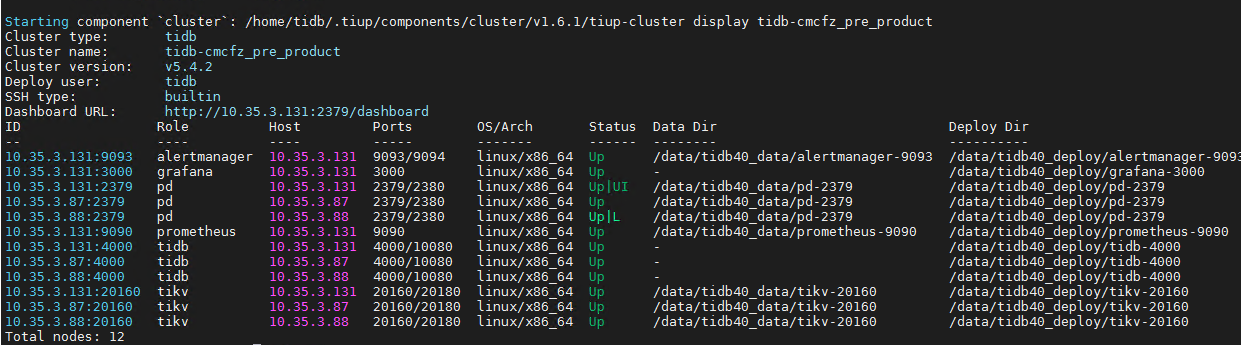
【 TiDB 使用环境】生产环境
【 TiDB 版本】5.4.2
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
tidb下午挂掉一个pd,修复后,现在发现br备份非常慢,就几十个g的东西,备份快30分钟才备份下来1 % 。。速度比以前慢很多。。重启集群后没有改善。几个节点的服务器各项资源是正常的。不知道br的这个日志warn 有没有问题
【资源配置】
最新补充:
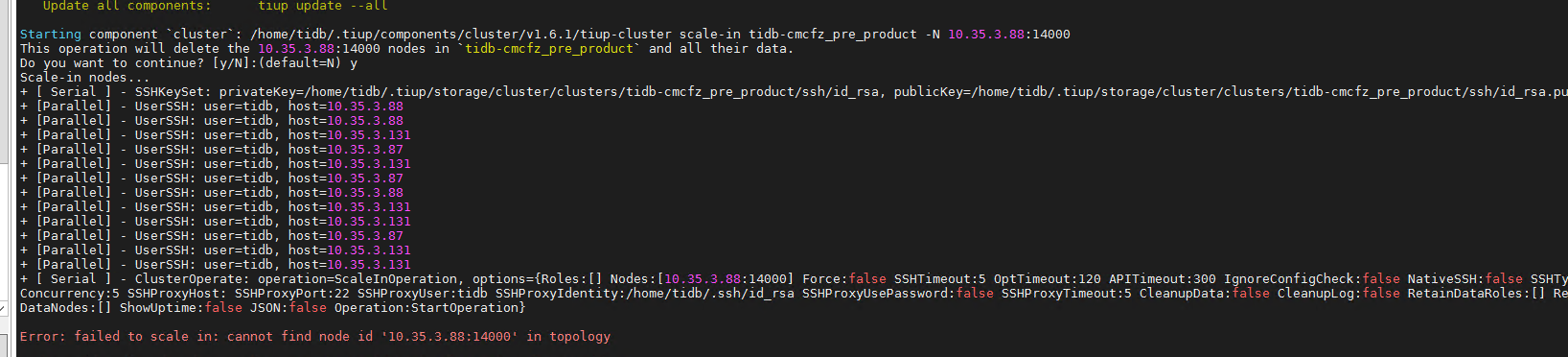
这2个离线的是另外一套集群的,当时在3.88上搭了个单机的tidb做测试,后来干掉了,不知道怎么这tidb 10.35.3.88:14000 和 tikv 10.35.3.88:21160 竟然还在这里 ,但是通过 tiup cluster display 是看不到的。通过scale-in 命令无法删除:
xfworld
(魔幻之翼)
2
查下 Store 17416 是哪个tikv 节点实例
最好通过gafana 看看集群的各项指标是否正常
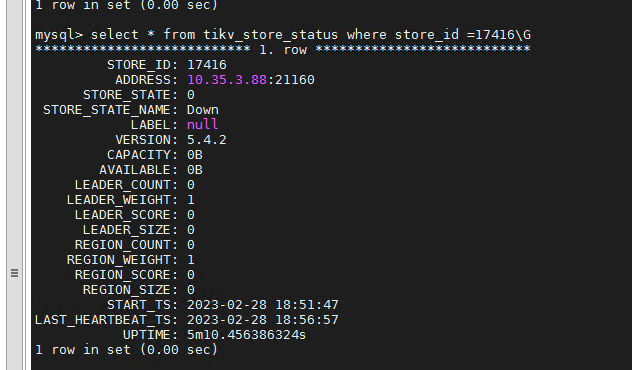
这个store在 3.88的21160 ,不在我这个集群里面我的集群tikv只有
3.131:20160
3.87:20160
3.88:20160
这个 3.88的21160 是在3.88上次临时搭了个测试,,是单节点的tidb集群,已经干掉了
ffeenn
(ThatBoy)
7
display看不到那2个奇怪的节点,,刚看到你说监控,我上去看了下才发现~
可是他们不在当前的集群列表里,我该怎么删掉那2个有问题的节点呢 
h5n1
(H5n1)
13
你测试的集群应该是也用了生产的PD ,先参考下面清理下看不到的那个tikv , 3.88上正常的tikv和不正常的tikv 端口 IP一样估计操作会有影响
14000这个tidb server 可以试试在 .tiup/storage/cluster/clusters/{cluster-name}/meta.yaml 里把他加上 然后再scael-in试试
那2个节点是 在3.88上部署的一套临时单机tidb 比如是集群B,测试用的, 我后来是整套destroy掉。但是通过监控发现那2个节点还遗留在生产集群A
system
(system)
关闭
19
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。