【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】v5.4.0
【复现路径】做过哪些操作出现的问题
集群大概7T,上周五删数据,删掉了很多,大概几十亿条。
然后有个tikv就故障了(没看到现场,当时是别人处理)
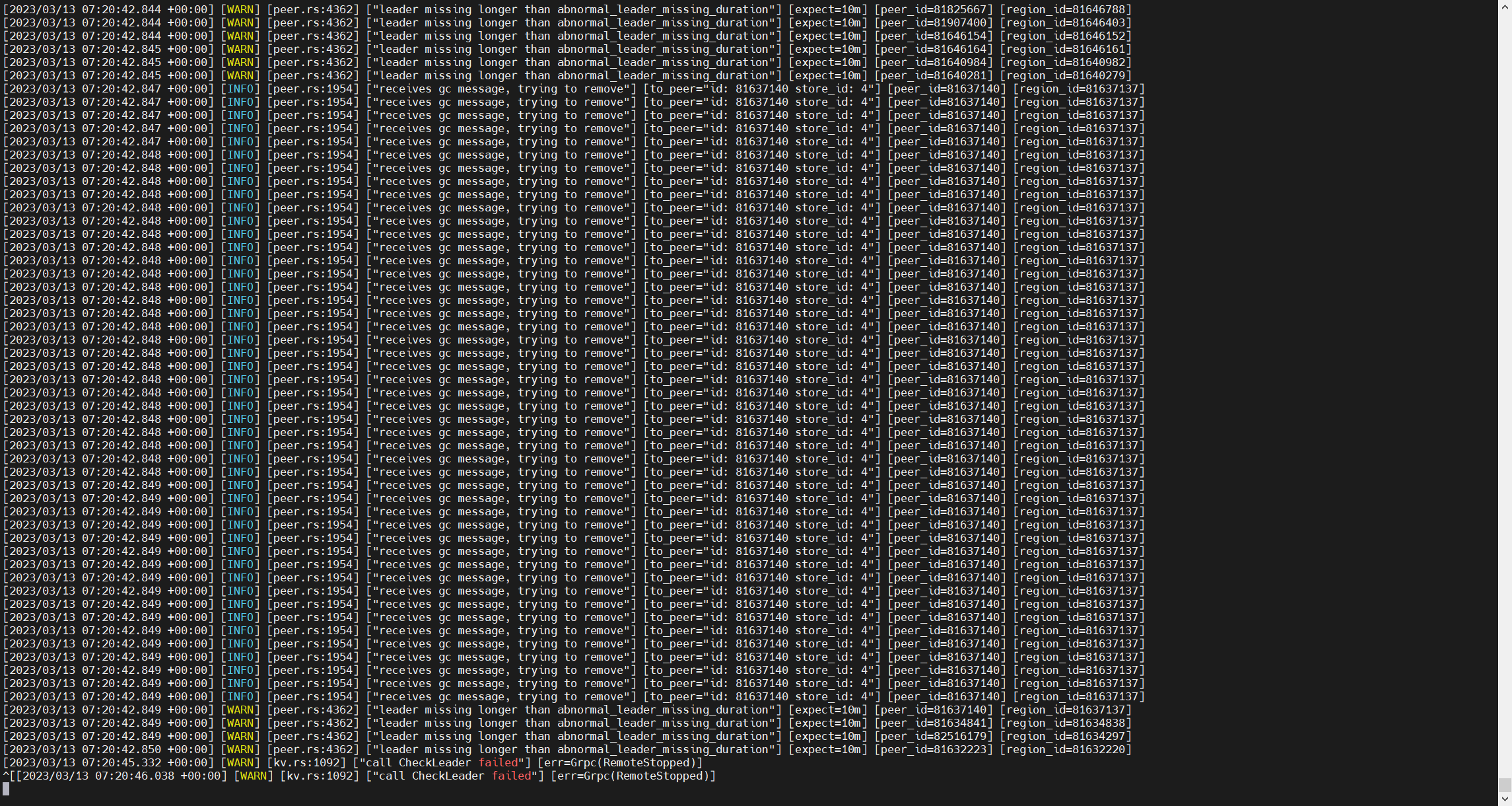
今天一看,tikv1一直刷如下的日志:
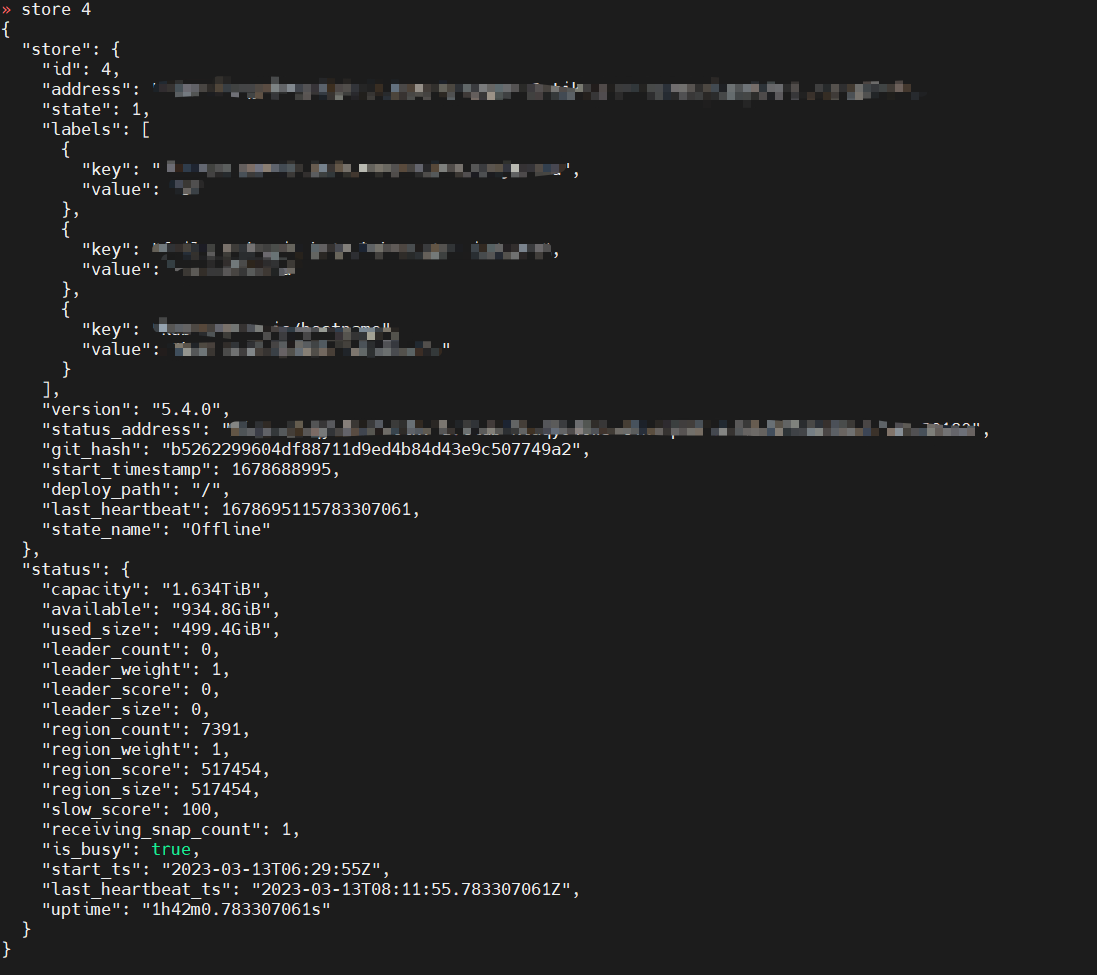
pd-ctl 看tikv1 里的 is_busy:true
现在tikv1上没有leader
问题是:tikv1为什么总也忙不完?怎么才能让tikv1快速忙完跟上进度?就是说现在整个集群都停了访问了,允许随意折腾,tikv1可以让他cpu 100%用来忙这个忙不完的事儿。 怎么调整调整?
重建是最后考虑的哈,重建解决问题就像网吧里的网管让重启一样,没什么技术含量  。
。
h5n1
(H5n1)
3
pd-ctl store 4 、 pd-ctl region 81637137 、tiup cluster display结果、之前的tikv故障现象和处理流程与结果描述下
考试没答案
(Ti D Ber P Kfity Gq)
6
可以调整下GC的参数看看, 是不是删除后垃圾太多了,GC 搞不过来。
tikv1 :disconnect和down之间切换。上面贴的图就是tikv1不断刷的。
现在tikv1, store4是offline,因为最终还是重建了

之前一直是disconnect和down切换。
那个region现在也正常了,store4上的副本没了。
tiup那个没法看,因为是k8s管的。其他tikv基本上都正常,但是tikv0,tikv1(store4), tikv10 不断有disconnected
之前的故障就是:
有很大的读写流量的情况下,删除了很多数据,导致读写延迟很高,业务方就把业务停了。集群没操作。今天一看,期间tikv1(store4) oom了一次。然后不断刷上面的日志。
tikv0 不断刷下面的日志。
region也是因为store4 down了
上面的日志我看了下代码,说是因为在网络上收到了本地消息,忽略。
所以问题又出来了,为什么本地消息会发到其他节点?什么情况下会发送?
