大佬,这个问题有办法解决吗
集群 重启下是不是可以解决啊
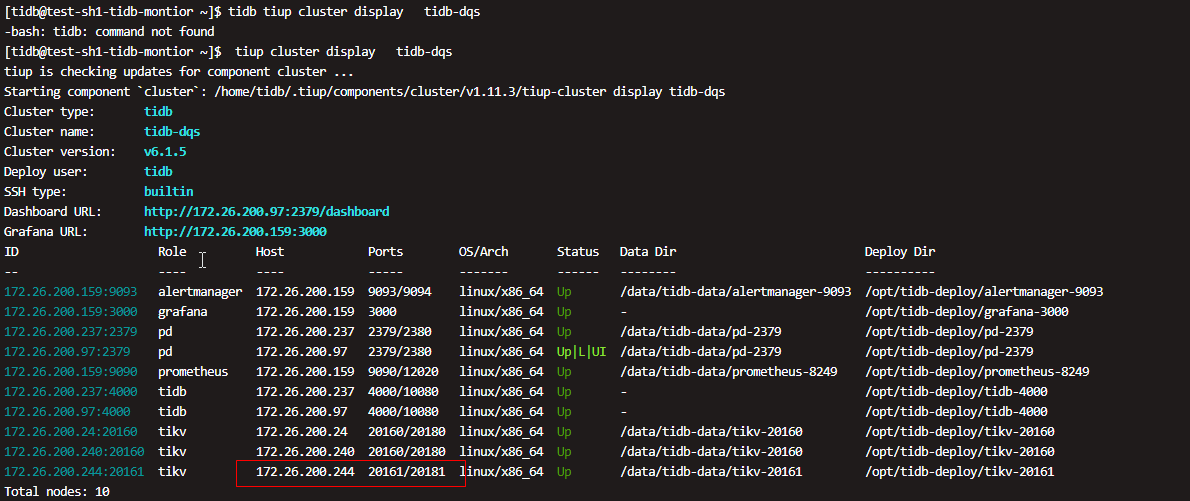
三台tikv,有两台一直在刷错误日志,一台不怎么刷
看下pd leader的日志
怎么查哪个是pd leader啊
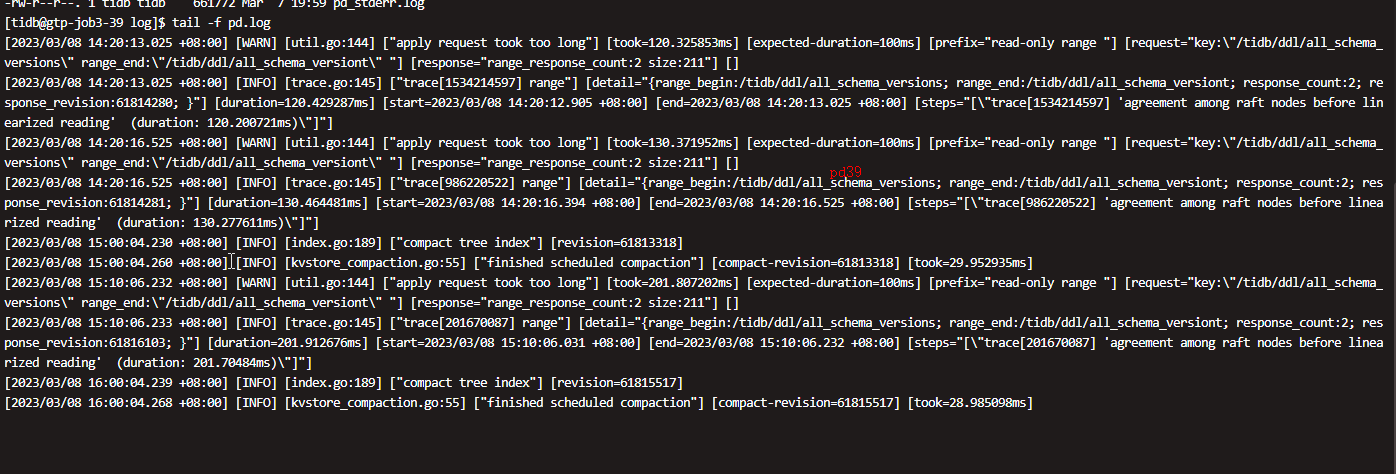
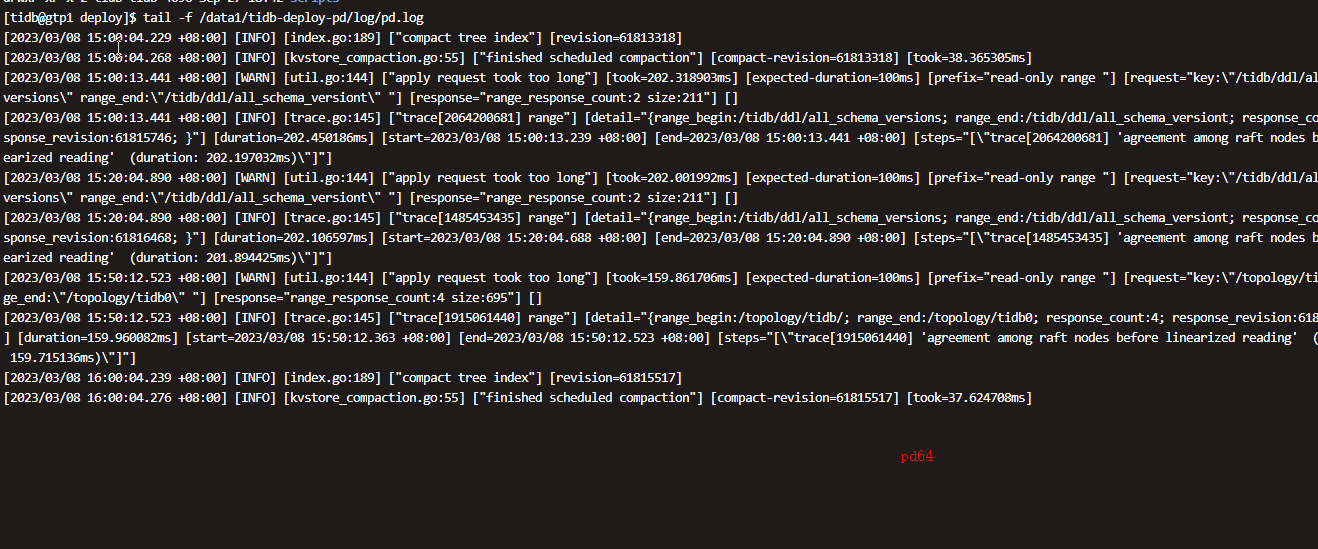
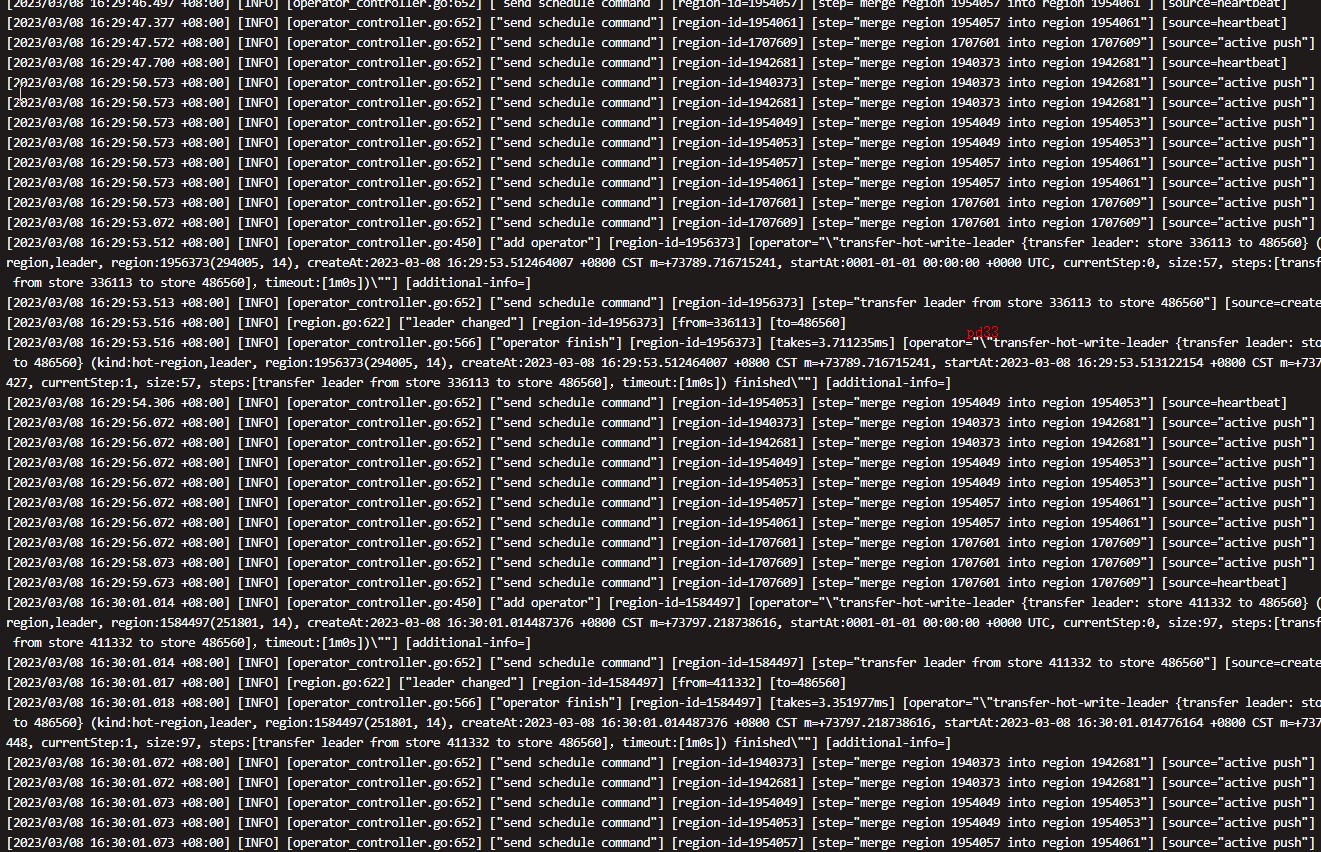
pd好像没有什么报错
