tureo
(Tureo)
1
为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
- 系统版本 & kernel 版本:
- TiDB 版本:
Release Version: v2.1.13
Git Commit Hash: 6b5b1a6802f9b8f5a22d8aab24ac80729331e1bc
Git Branch: HEAD
UTC Build Time: 2019-06-21 12:27:08
GoVersion: go version go1.12 linux/amd64
Race Enabled: false
TiKV Min Version: 2.1.0-alpha.1-ff3dd160846b7d1aed9079c389fc188f7f5ea13e
Check Table Before Drop: false
- 磁盘型号:
- 集群节点分布:
2db、3pd、8kv
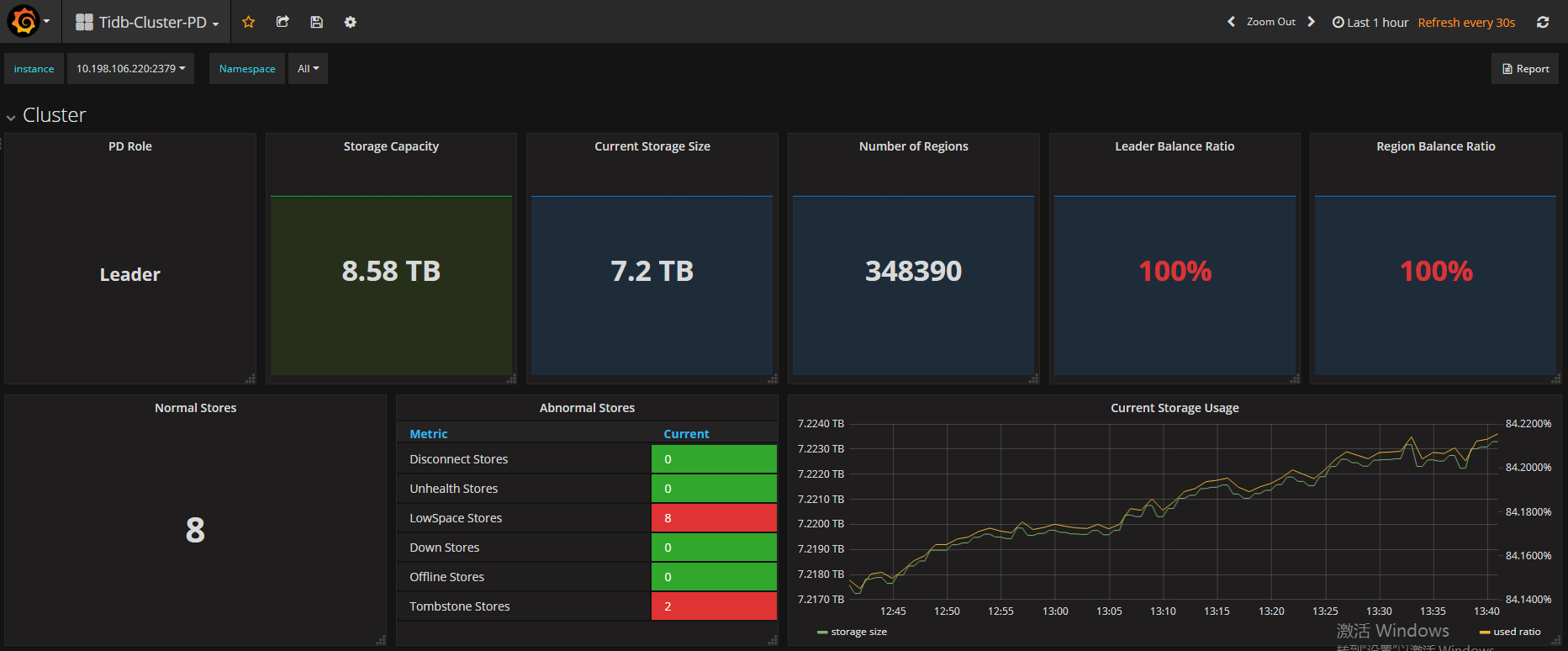
- 数据量 & region 数量 & 副本数:
存储占用7.2TB、1050000region、3副本
- 集群 QPS、.999-Duration、读写比例:
- 问题描述(我做了什么):
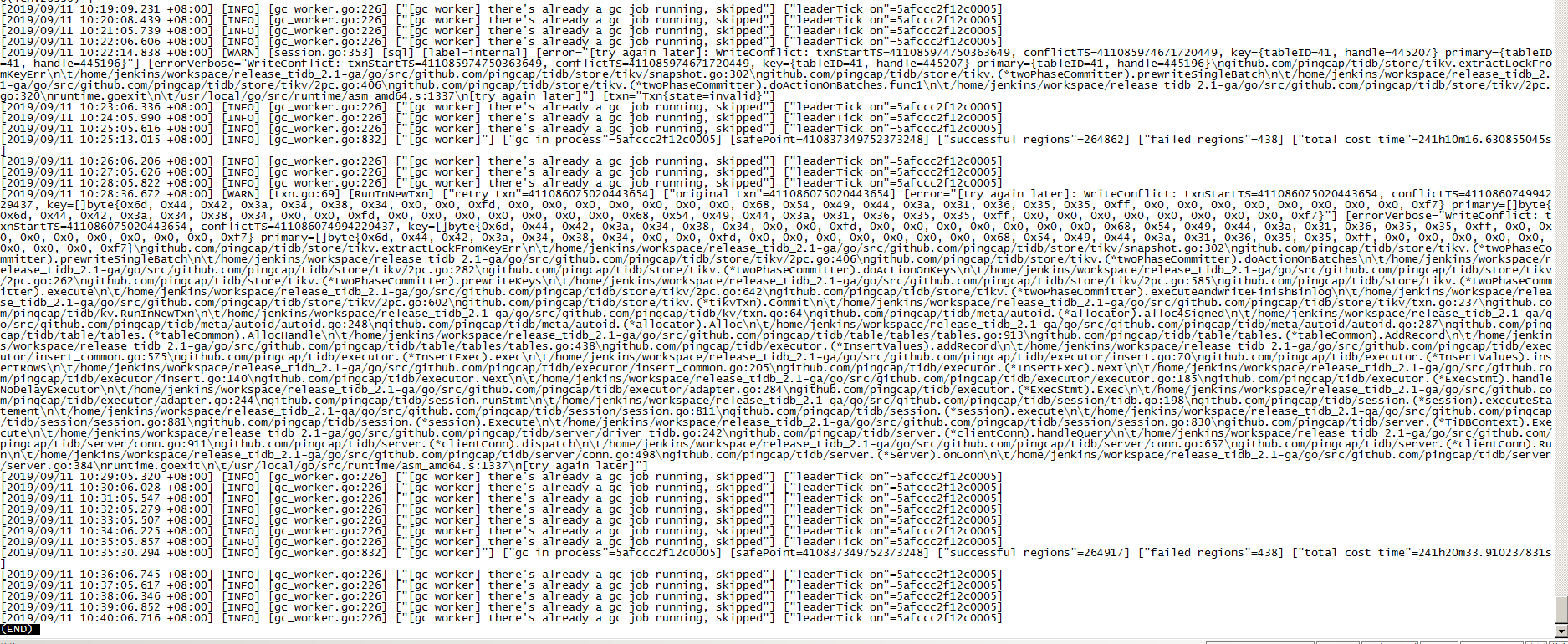
删除大量数据后发现空间回收较慢,然后根据官方文档准备调整gc时间和并发度参数时发现tikv_gc_last_run_time、tikv_gc_safe_point的值异常:
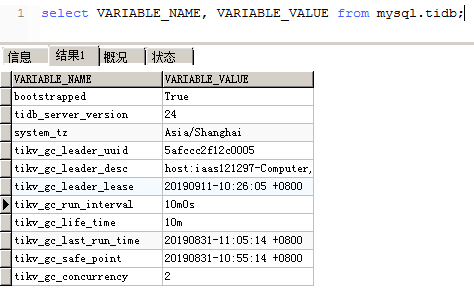
查看tidb.log,报错如下:
Hi. @tureo 你有 8 个tikv,可以把 tikv_gc_concurrency 调高到8.