内存的话,有一个节点oom过,其他节点正常。当前store4 的内存是现在所有节点中最高的。
这个都删了好几天了,gc的话按理说也触发了,现在感觉是tikv1(store4)离线时间太久,有点跟不上进度的样子。在那里忙活着处理删除之类的事儿。
h5n1
(H5n1)
12
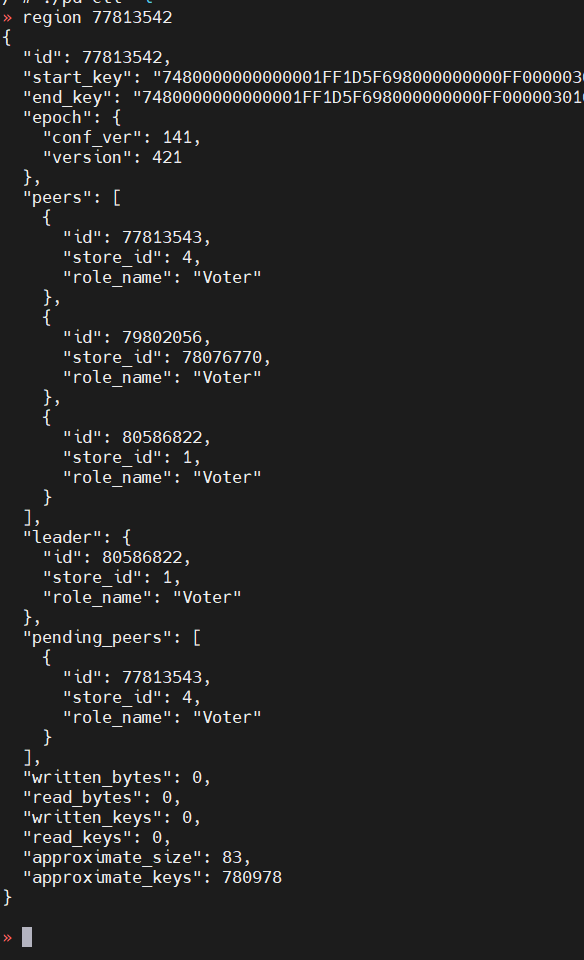
试试 把error报错的的region peer从store 4删除: pd-ctl operator add remove-peer 77813542 4。 