【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】v5.4.3
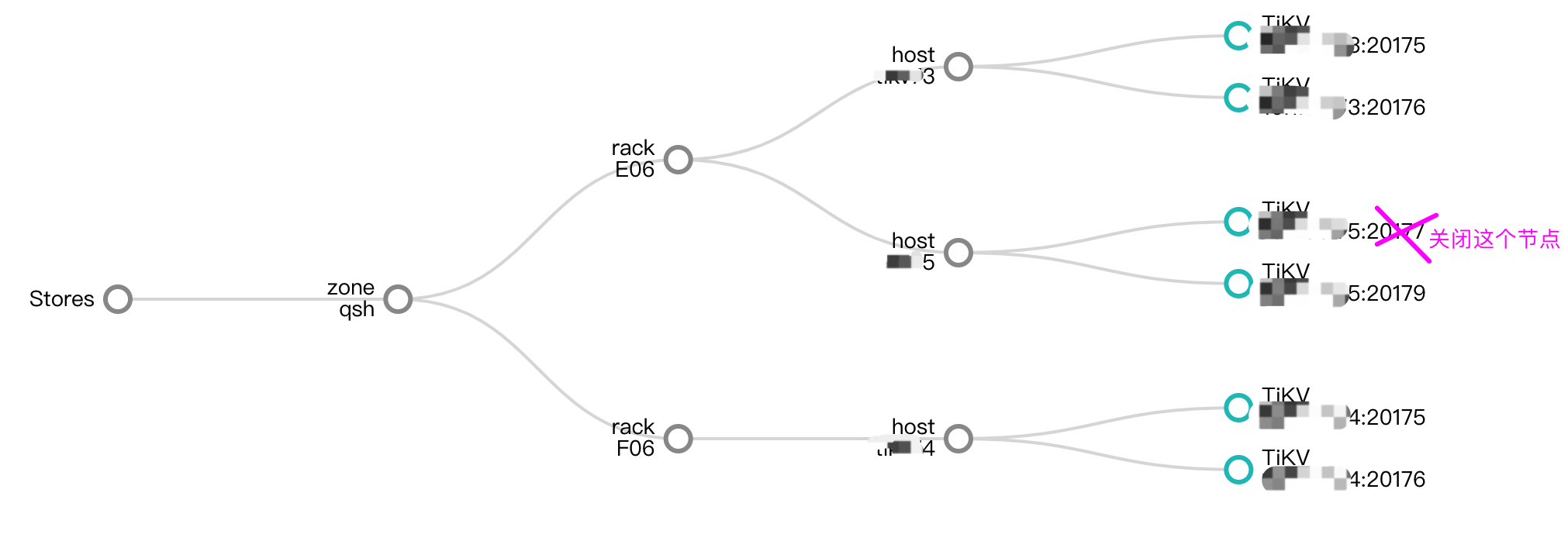
【复现路径】每台物理机上部署了2 个 tikv 节点(同一个物理机下不同盘部署tikv多实例),共3台物理机部署了6个tikv节点。当关闭某台物理机上的一个tikv后,region都往同物理机上的另一个tikv去补,造成 region 分布不均匀。
【资源配置】6 tikv ,3 pd,3 tidb(每台物理机上2个tikv节点,3台tikv物理机硬件相同)
【遇到的问题:问题现象及影响】
相关配置如下:
server_configs:
tidb:
log.slow-threshold: 300
tikv:
raftdb.defaultcf.force-consistency-checks: false
raftstore.apply-max-batch-size: 256
raftstore.apply-pool-size: 8
raftstore.hibernate-regions: true
raftstore.raft-max-inflight-msgs: 2048
raftstore.store-max-batch-size: 256
raftstore.store-pool-size: 8
raftstore.sync-log: false
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 24
rocksdb.defaultcf.force-consistency-checks: false
rocksdb.lockcf.force-consistency-checks: false
rocksdb.raftcf.force-consistency-checks: false
rocksdb.writecf.force-consistency-checks: false
server.grpc-concurrency: 8
storage.block-cache.capacity: 32G
