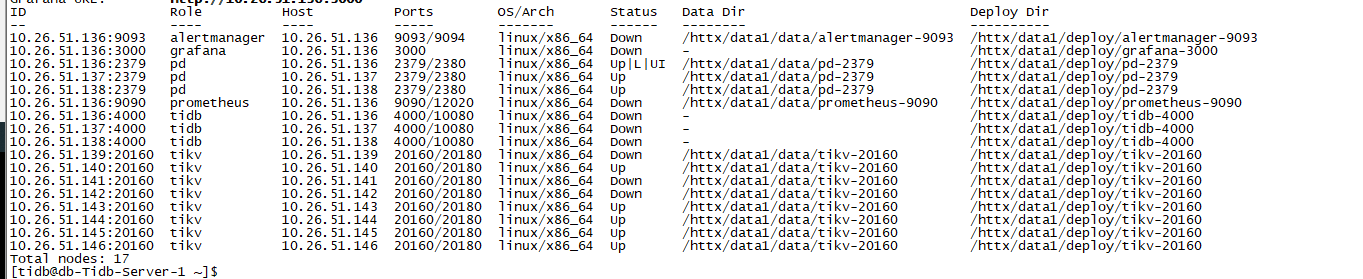
[FATAL] [server.rs:407] [“panic_mark_file /httx/data1/data/tikv-20160/panic_mark_file exists, there must be something wrong with the db. Do not remove the panic_mark_file and force the TiKV node to restar
t. Please contact TiKV maintainers to investigate the issue. If needed, use scale in and scale out to replace the TiKV node. https://docs.pingcap.com/tidb/stable/scale-tidb-using-tiup”]
显示:
Error: failed to start tikv: failed to start: 10.26.51.139 tikv-20160.service, please check the instance’s log(/httx/data1/deploy/tikv-20160/log) for more detail.: timed out waiting for port 20160 to be started after 10m0s