不是有很多个region报同样的错误把?
那一批日志一会儿刷一片,regionid不一样,删了以后,tikv0日志:
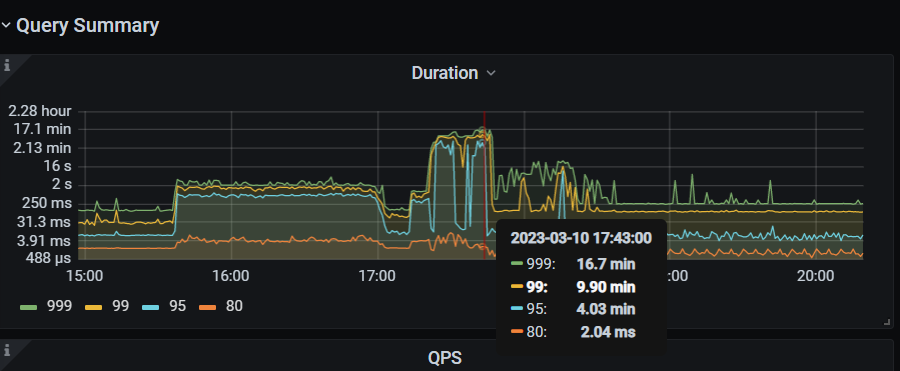
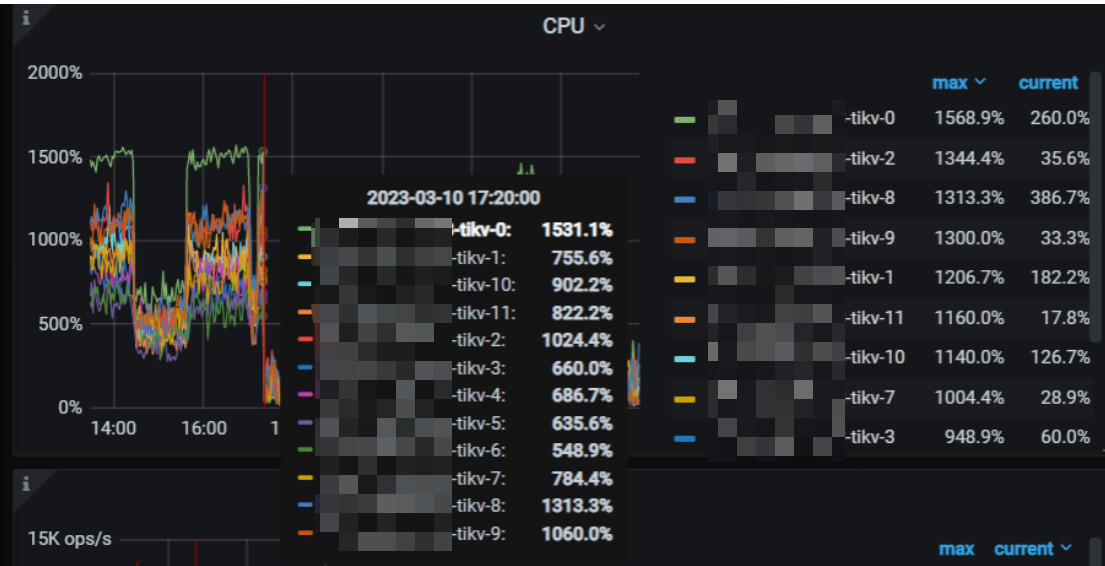
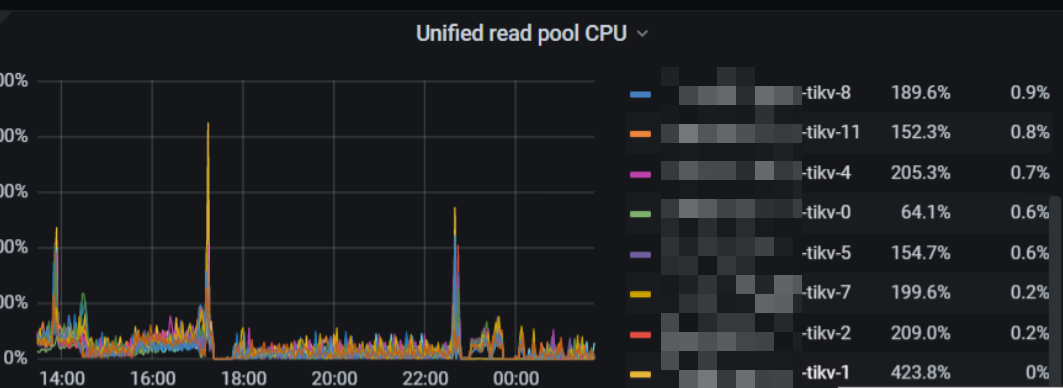
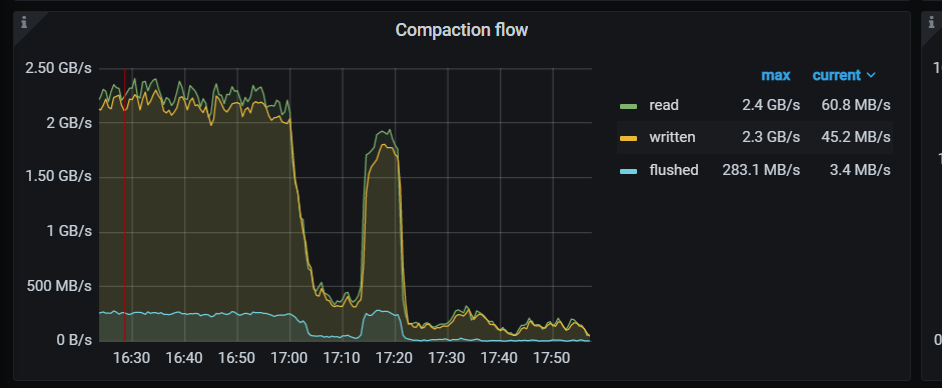