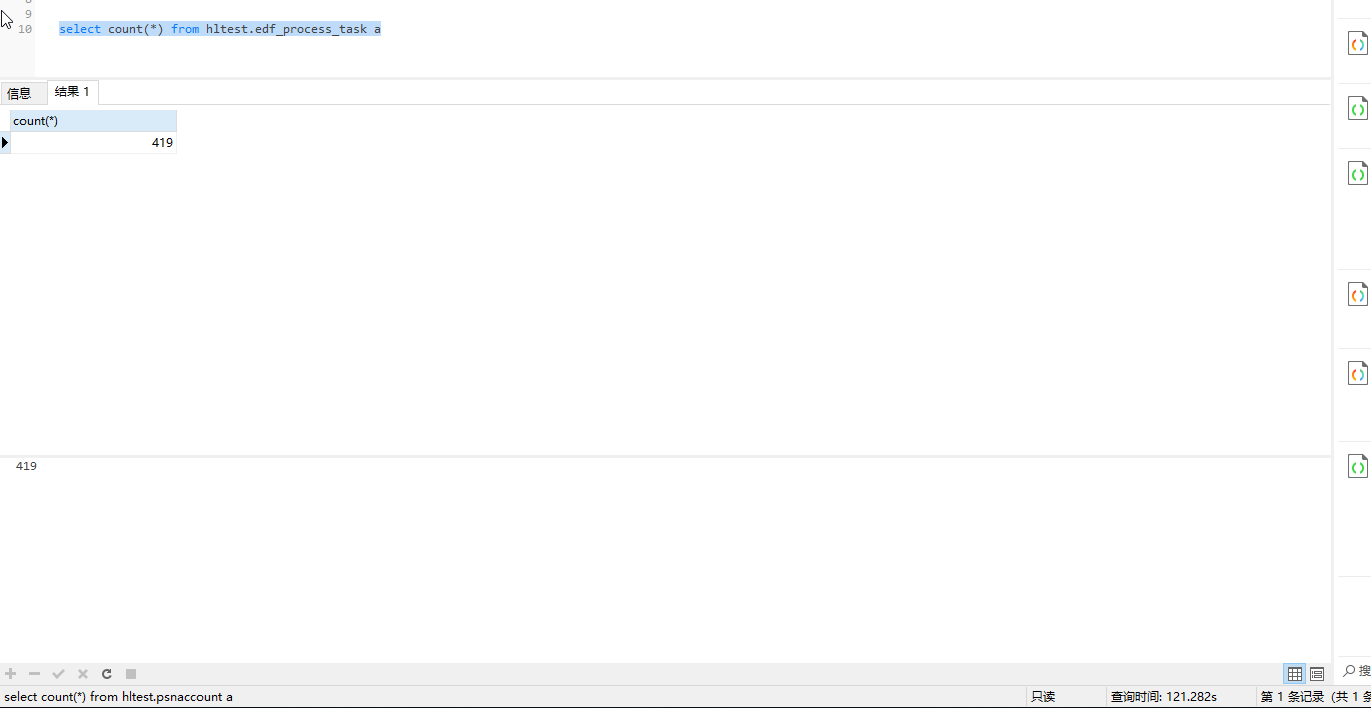
那2个表单独查下 看看哪个会报错
select count(*) from hltest.psnaccount a
select count(*) from hltest.edf_process_task a
几百条数据,查询非常慢,没有报错

[2023/03/08 15:47:27.453 +08:00] [WARN] [raft_client.rs:296] [“RPC batch_raft fail”] [err=“Some(RpcFailure(RpcStatus { status: 14-UNAVAILABLE, details: Some(“failed to connect to all addresses”) }))”] [sink_err=“Some(RpcFinished(Some(RpcStatus { status: 14-UNAVAILABLE, details: Some(“failed to connect to all addresses”) })))”] [to_addr=192.168.3.64:20170]
这是什么情况。为什么会找20170 你之前有这个端口?