storage.scheduler-worker-pool-size: 8
pd:
dashboard.public-path-prefix: /test-tidb
replication.enable-placement-rules: true
replication.location-labels:
- zone
- rack
- host
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
» config show leader-scheduler-limit
{
"replication": {
"enable-placement-rules": "true",
"enable-placement-rules-cache": "false",
"isolation-level": "",
"location-labels": "zone,rack,host",
"max-replicas": 3,
"strictly-match-label": "true"
},
"schedule": {
"enable-cross-table-merge": "true",
"enable-joint-consensus": "true",
"high-space-ratio": 0.7,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 8,
"hot-regions-reserved-days": 7,
"hot-regions-write-interval": "10m0s",
"leader-schedule-limit": 8,
"leader-schedule-policy": "count",
"low-space-ratio": 0.8,
"max-merge-region-keys": 200000,
"max-merge-region-size": 20,
"max-pending-peer-count": 64,
"max-snapshot-count": 64,
"max-store-down-time": "30m0s",
"merge-schedule-limit": 8,
"patrol-region-interval": "10ms",
"region-schedule-limit": 4096,
"region-score-formula-version": "v2",
"replica-schedule-limit": 64,
"split-merge-interval": "1h0m0s",
"tolerant-size-ratio": 0
}
}
【附件:截图/日志/监控】
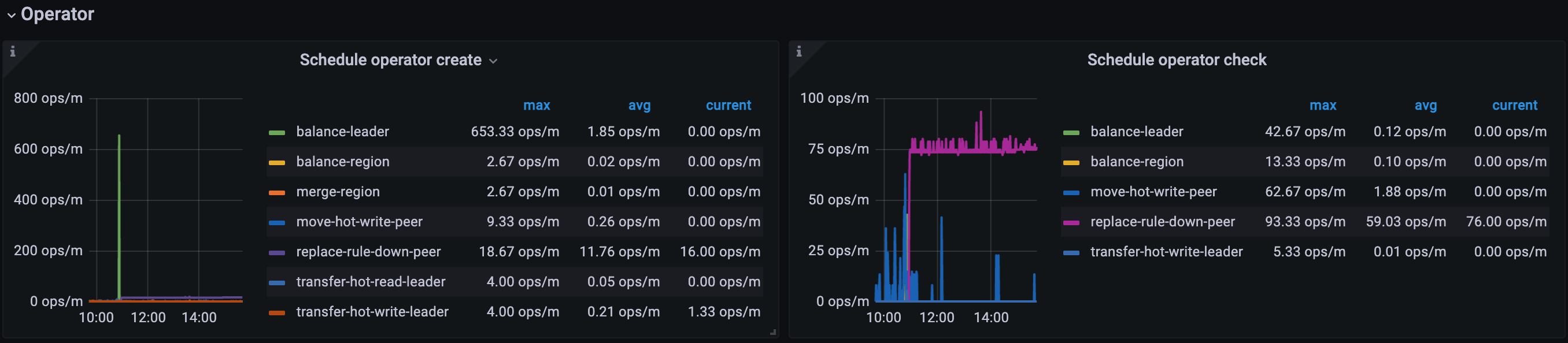
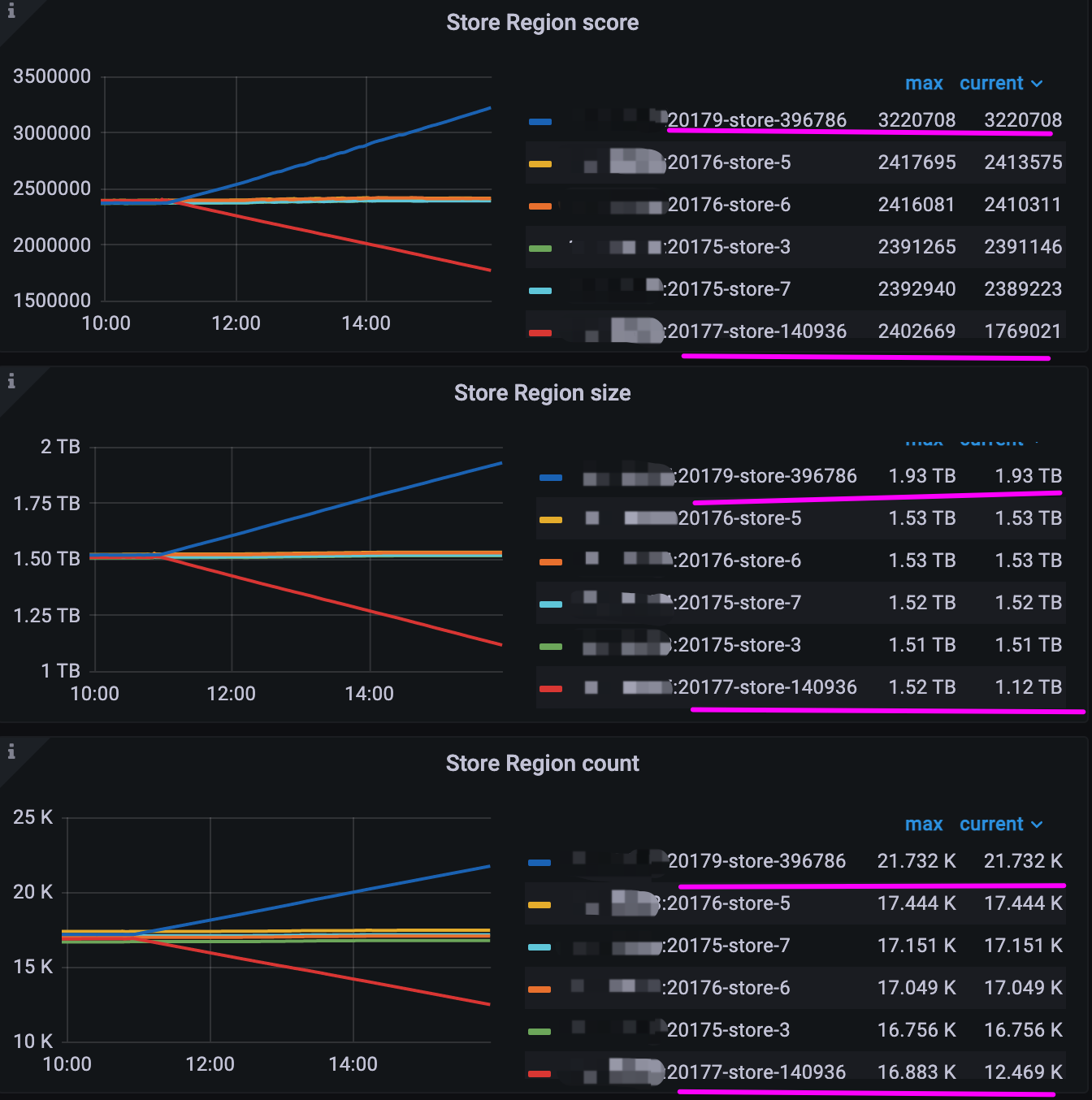

为什么 store-140936 关闭后, region 都往同物理机的另一个tikv节点 store-396786 上迁移,而不是往剩下的5个tikv节点均衡迁移呢?
mysql> SELECT t1.store_id, sum(case when t1.is_leader = 1 then 1 else 0 end) leader_cnt,count(t1.peer_id) region_cnt FROM information_schema.tikv_region_peers t1 GROUP BY t1.store_id
-> ;
+----------+------------+------------+
| store_id | leader_cnt | region_cnt |
+----------+------------+------------+
| 3 | 6840 | 16757 |
| 140936 | 0 | 12275 |
| 6 | 6846 | 17050 |
| 7 | 6838 | 17151 |
| 396786 | 6839 | 21927 |
| 5 | 6838 | 17444 |
+----------+------------+------------+
6 rows in set (1.33 sec)