【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
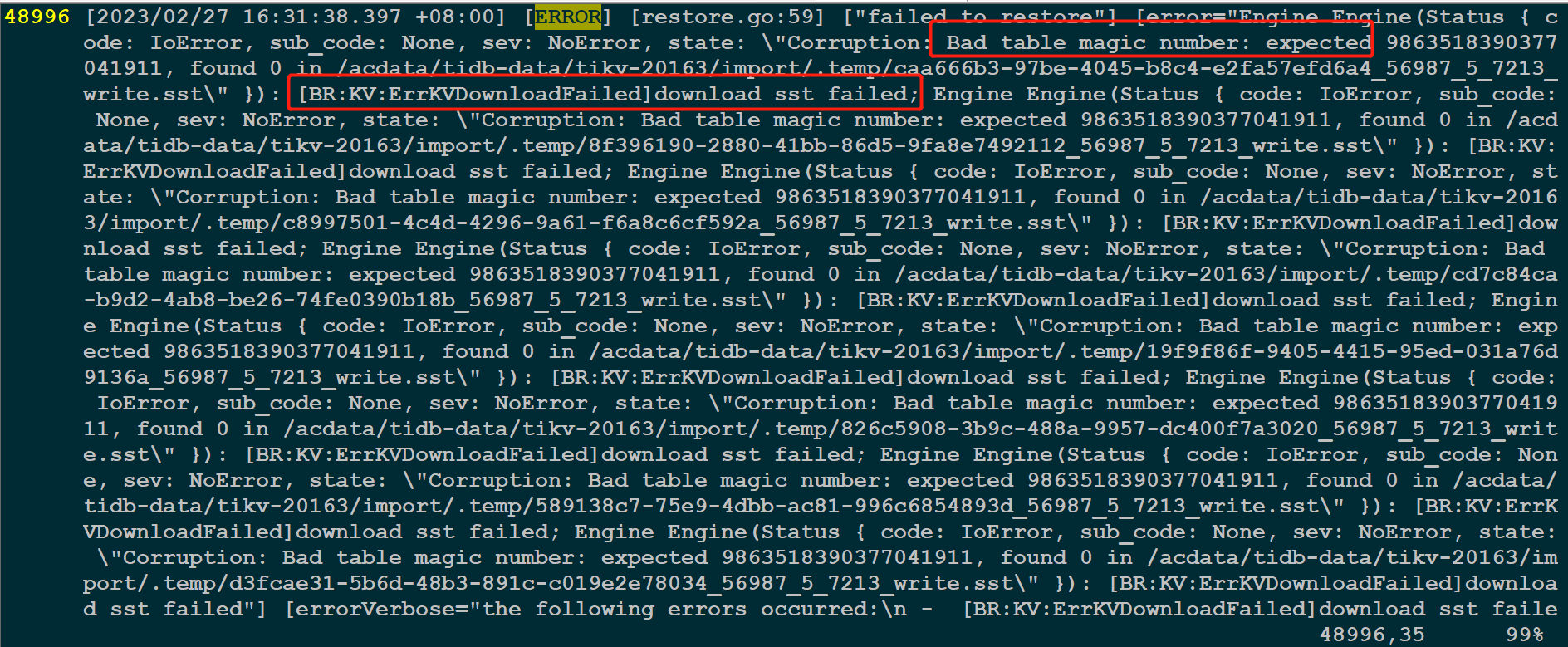
源库和目标库集群均为:v6.5.0版本,使用Br工具从源库导出一个schema,在导入到目标库时,报错:[2023/02/27 16:31:38.397 +08:00] [ERROR] [restore.go:59] [“failed to restore”] [error="Engine Engine(Status { c ode: IoError, sub_code: None, sev: NoError, state: "Corruption: Bad table magic number: expected 9863518390377 041911, found 0 in /acdata/tidb-data/tikv-20163/import/.temp/caa666b3-97be-4045-b8c4-e2fa57efd6a4_56987_5_7213_ write.sst" })
【资源配置】
【附件:截图/日志/监控】
BR工具是6.5版本的么?目标库是空库么?
两边的集群版本一样么 ![]()
目标库的每个tikv节点都能访问全量的备份吗?
