大佬,这个期间出现大量 读热点,读热点发生后PD进行调度region-leader。
会不会因为调度引起的copy 内存消耗过大。
看节点内存分布:
是不是cpu打满之后,GC不及时导致 内存一直没释放:
estimate-inuse:27G 能对的上heap profile中的 root memory 大小
estimate-garbage:18G 是不是等待GC的内存
reserved-by-go:14G
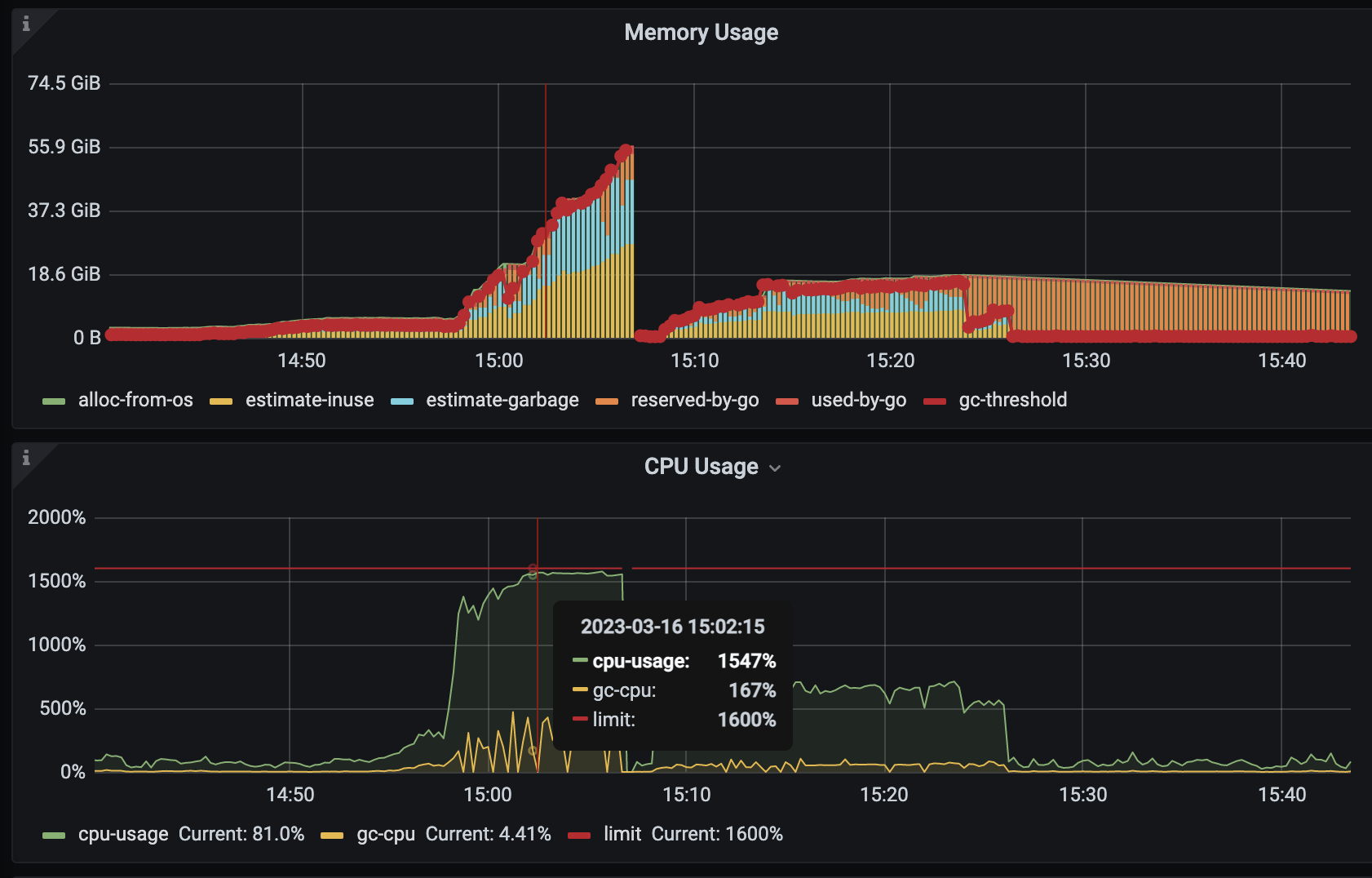
不会的,这个copy是发生在count distinc阶段,这个阶段只有tidb的算子参与。region的调度是pd发出调度机制然后tikv执行的,tidb不会参与的。
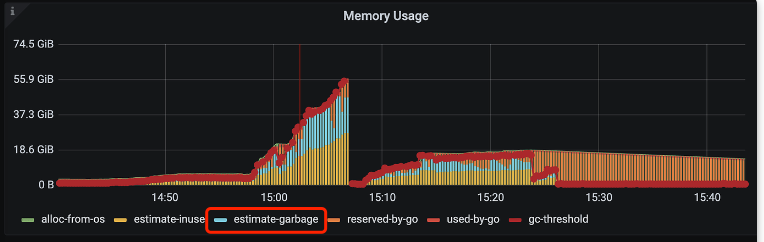
了解,辛苦大佬帮看下上面的图。
goroutine 文件,发现很多 goroutine 11 [syscall, 529542 minutes]: 的进程。
goroutine2023-03-10T04:51:34+08:00 (1.2 MB)
看到这个帖子说TiDB内存占用持续增长 - #22,来自 OldJack 说有 enable-streaming 可能导致内存缓慢释放。
goroutine 290 [select, 380228 minutes]:
google.golang.org/grpc.(*ccBalancerWrapper).watcher(0xc00065c880)
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/pkg/mod/google.golang.org/grpc@v1.26.0/balancer_conn_wrappers.go:69 +0xc2
created by google.golang.org/grpc.newCCBalancerWrapper
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/pkg/mod/google.golang.org/grpc@v1.26.0/balancer_conn_wrappers.go:60 +0x16d
- 检查参数配置已经关闭
root@ 22:05:57 [(none)]> select @@tidb_enable_streaming;
+-------------------------+
| @@tidb_enable_streaming |
+-------------------------+
| 0 |
+-------------------------+
1 row in set (0.00 sec)