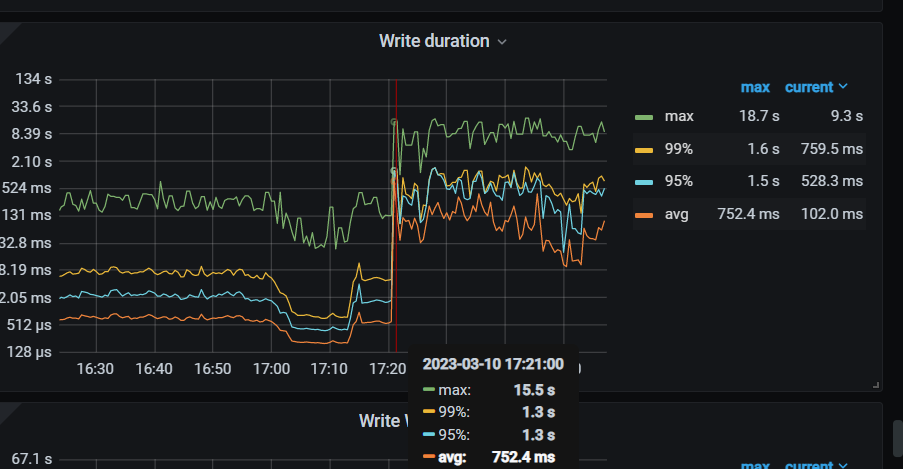
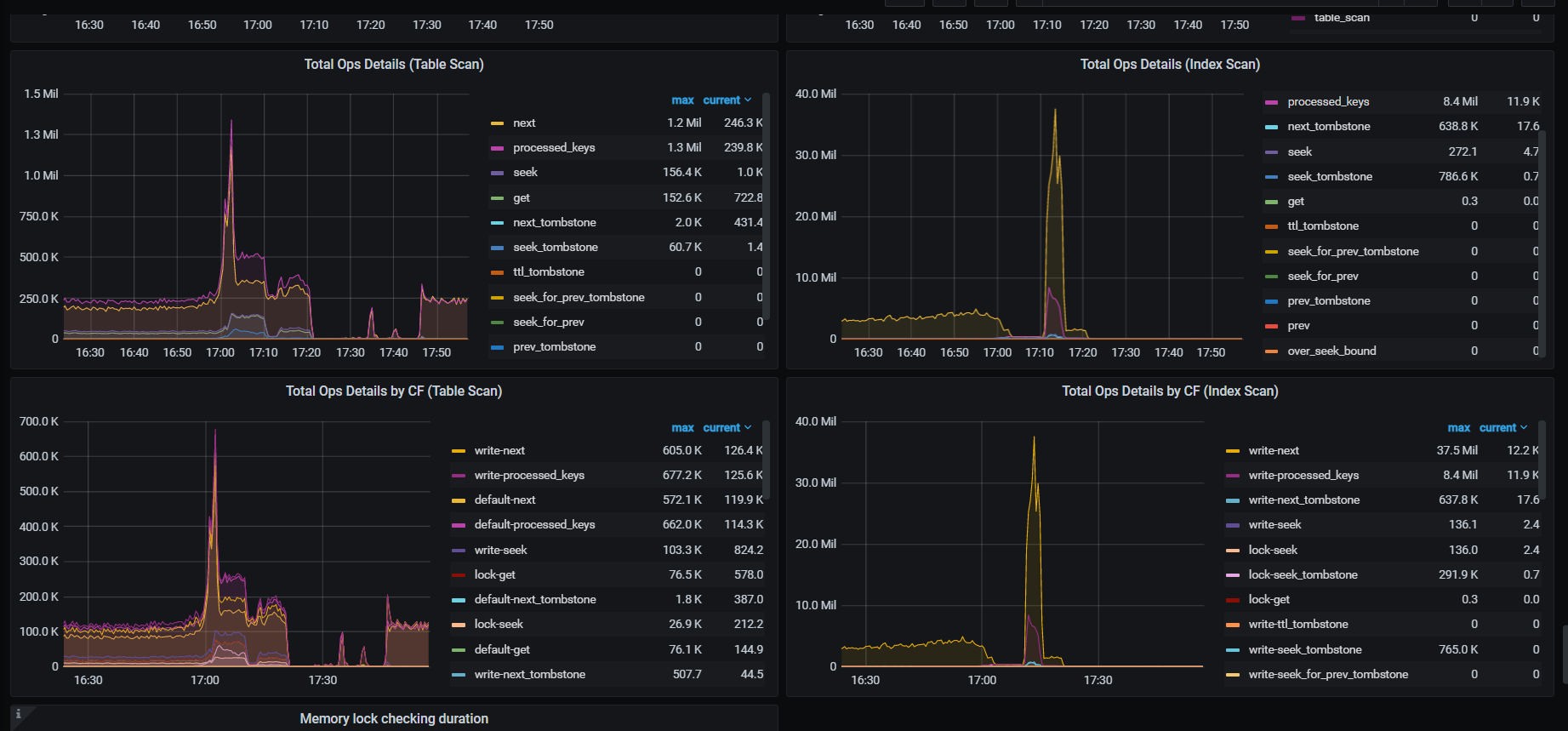
分析了监控:
删除的时候,读写请求也很多,然后删除又得扫描表。导致磁盘io都比较满了。
然后compact又来了,进一步搞满了磁盘io。
然后写的延迟比较高。
问题是:这个为什么就乱套了?磁盘io满了就慢慢等着io呗。过了一个周末都没有恢复正常,这是哪里出了问题?
