TiSpark 服务安装 部署 测试
- pingcap/TiSpark 项目地址,使用前阅读以下文档
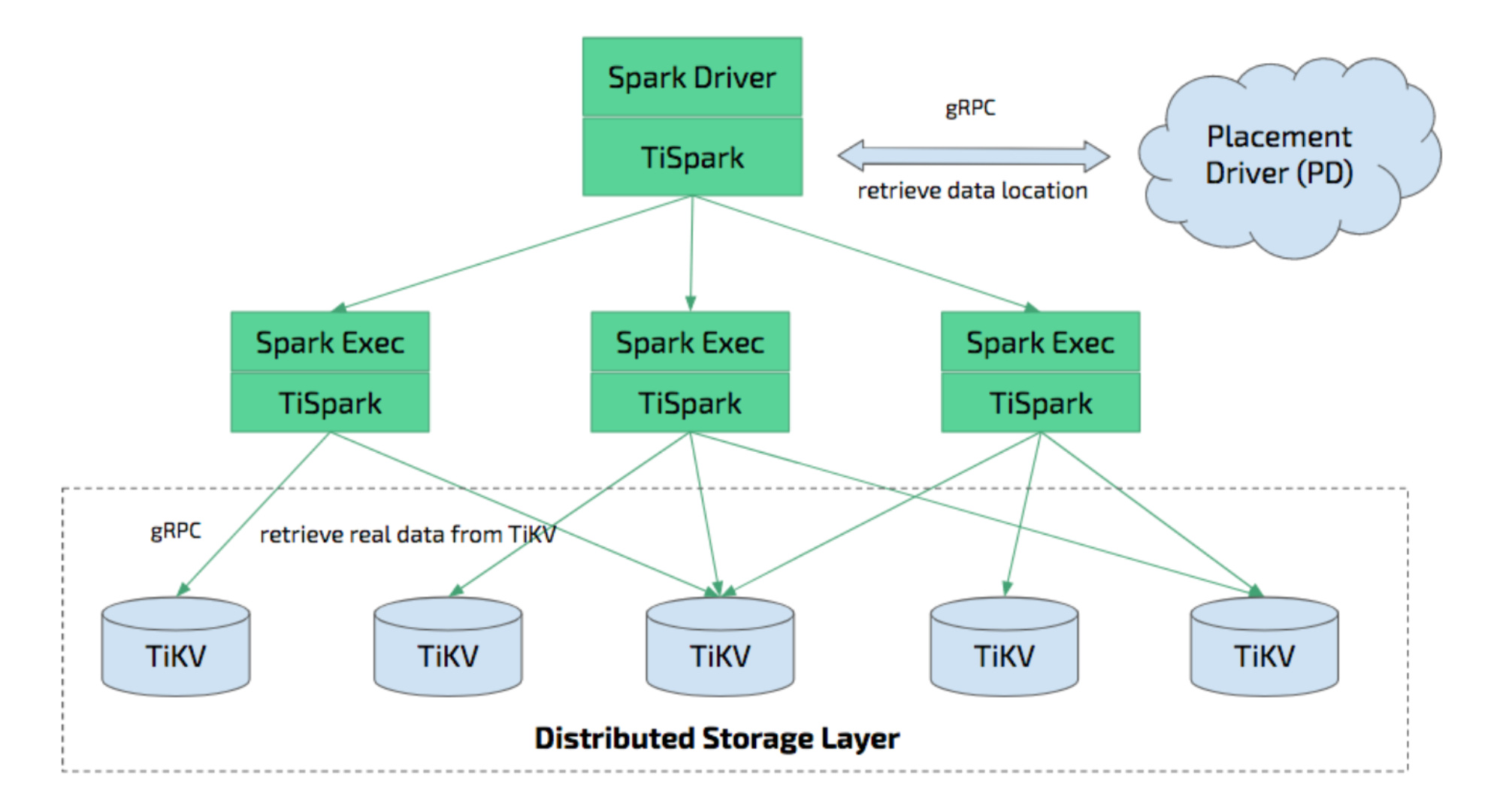
部署 TiSpark 集群
TiDB-Ansible 与 TiSpark 的关系
tidb-ansible/roles/local/templates/binary_packages.yml.j2下载连接- 此处为 tispark 下载连接,jar 包下载 传送门
tidb-ansible/conf/spark-defaults.yml- tispark 配置文件信息,文件配置示例 Github 格式为
key: value
- tispark 配置文件信息,文件配置示例 Github 格式为
tidb-ansible/roles/tispark/tasks/main.yml- 此处为 tispark 安装步骤
部署 TiSpark 准备
- 确定目标节点已经安装 java 1.8 以上版本
- 在目标节点执行
java -version查看
- 在目标节点执行
- 修改 inventory.ini 文件
- spark_master 与 spark_slaves 为空时,默认安装在第一台 tidb
/spark目录下,该安装模式为 standalone - 以下为 spark 安装示例,非 standalone 模式
- spark 默认安装为 standalone cluster
- spark standalone cluster 模式下,master 不参与实际数据处理工作
- spark_master 与 spark_slaves 为空时,默认安装在第一台 tidb
[spark_master]
spark-master ansible_host=172.16.10.64 deploy_dir=/data3/deploysparkmaster
# 手动指定 spark deploy dir 时,名字请勿以 `spark` 或者 `spark-` 开头
# 第一次安装失败或者中断后,请删除每个节点上的 spark 目录(包含 spark 本级),然后重新执行 ansible-playbook deploy.yml
[spark_slaves]
spark-64 ansible_host=172.16.10.64 deploy_dir=/data3/deploy
# 单机部署 master + slave 并不会造成端口冲突 / 可以有效复用计算资源
spark-65 ansible_host=172.16.10.65 deploy_dir=/data3/deploy
spark-66 ansible_host=172.16.10.66 deploy_dir=/data3/deploy
注意:以下参数中有部分参数需要新版本才能使用 (2018 年 6 月之后的版本) 最新 spark 参数请关注 spark-default.yml
- TiSpark 配置文件参数说明,按实际需求进行修改
tidb-ansible/conf/spark-defaults.yml- 已经安装 Spark ,修改
/spark/conf/spark-defaults.conf(可使用默认配置)
- 已经安装 Spark ,修改
spark.tispark.table.scan_split_factor 2
# 每个 Region 被切割成多少块,比如 8 就是说一个 Region 切 8 块;默认一个 Region 一个块
spark.tispark.task_per_split 4
# 每个 Spark Task 使用多少并发量去并行读取块
spark.locality.wait 0s
# spark 每次调度等多久,等一个本地计算
spark.tispark.pd.addresses 172.16.10.64:2379,172.16.10.65:2379,172.16.10.66:2379
# 指定 PD 信息
spark.tispark.grpc.framesize 1564087970
spark.tispark.grpc.timeout_in_sec 100
spark.tispark.meta.reload_period_in_sec 60
spark.tispark.plan.allowaggpushdown true
spark.tispark.index.scan_batch_size 500000
spark.tispark.index.scan_concurrency 2
spark.tispark.table.scan_concurrency 256
# 新版本下分别控制索引 / 扫表读取的并发线程数
spark.tispark.request.command.priority Normal
# 新版本下对 TiKV 请求的优先级,如果是 OLTP 集群,请设定为 Low ,大小写敏感,可选有 High,Normal,Low
spark.sql.extensions: org.apache.spark.sql.TiExtensions
