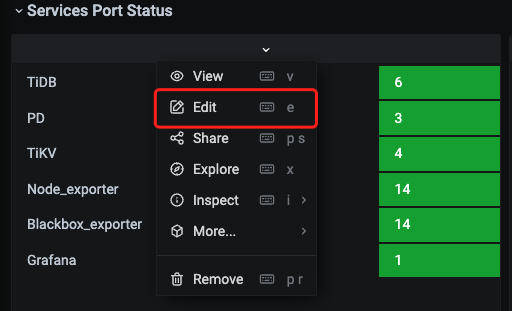
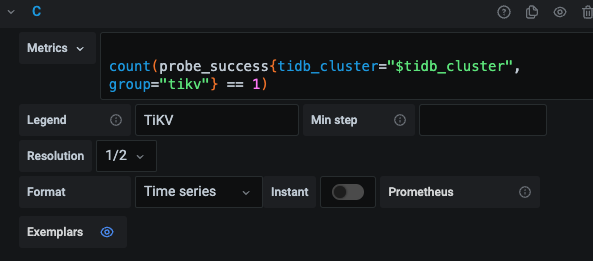
若数量不对,可以是用tiup cluster reload xxxx -R prometheus再看下
现在是想知道probe_success 这个指标是怎么统计的? 因为prometheus reload 重启非常的慢,重启期间监控都没有,所以很少reload prometheus
probe_success指标是各个节点对应的blackbox_exporter做的,应该是通过tcp连接各个节点的状态端口来判断是否存活的。
可以查看prometheus.yml配置文件中的job_name: “tidb_port_probe”,prometheus会定期获取probe_success指标,具体原理得找下blackbox_exporter的实现了
其实就是想知道probe_success 等一些监控指标,具体的计算逻辑。如果这些逻辑都清楚了,那么排查问题就容易多了
认同,理解指标的含义与计算逻辑有助于问题排查。但是官方对应监控指标的详细解释确实不多,各个组件状态接口返回的metric解释也很少。排查问题很难结合与利用这些指标。
prometheus时序数据库,grafana只是一个展示而已