root@22:06:18 [(none)]> show global variables like '%tidb_enable_streaming%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| tidb_enable_streaming | 0 |
+-----------------------+-------+
1、count distinct值太多,这个想办法优化,比如减少字段或者用group by来代替(但是要注意并行hashagg不能落盘的问题),这个你要深入了解下tidb的内存管理机制才行。
2、热点读非常高主要还是全表扫描的问题,你一个SQL里面好几个全表扫描,每一个全表扫描并发默认15个distsql_scan,所以一个语句就需要占用很大的内存空间,还要考虑部分GC的问题。然后并发语句上来后就导致内存紧张。读热点和读热点调度等都是表象。优化方式:1、减少全表扫描,无非就是加索引,应用优化等自己想办法解决即可。2、升级到6.5,在6.5上默认开启了enable_paging=ON,这个可以大大减少tidb侧缓存tikv过来数据的压力,有效降低全表扫描带来的内存使用过大问题。
如果感觉上面都很难做调整,那么先临时修改参数,降低全表扫描带来的数据缓存压力吧。
在语句session级别开启:set tidb_distsql_scan_concurrency=3。代替之前的默认值15。这个最低可以调整为2,但是效率会降低一些。为何数据会在tidb侧产生积压,主要是这些算子消费的不够快,适当调整小distsql_scan并发度对整体效率不会太大影响的。PS:如果官方支持在hint上针对某张表的访问调整tidb_distsql_scan_concurrency就好了,就可以针对某一张无法优化的全表扫描做低并发扫描来减少内存压力,在其它比如indexlookup等回表扫描用默认高并发扫描。
我觉得把这几个全表扫搞定,基本就能解决你的问题了。业务层面入手优化下
一个查询扫 8000W、2.5亿、7.7亿、1.7亿数据,再来点并发,肯定会有问题,还是一连串连锁问题 ![]()
感谢。
-
内存有相关文档么,从开发文档上https://pingcap.github.io/tidb-dev-guide/understand-tidb/memory-management-mechanism.html 了解到分为 tracker、oom-action,具体某些算子可以用 磁盘还不是了解很全面。
-
全表扫描和 “count distinct值太多” 这两个sql,在找研发沟通处理,目前给全表扫描的查询加了 hint 限制最长执行60s,发现前端过来请求从1变为10了。很多坑要踩·~·
-
6.5在升级路上,可能要Q3升级,到时候评估版本。
- 6.5 还有两个特性:tidb-server-memory-limit、tidb-enable-gogc-tuner 应该能缓解待GC内存,来不及回收的问题。
感谢大佬!