之前的没映像了,都是默认的
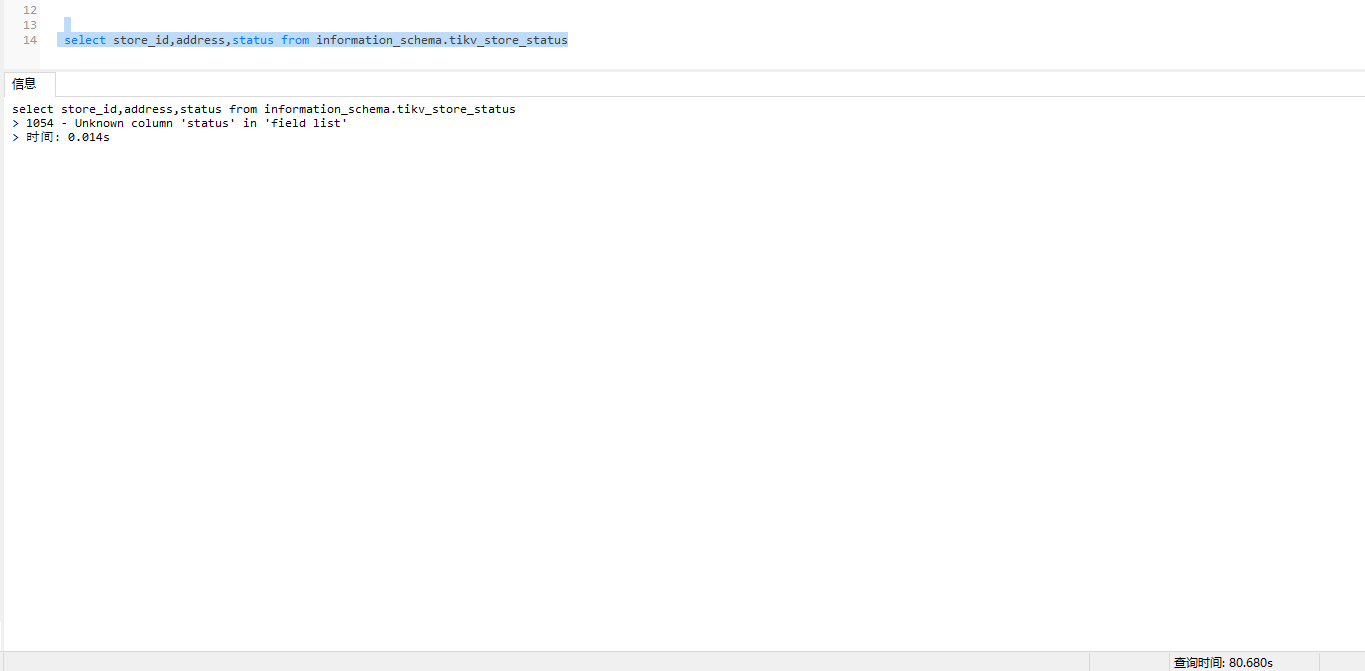
select store_id,address,status from information_schema.tikv_store_status或pd-ctl store看看
你把问题节点tikv的日志发一份
tikv.log.zip (2.4 MB)
今天下午部分的