# spark 自动引入 tispark 功能,该参数需要 2018 年 8 月后版本支撑
tidb-ansible/conf/spark-env.ymlspark 环境变量信息- 已经安装 spark 的修改 /conf/spark-env.sh 文件,也可通过命令行参数进行覆盖指定
- 根据机器配置调整 spark 所占用的 CPU & RAM,示例如下:
SPARK_EXECUTOR_CORES=5
# 控制每个 Executor 占用多少 cores
SPARK_EXECUTOR_MEMORY=5g
# 控制每个 Executor 占用多少内存,机器无其他服务时,建议总内存 80%
SPARK_WORKER_CORES=5
SPARK_WORKER_MEMORY=5g
开始安装 TiSpark
TiDB 目前默认已安装一台 spark 节点。以下为安装 spark cluster 。需要编写 inventory.ini,在 master_spark & slaves_sparks 填写目标主机信息
- 初始化 master_spark & slaves_sparks 目标主机信息
- 执行
ansible-playbook -i inventory.ini bootstrap.yml -l master_spark,slaves_spark
- 执行
- 单独安装 spark 组件
- 执行
ansible-playbook -i inventory.ini deploy.yml -l master_spark,slaves_spark
- 执行
运维 TiSpark
- 启动 / 停止:启动停止时 playbook 不会检测中间过程状态,需要人工通过 http:// masterip:8080/ 检查 spark cluster 状态
- 执行
ansible-playbook -i inventory.ini start_spark.yml启动集群 - 执行
ansible-playbook -i inventory.ini stop_spark.yml启动集群
- 执行
测试 TiSpark 服务
TiSpark 相关端口 & IP
- 注意防火墙放通以下端口: 8080,8081,7070,7077,4040
- 网页: http://172.16.10.64:8080
- 通信端口: spark://172.16.10.64:7077
- PD 集群: 172.16.10.64:2379,172.16.10.65:2379,172.16.10.66:2379
运行方式如下(注意自己安装的 Spark 版本再执行)
- 通过 TiSpark-SQL 运行
- 下载 TiSpark-SQL 传送门
- 将文件保存导
/spark/bin下,赋予执行权限
- 登陆 172.16.10.64 机器
- 进入目录
cd /data3/deploy/spark/bin - 执行
./tispark-sql - 直接输入 sql 语句,如
show databases;
spark 2.1.1 版本以及 2018 年 6 月份之前 tispark jar 包使用该步骤
- 通过 spark-shell 运行
- 登陆 172.16.10.64 机器
- 进入目录
cd /data3/deploy/spark/bin - 执行
./spark-shell
import org.apache.spark.sql.TiContext
val ti = new TiContext(spark)
ti.tidbMapDatabase("mysql") // 将数据库 mysql 中的所有表映射为 Spark SQL 表,在当前会话中只能映射一个数据库,重复无效
// 如果数据库下表比较多,可以使用 tidbMapDatabase("tpch", autoLoadStatistics = false) // autoLoadStatistics = false 该参数不加载统计信息,在不适用 index scan 的情况下无碍
spark.sql("show tables").show(truncate=false) // 查看当前数据库下所有表信息
- 如果使用 2.1.1 spark 配合 2018 年 6 月份以后 tispark jar 包,直接执行
spark.sql("show schemas").show()只会出现一个 default database 现象,通过以上步骤引入 tispark jar 后,执行spark.sql("use mysql").show()、spark.sql("select count(*) from user").show()会出现错误堆栈
Spark 2.3.2 版本
- 通过 spark-shell 运行
- 登陆 172.16.10.64 机器
- 进入目录
cd /data3/deploy/spark/bin - 执行
./spark-shell
spark.sql("show schemas").show
spark.sql("use mysql").show
spark.sql("show tables").show
- 替换
