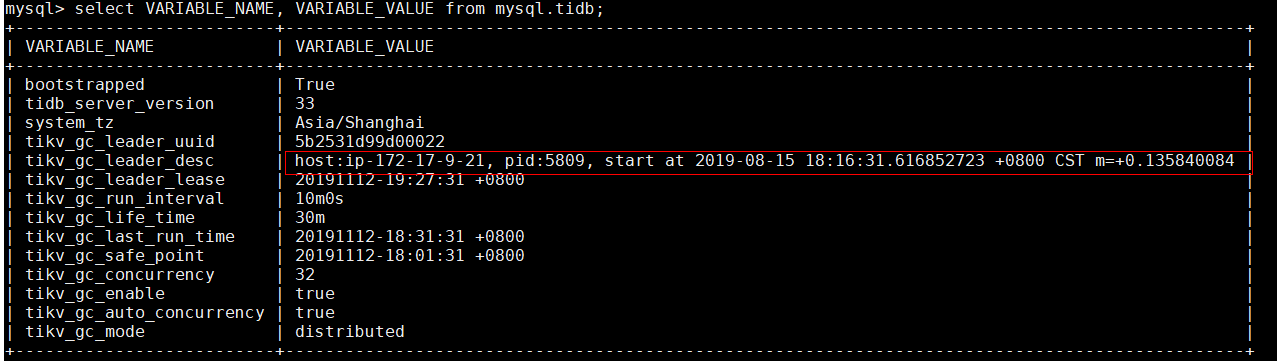
还没有重启,我们的gc leader tidb节点是没有客户端连接的。重启大概需要多久,对业务有没有影响呢?
还有 tikv_gc_concurrency 这个参数我计划修改为8,然后关闭 tikv_gc_auto_concurrency,这样配置是否合适?
还没有重启,我们的gc leader tidb节点是没有客户端连接的。重启大概需要多久,对业务有没有影响呢?
还有 tikv_gc_concurrency 这个参数我计划修改为8,然后关闭 tikv_gc_auto_concurrency,这样配置是否合适?
如果那台 tidb 节点上没有跑业务查询,那么重启它就不会对业务有影响。重启一个进程很快的。不过重启后另一台 tidb 会当选 gc leader。
3.0 默认配置下会以 tikv 节点的个数作为 concurrency ,并且只会影响 resolve lock 阶段的线程数。修改该配置应该意义不大。
我们已经确认之前的 tikv panic 是因为一个 merge 的 bug,导致 gc 卡住的问题是另一个 merge 的 bug,两个 bug 都已修复。建议升级到 3.0.5 。
我们之后会再做一些修改来保证 gc 不会因为这种原因而卡住。
打扰了!!!
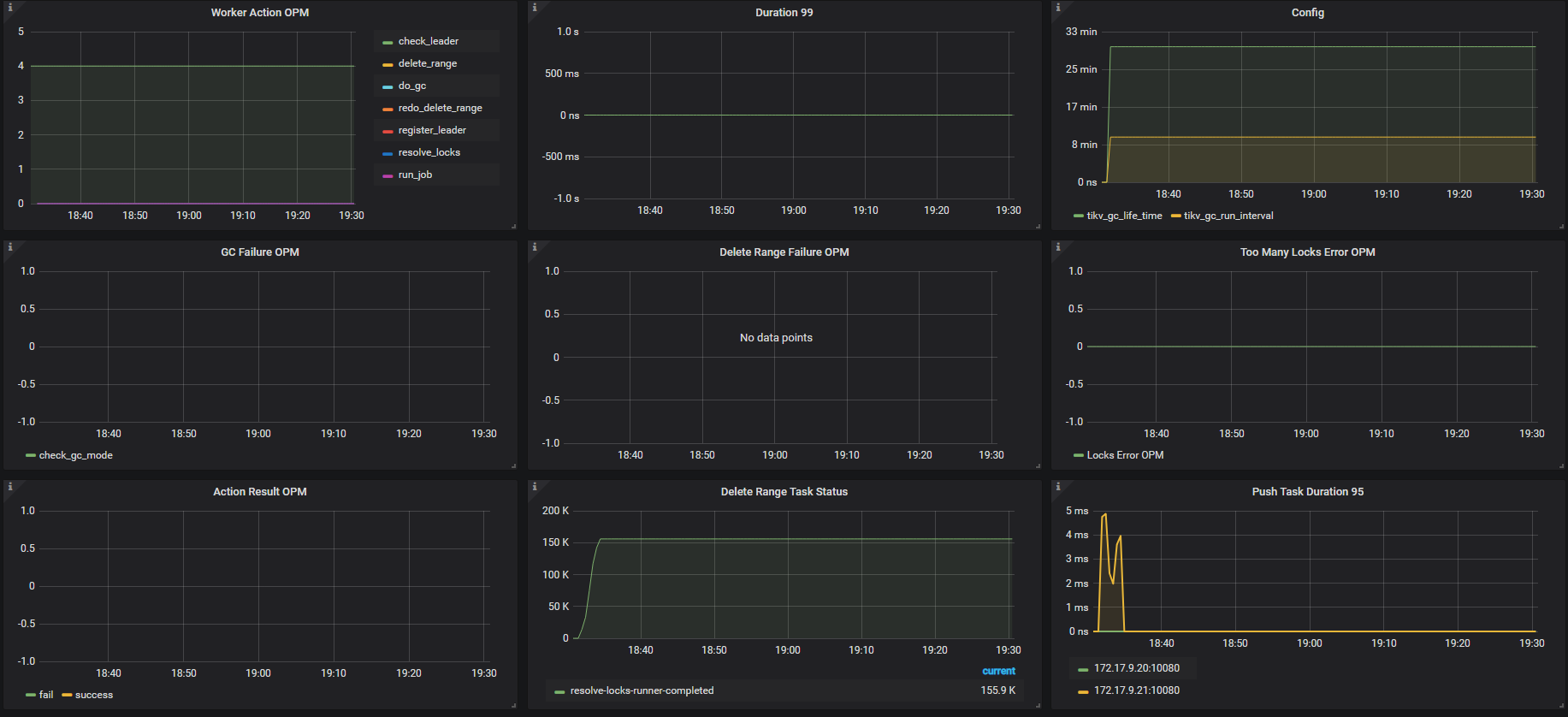
在下午6点半的时候,我们重启了那个TiDB节点,可以看到 gc leader节点变更为另外一台服务器了。
但问题是,差不多一个钟过去了,与GC相关的任何指标没有什么变化
