为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】: V2.1.1
- 【问题描述】:tikv节点共三台服务器(阿里云ecs),其中两台的配置是cpu8 16G内存,固态硬盘300G,另外一台的配置是cpu4 16G内存,固态硬盘 300G 、现在我发现这个太配置的服务器CPU负载一直是慢的,另外两台配置高的服务器负载很低,这是什么问题?不是应该一样或者差不多吗?(在配置低的服务器上通过stop_tikv.sh停止tikv服务后。另外两个节点负载才上来,等过来半个小时后,我在起来这个tikv服务,过2分钟后发现CPU负载又满了,另外两台的负载就降下来了)请看下面的截图:
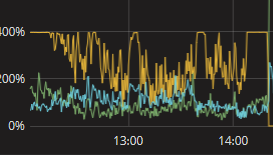
有没有办法通过 pd-ctl 将负载高的请求转到其他服务器上?
另外我还发现,在负载高的服务器上,流量也是非常高的,如下图:
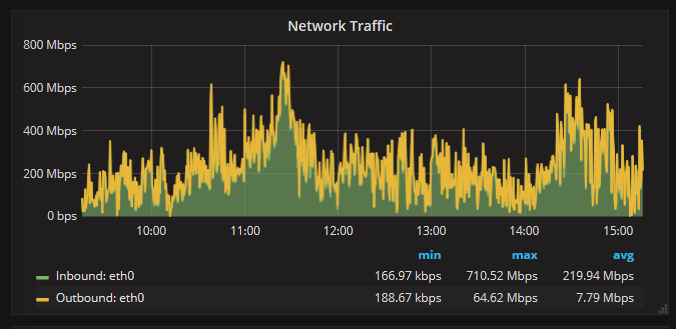
最近tidb搞的快崩溃了,就是定位不到地方,官网上说的优化和调整也试过了,就是没效果,苦恼!苦恼!苦恼!
如果可以,我把grafana连接和账户发给你们,你们协助看看什么原因引起的。