部分监控如图:
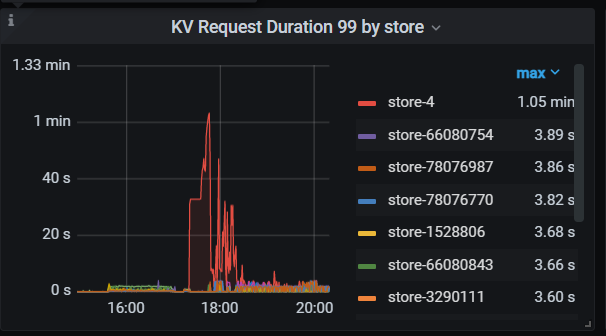
h5n1
(H5n1)
16
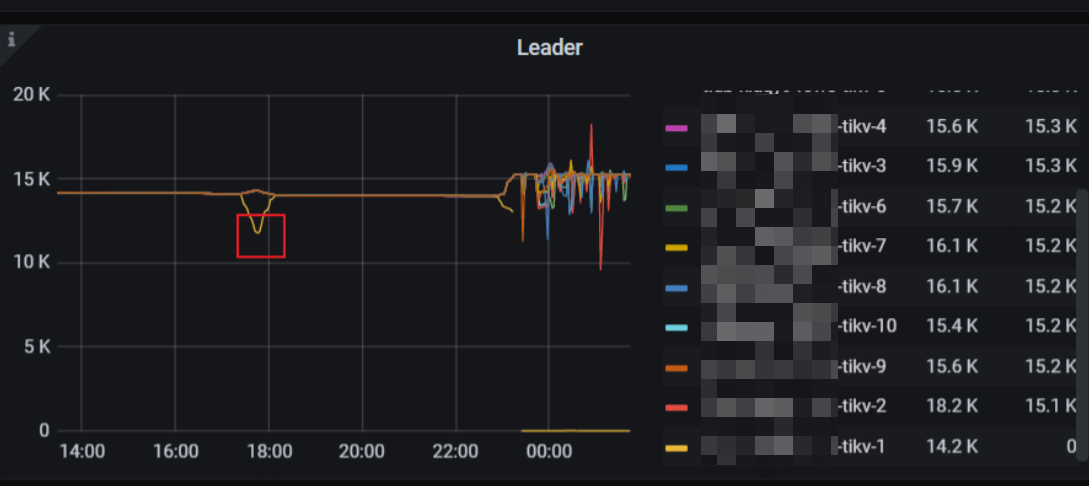
1、你看下 监控中 store 4的region 数量是不是在减少,在减少说明在正常迁移,要是没变化的话可以用上面的add remove-peer把store 4上的region都这么处理下,否则store 4一直都是offline
2、大量删数据后GC compact 大IO正常,你的磁盘是什么类型,感觉性能上要差些
3、你这个场景我感觉像是遇到bug了
是在减少,offline是因为执行了store delete,想要下线store4,然后重建。在执行store delete 之前,就一会儿是disconnect,时间就了就是down
磁盘还是可以的,nvme的盘,当然又因为nvme做了lvm,又分给了每个tikv,并不是一个tikv独占一个nvme,看起来这点io就打到了上限了,实际上还有其他tikv在写同一块盘。
这个就是我想了解的,是啥bug,好像tidb在删除大批量数据时容易出问题,在我理解中,执行完compact就应该能正常服务了,但是实际上并没有,集群一直在那里不紧不慢的划水,就类似于:我搞不定了,躺平了 
所以,有没有什么参数鞭策一下它,让它抓紧干活 
网络没事儿,我们有专们的团队管k8s那一套。
纯自己运维确实很难。