【 TiDB 使用环境】生产环境
【 TiDB 版本】 6.5.0
【复现路径】
刚从mysql迁移过来,很多不明白。
单机tidb数据库(虽然使用3KV)环境。
建立了一个大表,有近4千万行数据,此时,使用select * from mytable limit m,n时(分页查询),当m大于1千万,查询变量非常慢。表中默认使用id主键、自增(我知道tidb不太推荐使用自增主键)。
【遇到的问题:问题现象及影响】
一次查询可能需要30s及至更多的时间,请问应当如何优化。我尝试使用了mysql中的技巧(如inner join,它会使用count(*)非常慢),没有达到效果。
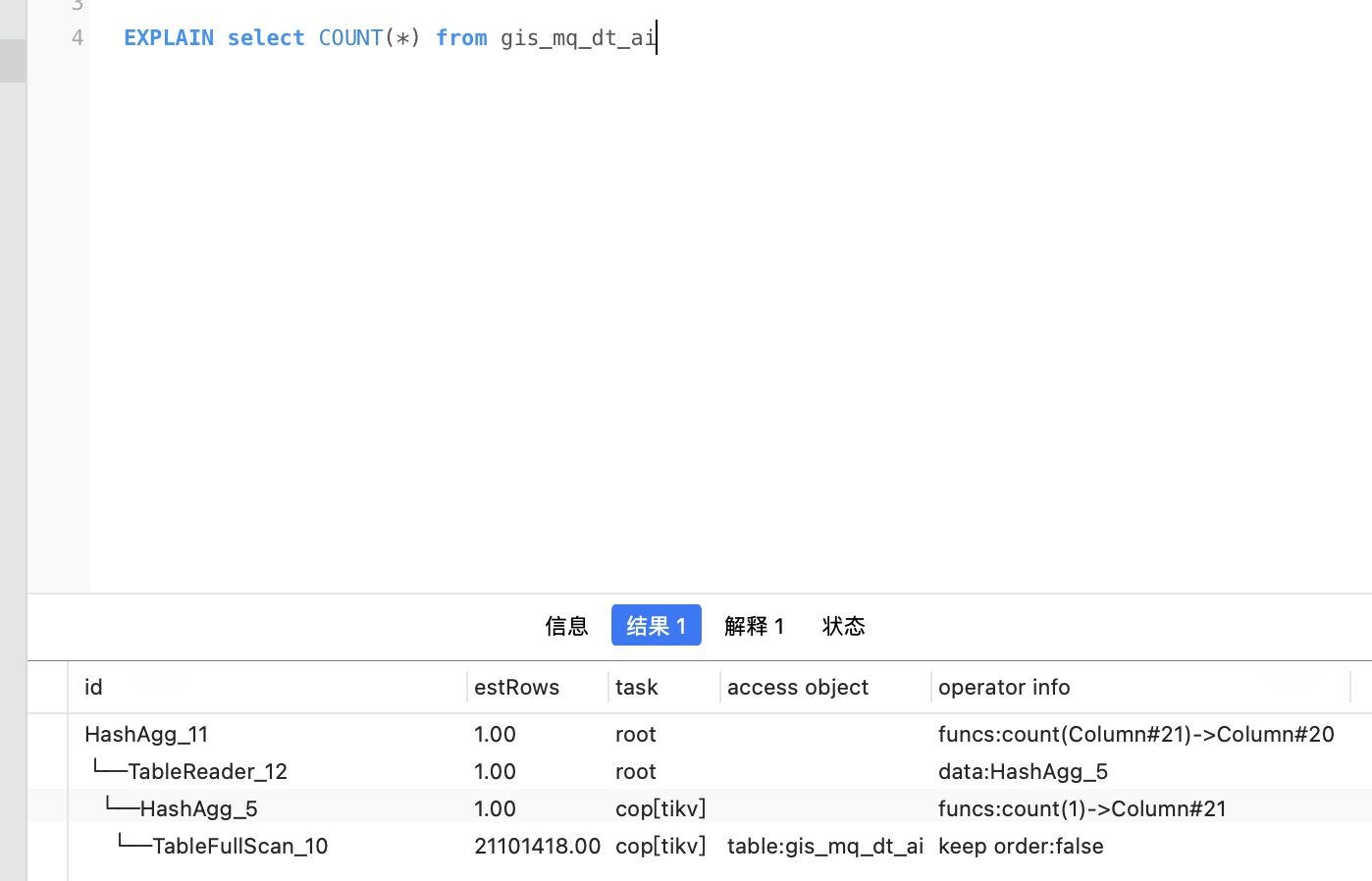
另,我注意到count(*)仍然是全表扫描,但比mysql快多了,似乎也没有使用索引,原理是什么?
谢谢!
【资源配置】
【附件:截图/日志/监控】
可以考虑先用limit查主键,然后用id in查所有数据,如
select * from mytable where id in(
select id from mytable limit m,n).
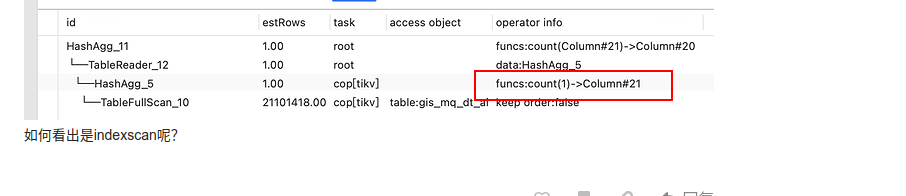
补充: count() 是IndexFullScan, select * 是TableFullScan,所有count()会快
啦啦啦啦啦
4
深度分页问题有几种优化方案,比如建独立的分页表,分页列这种。可以看看304或者307的深度分页案例这一课,讲的很详细。
1 个赞
并不能优化查询!因为它仍然要从到最后去取数据!结果更慢啊
@啦啦啦啦啦 请问304
或307的课在哪里看呢?谢谢!
啦啦啦啦啦
8
count(*) 会优化为count(1) 只需要扫主键即可(mysql原理类似,tidb可以利用集群优势可能会快一些)
Explain我用的5.0.3,可以看到IndexFullScan,你的6.5执行过程应该不会有大的调整,可能展示的信息作了些调整
执行时间你可以验证下
limit m, n, 当m大时,慢的原因是因为数据库要扫描前n+m行的整行数据(TableFullScan),m越大,扫描的数据越多,也就越慢;
换成id,是利用一级索引,减少扫整行数据的开销(IndexFullScan),之后再利用查询到的主键查询n行完整的数据(PointGet)。
你是对的,我开始使用的csv导入表,没有索引。但居然也很快!
注意到count()仍然是全表扫描,但比mysql快多了,似乎也没有使用索引,原理是什么?
这就是分布式数据的优势,MySQL单机数据库 count() 只能利用一个存储节点聚合数据,tidb 有多个数据存储节点(tikv)一起聚合数据,每个tikv聚合部分数据,然后到tidb节点汇总数据,这样可以充分利用算子下推带来的好处