知道列值 时的行数预估 和 作为被驱动表不知道列值的某些情况下, 或许预估的计算公式是不一样的,具体就官方知道了
我想应该是这样(对于等值来说):
知道列值 时的行数预估:先判断TOPN中是否有,如果有直接返回估计值,如果没有则采用Count-Min Sketch算法查找和计算这个值对应的估计值。
作为被驱动表不知道列值的某些情况下: (对于1个关联条件来说)类似于where col=?的情况,没有具体值,则无法评估数据倾斜,过滤因子(filter factor)按照1/NDV来评估,比如select * from a,b where a.col1=b.col1;假设a.col1为outer表,那么认为匹配的结果集数为:count(a.col1) * 1/count(distinct b.col1)。
1 个赞
楼主能不能给出问题的完整语句的explain信息和对应的plan replayer信息呢?或者简化下语句,只给出问题部分的SQL语句以及执行计划和对应的plan replayer也行,感觉给的这些信息都不太连贯。
顺便说下,你这个应该是升级上来的?
看你tidb_analyze_version=1,可以尝试修改为2试试。
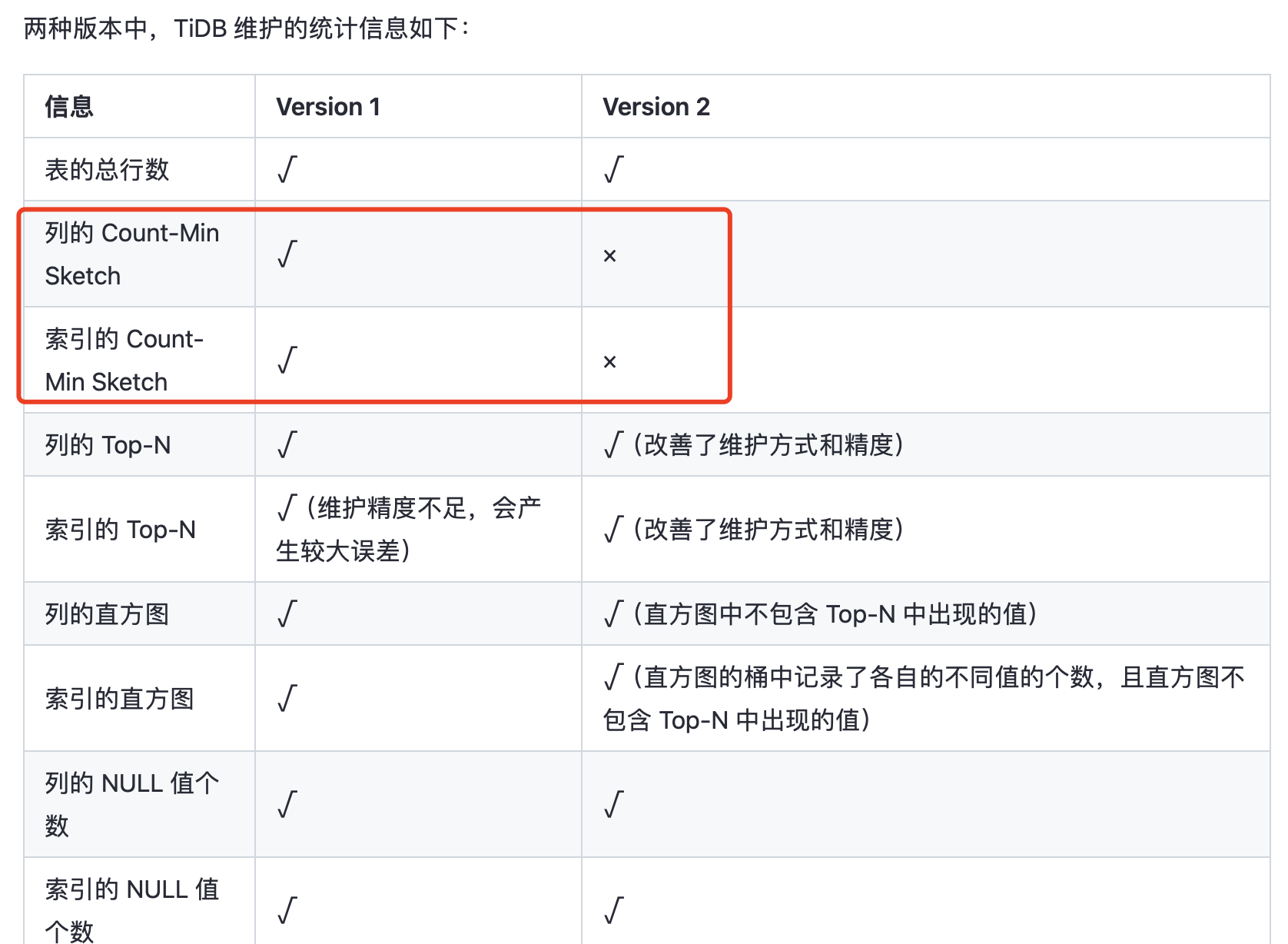
看下面这里,version2情况下好像不支持了count-min Sketch了,像是如果TOPN中没有,直接按照1/count(distinct col -TOPN) 来计算,期待官方大佬解释下。
https://docs.pingcap.com/zh/tidb/stable/statistics
这个地方是一处 explain 结果显示上面的 bug,并不是真正的统计信息用的不准
在 IndexHashJoin 的 Probe 侧的这个 estRows 只有 2.16,这个是估算的执行一次的代价
实际上 IndexLookUp_153(Probe) 这个要执行 4460440.32 次!
所以 2.16 3.57 这些数字都应该显示成 ? x 4460440.32 才是真正的 estRows
这个 2.16 之类的 estRows 的估算,确实如 @h5n1 和 @人如其名 说的,是通过 1 / NDV 这样的 distinct 的方式计算的。
另外,如果这个场景下是 ignore index 走 scan 的方式比回表要快的话,那么也不是统计信息的问题,而是说我们对回表的代价假设得过低了一点。真实场景里面如果回表 scan 要涉及的 store / region 太多的话,会生成特别多的分散的 distsql 请求,这种行为的性能是比较低下来,往往还不如 scan 的顺序扫方式。
(或者可以类比一下,随机 io 特别多的时候,跟顺序 io 扫的量比较大,后者可能还快一点)
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。