谢谢!
最终定位:
就是造成热点的全表扫描查询造成的。
[mem_max="9761736857 Bytes (9.09 GB)"] [sql="SELECT /*+ MAX_EXECUTION_TIME(60000) */ ra.I_ID, ra.CH_ORDER_ID, ra.CH_BROKER_ID, ra.CH_DEALER_ID, ra.CH_BATCH_ID, ra.CH_ANCHOR_ID, ra.CH_REAL_NAME_ENCRYPT, ra.CH_TELEPHONE_ENCRYPT, ra.CH_ID_CARD_ENCRYPT, ra.CH_ID_CARD_UC_ENCRYPT,
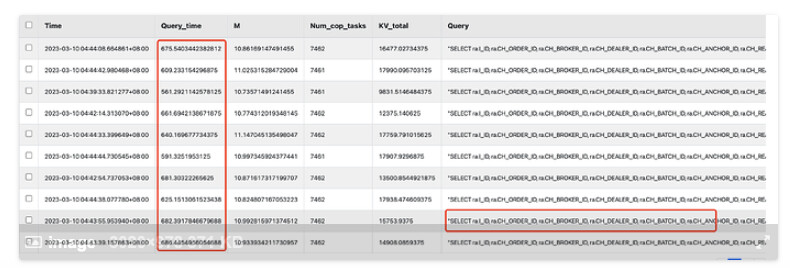
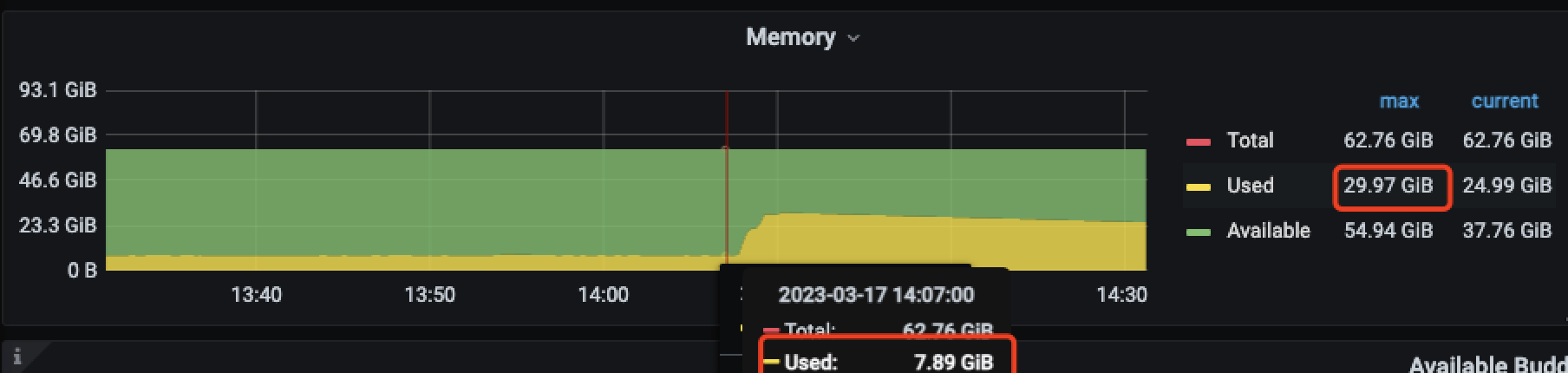
sql没执行完记录的内存消耗(9.09 GB),执行完内存 100M+ 。怀疑4.0版本tidb计算内存不准确。
内存上涨和sql执行时间也对上了。
只能认真看代码了,内存追踪的最主要的结构体和方法如下:
内存追踪定义:数据库中用到的内存统计都是依赖这里的树形结构进行追踪的,根节点时整个语句的总体内存追踪情况,孩子包括各个算子的内存使用情况等。
内存追踪计算:当执行到一个算子时候做数据运算时会统计其内存的使用情况,会用到consume方法,该方法会遍历所有的父节点内存进行累加,并判断是否会触发oom-action动作。
oom-action的定义:定义oom-action的一些行为。
还有oom-action的行为优先级的处理,回退处理等参考:
仔细了解内存追踪这块内容后,然后去算子等用内存的地方看埋点去就行了。