倒是有个版本有这个bug,但是是5.4.0,现在这个版本应该早就修复了。https://github.com/pingcap/tidb/issues/30225
这个错误可能是由于SST文件的加密或解密出现了bug导致的。你还是需要检查一下你在使用BR时是否指定了正确的crypter.method和crypter.key参数。
看描述是目标库和源库都是6.5.0的
把您的备份 和 恢复命令 贴出来 看下
1.源库br版本:
[root@host-pro-tidb-02 tidb_source]# tiup br --version
tiup is checking updates for component br ...
Starting component `br`: /root/.tiup/components/br/v6.5.0/br --version
Release Version: v6.5.0
Git Commit Hash: 706c3fa3c526cdba5b3e9f066b1a568fb96c56e3
Git Branch: heads/refs/tags/v6.5.0
Go Version: go1.19.3
UTC Build Time: 2022-12-27 03:41:53
Race Enabled: false
2.目标库:
[root@TIDBserver/PD tidb_source]# tiup br --version
tiup is checking updates for component br ...
Starting component `br`: /root/.tiup/components/br/v6.5.0/br --version
Release Version: v6.5.0
Git Commit Hash: 706c3fa3c526cdba5b3e9f066b1a568fb96c56e3
Git Branch: heads/refs/tags/v6.5.0
Go Version: go1.19.3
UTC Build Time: 2022-12-27 03:41:53
Race Enabled: false
目标库和源库br工具版本均为v6.5.0,目标库为空库或创建空库均试过无效。
我是把源库上的每个kv节点的备份数据,统一拷贝到共享存储,然后,再从共享存储拷贝分发给目标库的每个kv节点。确认目标库的每个kv节点都可以访问备份数据集。
唯一不同的是,以前v5.4.0版本,全量备份库,在中控机上只生成:
backup.lock
backupmeta
而发6.5.0版本,全量备份库,在中控机上生成如下文件:
-rw-r--r-- 1 root root 78 Feb 27 19:03 backup.lock
-rw-r--r-- 1 root root 145K Feb 27 19:03 checkpoint.meta
drwxrwxrwx 4 root root 4.0K Feb 27 19:38 checkpoints
-rw-r--r-- 1 root root 12M Feb 27 19:43 backupmeta
在恢复到目标库里,这些在中控机产生的文件,也全部拷贝到目标kv节点吗?以前,我只拷贝 backupmeta到目标库的中控机上,进行恢复就可以。但是,v6.5.0版本尝拷贝 backupmeta或拷贝 backupmeta+checkpoints+checkpoint.meta进行恢复,均失败报同样的错误:
# [[ERROR] [restore.go:59] [“failed to restore”] [error=“Engine Engine(Status { c ode: IoError, sub_code: None, sev: NoError, state: \”Corruption: Bad table magic number: ](https://asktug.com/t/topic/1002365)
我只能先尝重新从源库备份一个新的全量数据,再进行恢复到目标库试试。
工具是v6.5.0的,那集群呢?两边的集群也都是v6.5.0么?
工具和集群版本,均为v6.5.0
重新备份还原一次试试呢?
1.重新从主库集群导出一份全量备份数据
2.将主库集群中的3个tikv节点的备份数据,统一拷贝到共享存储路径
3.再到目标从库集群中控机,将共享存储的备份数据,拷贝到目标集群的3个tikv节点
4.将源库中控机上的元数据备份打包,放到目标库中控机
5.解压后,删除backup.lock文件
6.在目标库,执行恢复命令,恢复成功
Detail BR log in restore_maindb.log
DataBase Restore <------------------------------------------------------------------------------------------> 100.00%
[2023/02/28 10:21:52.897 +08:00] [INFO] [collector.go:73] ["DataBase Restore success summary"] [total-ranges=21468] [ranges-succeed=21468] [ranges-failed=0] [split-region=17.813182634s] [restore-ranges=15822] [total-take=43m38.814035736s] [total-kv-size=1.256TB] [average-speed=479.8MB/s] [restore-data-size(after-compressed)=170.2GB] [Size=170231634541] [BackupTS=439745457928536072] [RestoreTS=439758983396851713] [total-kv=5317257434]
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。