spark.sql("show tables").show该命令中的show tables即可执行 SQL 查询。 - TiSpark 目前仅支持查询,暂不支持回写。回写需求请发邮件至 (support # pingcap.com) 或通过其他方式联系 PingCAP 官方支持
第三方工具连接 TiSpark
- 可以使用 jdbc 连接 TiSpark 服务
- 下载 ThriftServer 脚本 传送门
- 将脚本复制到 /scripts/start-tithriftserver.sh
- 执行脚本启动 jdbc 服务器
- ThriftServer 提供 JDBC 访问入口, 适合 SQL workbench 之类的辅助 GUI 访问, 也可以使用 Hive Beeline 工具(但是实测下来仅限于 Hive 1.2 的 Beeline)
- 其他工具
- zeppelin
- submitjob
使用 zeppelin 远程链接 Spark
安装 zeppelin
Zeppelin 目前已托管于 Apache 基金会,但并未列为顶级项目,可以在其公布的官网访问。
它提供了一个非常友好的 WebUI 界面,操作相关指令。它可以用于做数据分析和可视化。其后面可以接入不同的数据处理引擎。包括 Flink,Spark,Hive 等。支持原生的 Scala,Shell,Markdown 等。
官方提供更多安装方式,详情查看Using the official docker image
- 使用清华开源镜像站下载 Zeppelin
https://mirrors.tuna.tsinghua.edu.cn/apache/zeppelin/
- 配置 conf/zeppelin-env.sh 将 SPARK_HOME 指向当前机器上的 SPARK 地址,例如
export SPARK_HOME=/Users/ilovesoup1/workspace/spark-2.1.1-bin-hadoop2.7
- 检查 jackson 相关 JAR 包
ls -al $SPARK_HOME/jars/jackson-*查看 spark- 如现有版本比 Spark 内置版本旧,删除原有版本,用 spark/jars 下如下文件替换
- zeppelin-0.7.3-bin-netinst/lib
jackson-annotations-2.6.5.jar
jackson-core-2.6.5.jar
jackson-databind-2.6.5.jar
- 启动 Zeppelin 服务
- 服务将在本地 8080 启动
./bin/zeppelin-daemon.sh start
- 浏览器访问
http://zepplineserver:8080
- 点击 Create New note, 选中 Default Interpreter Spark
- 在页面中像 spark-shell 中一样测试
import org.apache.spark.sql.TiContext
val ti = new TiContext(spark)
ti.tidbMapDatabase("test")
%sql show tables
- 点击 Shift+Enter 观察结果
FAQ
import tisaprk 失败问题(早期版本)
- 第一次测试 spark-shell 时,如遇见以下问题,请检查
/spark/conf/spark-defaults.yml文件中是否有正确使用spark.tispark.pd.addresses:参数。java.util.NoSuchElementException: spark.tispark.pd.addresses
scala> import org.apache.spark.sql.TiContext
import org.apache.spark.sql.TiContext
scala> val ti = new TiContext(spark)
java.util.NoSuchElementException: spark.tispark.pd.addresses
at org.apache.spark.SparkConf$anonfun$get$1.apply(SparkConf.scala:243)
at org.apache.spark.SparkConf$anonfun$get$1.apply(SparkConf.scala:243)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.SparkConf.get(SparkConf.scala:243)
at com.pingcap.tispark.TiUtils$.sparkConfToTiConf(TiUtils.scala:175)
at org.apache.spark.sql.TiContext.(TiContext.scala:36)
... 48 elided
scala>
index 下推
- 查看是否开启 index 下推
spark.conf.get("spark.tispark.plan.allow_index_read")
- 如果是 false,通过以下语句修改
spark.conf.set("spark.tispark.plan.allow_index_read", "true")