- 【系统版本 & kernel 版本】centos7.5
- 【TiDB 版本】2.1.16
- 【集群节点分布】
57 pd/db/kv
56 pd/db
55 pd/db
81 kv
83 kv - 【数据量 & region 数量 & 副本数】
数据量1T,region 7.7W - 【问题描述(我做了什么)】
昨天kv节点down掉2个,通过unsafe-recover操作恢复,并扩容了2个kv节点,现在数据库查询单条语句,比如:select * from t1 limit 1比较慢,但是还是能够返回结果,但是使用count(*)就报TiKV server timeout。请各位大佬帮忙看看。

1 个赞
原来是三个 TiKV , 昨天 down 掉两台后,进行了恢复,并又重新扩容了两台,现在正常的 TiKV 应该是 5 台? 使用 pd-ctl -u http://pd:2379 -d store 看下现在是否有离线的 store
1 个赞
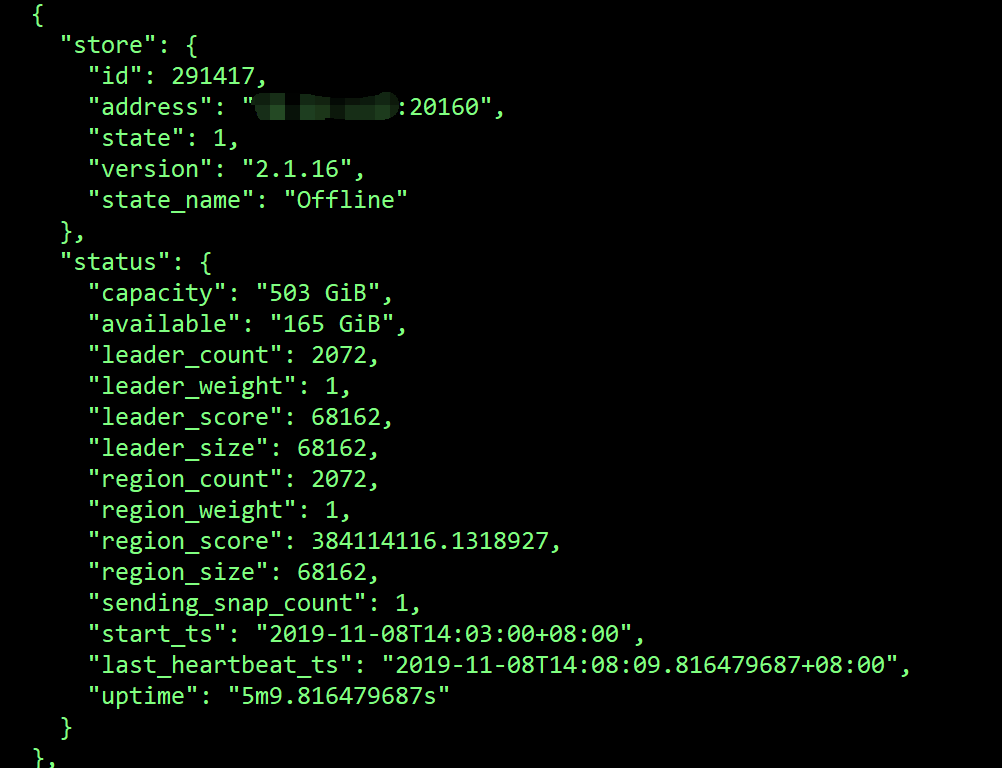
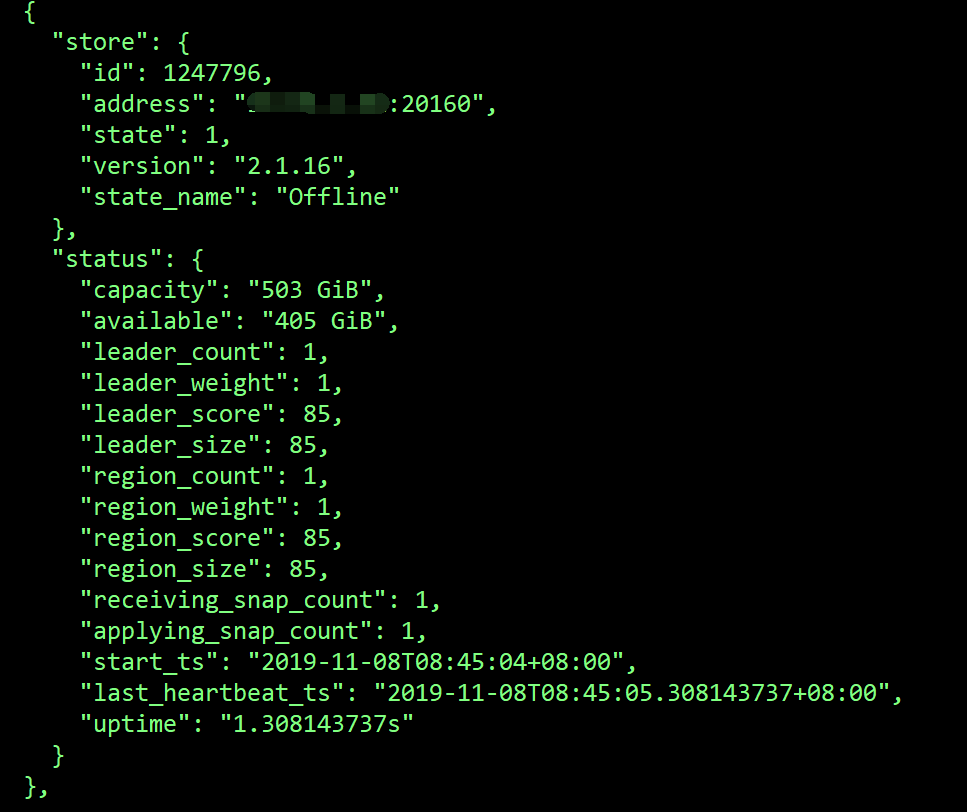

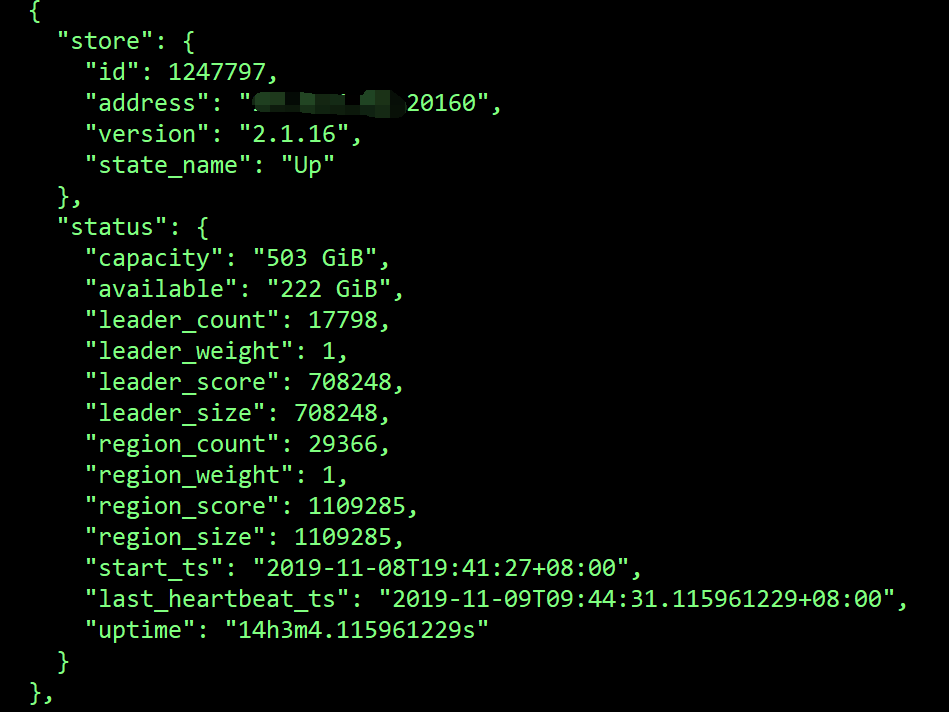
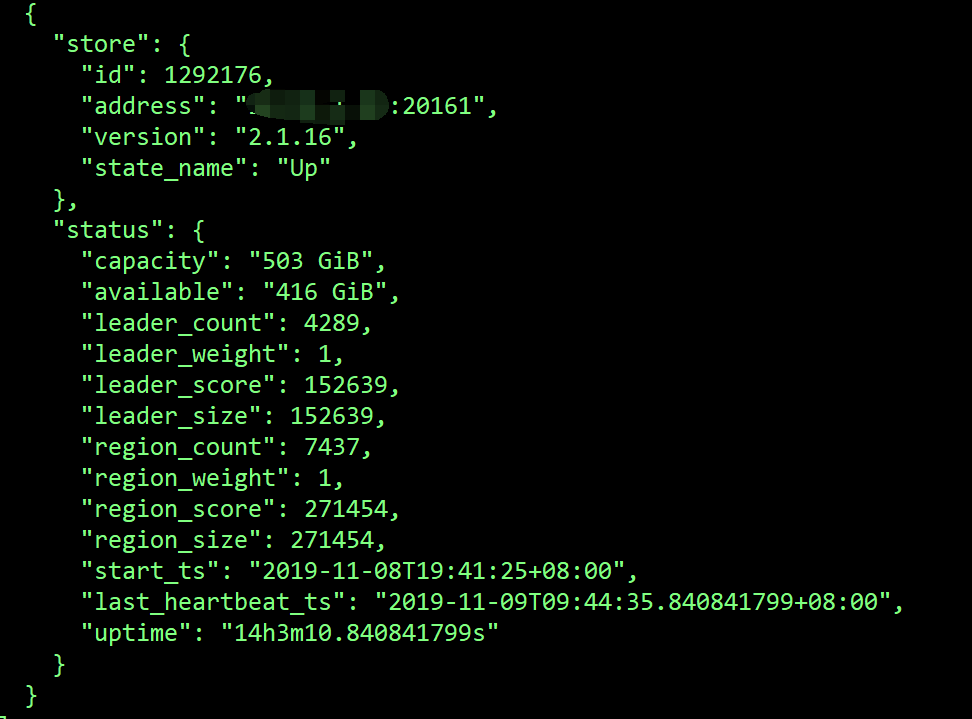
其中1247796,291417这2个store的region一直没变,1292176的region补副本很慢。
在tidb日志中还有很多Region is unavailable[try again later]错误
请仔细查看文档,
- 缩容要等状态变成 Tombstone 状态才能把它们停掉
- 另外原本只有 3 个 TiKV ,你再缩容肯定有问题,应该先扩容再缩容
