TiKV知识整理
1、TiKV简介
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
2、TiKV整体架构
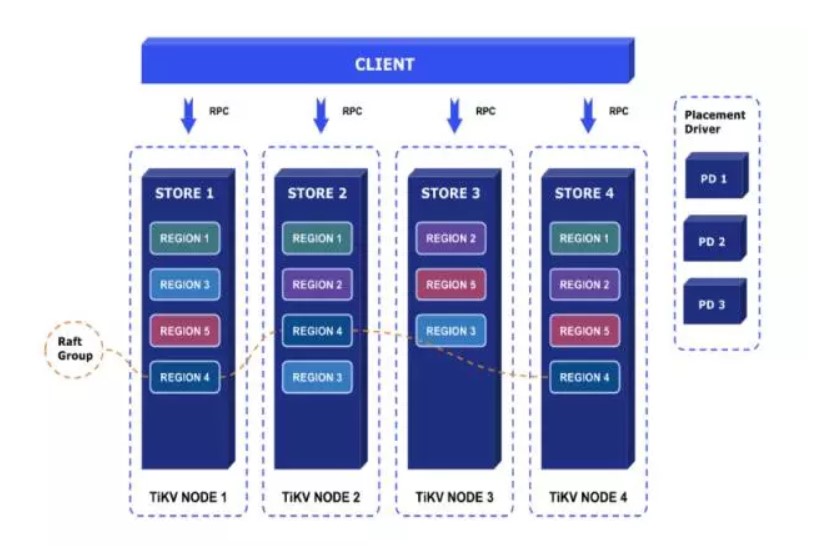
Placement Driver : Placement Driver (PD) 负责整个集群的管理调度。
Node : Node 可以认为是一个实际的物理机器,每个 Node 负责一个或者多个 Store。
Store : Store 使用 RocksDB 进行实际的数据存储,通常一个 Store 对应一块硬盘。
Region : Region 是数据移动的最小单元,对应的是 Store 里面一块实际的数据区间。每个 Region 会有多个副本(replica),每个副本位于不同的 Store ,而这些副本组成了一个 Raft group。
此处信息来自知乎“TiDB的后花园”,我主要说一下自己对store、raft group的理解,分布式事务、Coprocessor部分知识暂不包含。
3、Store
Store主要用于存储数据,tidb通过RocksDB作为单机存储引擎。
RocksDB是基于LevelDB优化的,是一个基于LSM-Tree的持久化key-value单机存储引擎,支持MVCC。
LSM-Tree是SSD友好,存在写放大的劣势,Tidb通过Titan键值分离来减小写放大。
键值分离,通过将大value分离出LSM-Tree以减少写放大。比如存在一个key为16B,value为1KB,写放大为40倍,如果键值分离,实际大小就是40*16+1024=1664,放大倍数为1664/(16+1024)=1.6倍,远远小于原来的40倍。但是这样的缺点是因为value被放在了另外单独的文件中,需要额外的I/O消耗;范围查询需要随机I/O。
4、Region
每个 Region 负责维护集群的一段连续数据(默认配置下平均约 96 MiB),每份数据会在不同的 Store 存储多个副本(默认配置是 3 副本),每个副本称为 Peer。同一个 Region 的多个 Peer 通过 raft 协议进行数据同步,所以 Peer 也用来指代 raft 实例中的成员。TiKV 使用 multi-raft 模式来管理数据,即每个 Region 都对应一个独立运行的 raft 实例,我们也把这样的一个 raft 实例叫做一个 Raft Group。
Peer有三种状态,初始状态都为follower,follower长时间未接收到leader的心跳后,会转变为candidate发起选举,如果能收到绝大多数follower的投票,就会变为leader,成为leader后会有一个term,如果发现当前集群中有其他leader的term更大,就又会变回follower。(这只是最基础的leader选举,更详细的请参考官方文档)
所有的日志都是从leader复制到follower的。
Multi-raft就是多个raft group组合,他可以帮助数据库实现数据的负载均衡,合并,分裂等,multi-raft工作的基本策略是:
副本数不足(不均衡)–寻找有富余的节点,AddPeer
磁盘空间不足(不均衡)–寻找有富余的节点,MovePeer
计算资源不足(不均衡)–寻找空闲的节点,TransferLeader
Region包含数据过多—分裂,Split
小Region太多—合并,Merge
小结
TiKV通过PD调度,将数据以多副本的形式存放在多个节点当中,每次提交前提是多半以上的副本收到数据,这样保证了只要不是半数以上的副本丢失,就不会出现数据丢失。