tidb_172.17.9.21.log.gz (872.1 KB) tikv_172.17.9.30.log.gz (2.8 MB)
这个 merge 的 bug 之前造成了 gc leader 的 region cache 的问题,重启没有回复的话看来是不止一个 tidb 的 region cache 出了问题。现在的情况是那个 merge 的 bug 导致有一对 region 在两台 tikv 上成功 merge 了,但是还有一台机器上迟迟没有 merge。后面的这些问题都是这个原因导致的。建议尽快升级到 3.0.5 吧。
那现在的处理办法是什么?把其他的TiDB节点依次重启么。
建议升级到 3.0.5
还是说有什么困难无法升级吗?
我的疑惑是在这个问题还没有处理完之前直接就升级会不会产生更多的问题?还是说这个问题只有通过升级才解决?
事实上我们在上个月才从2.1的版本升级到3.0.2的版本,在生产环境下频繁的升级毕竟不是一个好的策略,特别还是一个数据库的产品。
所以,我们还是倾向于在现有版本的情况下怎么去处理这个问题,而不是说每次一遇到问题都是通过升级去处理。
建议升级是因为现在遇到的bug都是新版本已经修复的,目前 76572 这台 tikv 上有两个 region 的 merge 卡住了,就是它导致了 gc 无法继续进行,新版本对这种情况进行了处理,所以建议升级。如果不升级的话,解决起来很麻烦,而且就算这次解决了,之后还是有可能继续发生这个问题。
已经升级为3.0.5,GC恢复正常。
好的。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。