那两个下线的 TiKV 你是停掉了吗,停掉了的话,启动一下,或者重启一下集群。 现在看起来就是这两台上的 region peer 有丢失。
1 个赞
一开始有4个tikv节点,分别是55,56,57,83 7号凌晨4点50,down掉2个tikv,分别是55,56。查看日志发现tikv不停的报错重启,然后我delete掉store,等了大概3个小时,发现delete的节点region一直没有变化,tikv还是不停的再报错重启。然后我通过unsafe-recover去掉了那2个节点,重新扩容了2个tikv节点81,82。 7号晚上19点,发现又有一个tikv不停的报错重启,状态和55,56一样。然后我继续通过unsafe-recover操作去掉了这个节点。现在节点就是57,81,83,到了8号中午83节点也不停的报错重启,这次没有通过unsafe-recover操作,我delete掉这个节点,发现region不调度,然后通过改端口再83节点又起了一个tikv节点,发现磁盘空间不够,我删掉了整个83节点上的tidb目录,重启了一个tikv节点,然后通过unsafe-recover操作去掉了原来再83上的store,现在tikv日志不再报错,但是就是返回超时和region不可用。 老师可以看一下这个帖子https://asktug.com/t/tikv-down/1673/29
1 个赞
这是整个事件的经过,一开始tikv挂掉,现在报错信息不一样,我就重新开了一个帖子。
看下 pd leader 日志,或者 PD 监控 - operator 中看看 Schedule operator create 和 Schedule operator finish
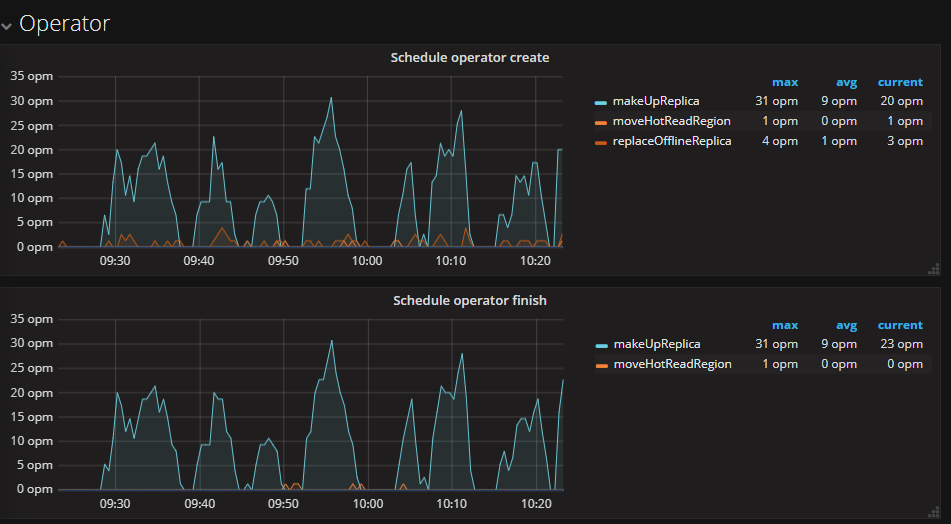
老师这种情况已经造成集群无法提供服务了,我能将数据备份下来重新搭建集群吗,我想这样会快一些。 但是用mydumper备份报错。老师有没有其他的方式保证数据不丢啊,真的很急啊。麻烦老师了
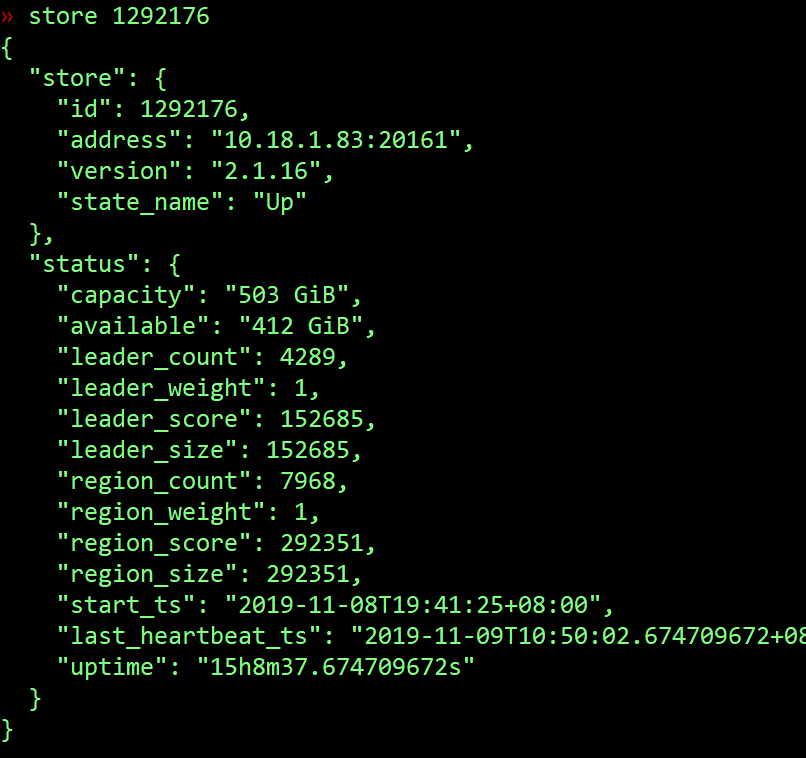
pd-ctl config show all 也贴一下
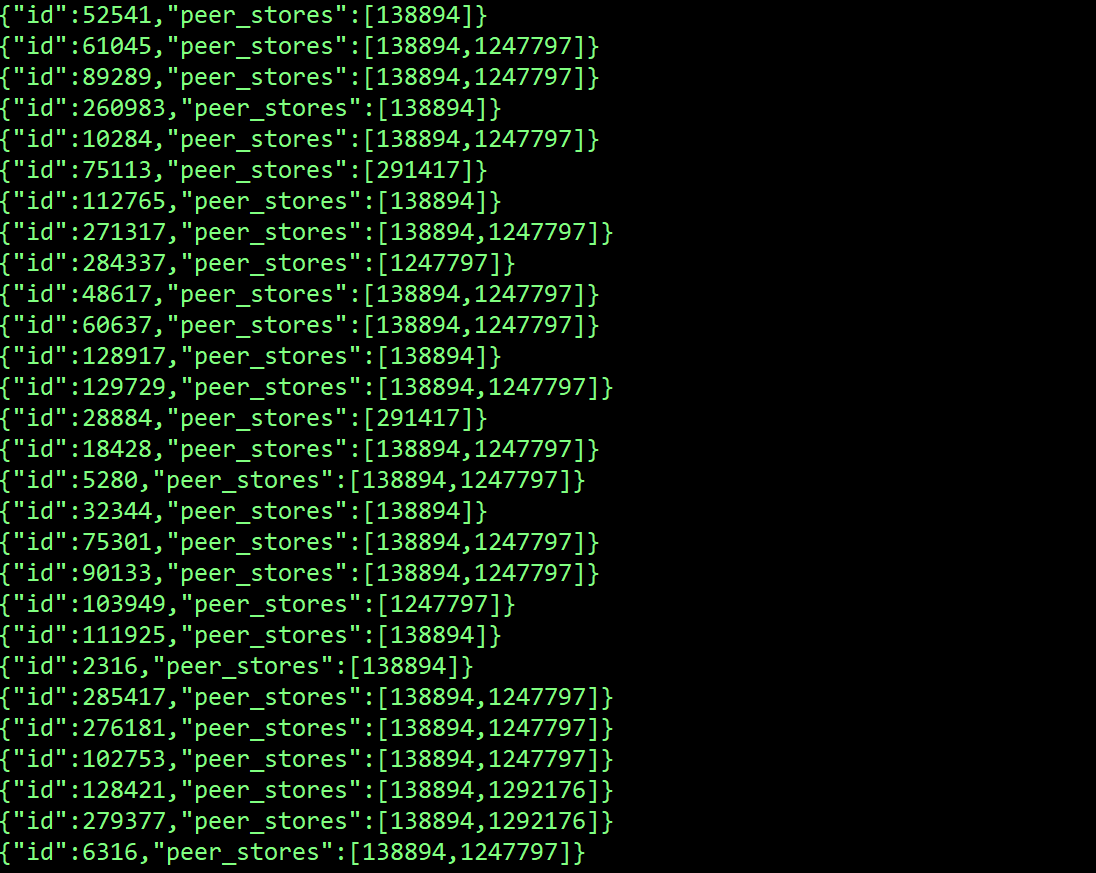
pd-ctl region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length != 3)}" 看下这个结果
麻烦把 pd 的监控导出成 pdf 发我一份吧
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total | map(if .==(291417,1247796) then . else empty end) | length>=$total-length) }"
1 个赞