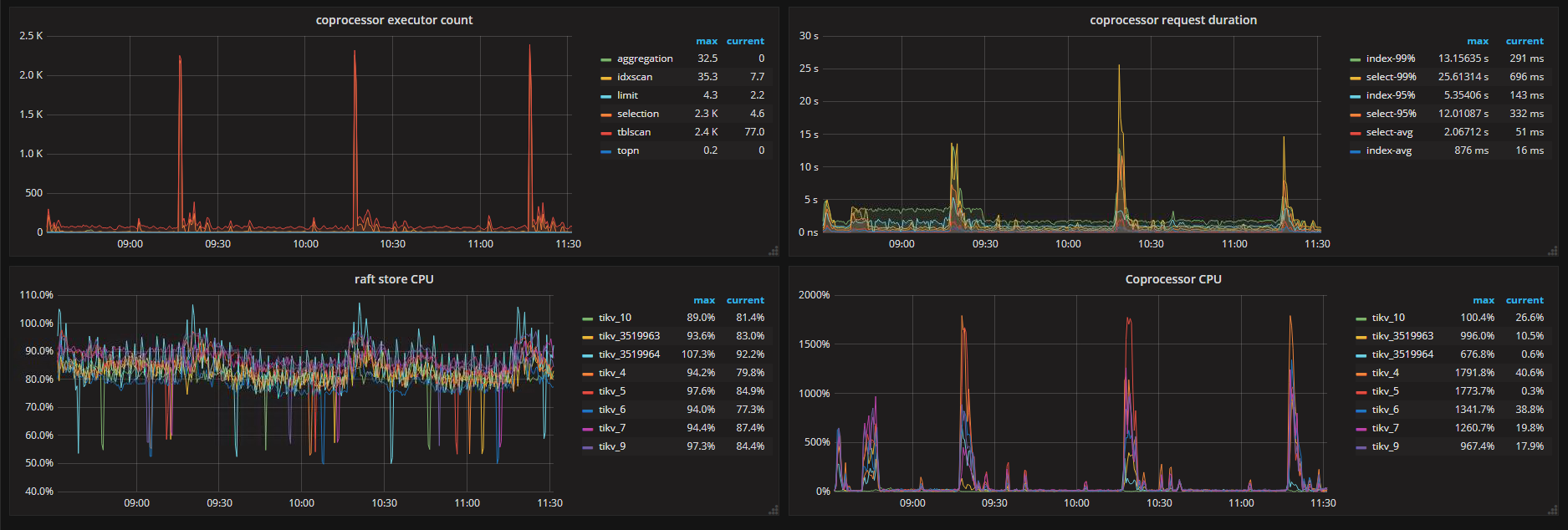
另外 region 数量太多,可能 raftstore 压力过大了,能否看看你这边的 raftstore cpu 指标.
tureo
(Tureo)
4
压力确实较大,加快空间回收速度我可以调整tikv_gc_concurrency,但tikv_gc_last_run_time、tikv_gc_safe_point这两个值异常和tidb日志中报的信息有什么影响吗?
Hi. @tureo
根据日志 GC 目前已经持续了 241 个小时,这和表中的 tikv_last_run_time 是对的上的,这两个值本身没有异常。异常的是这个 GC 速度实在太慢,照这个速度算 GC 一轮要一个多月。
建议先想办法降低 raftstore 的压力,比如开启 merge,把 raft-base-tick-interval 调长到两到三秒,或者升级到 3.0 版本。
另外,调整后的 tikv_gc_concurrency 会在下次 GC 时生效。如果 raftstore 的压力成功降下来之后 GC 速度仍然太慢,希望立即生效的话,需要通过重启 GC leader 进程的方式来终止本次 GC。GC leader 即 tikv_gc_leader_desc 所指的那台 TiDB,也就是产生上面截图中日志的那台 TiDB。如果要重启它请先确认不会对业务造成影响。
降低raftstore压力还有个办法是扩容
tureo
(Tureo)
6
好的,谢谢解答。
我们这边先按您的建议修改参数开启merge:config set max-merge-region-size 16、config set max-merge-region-keys 50000;
raft-base-tick-interval这个配置项在我们现在用的v2.1.13版本中的tikv.yml中不存在,搜索官方文档也未发现在v2.1中有这个配置项;
我们暂时不能升级tidb版本,后面会考虑升级到v2.1最新版本或者v3.0版本;
已调整tikv_gc_concurrency为4;
因为集群无法扩容,所以只能修改参数进行调整;
raft压力和GC回收效果待查看,如有必要我们会重启GCleader所在TiDB节点。
这个配置一直有的,不过没有在 tikv.yml 里面,目前可以先不用改,先看看已经改的效果吧:grin:
tureo
(Tureo)
8
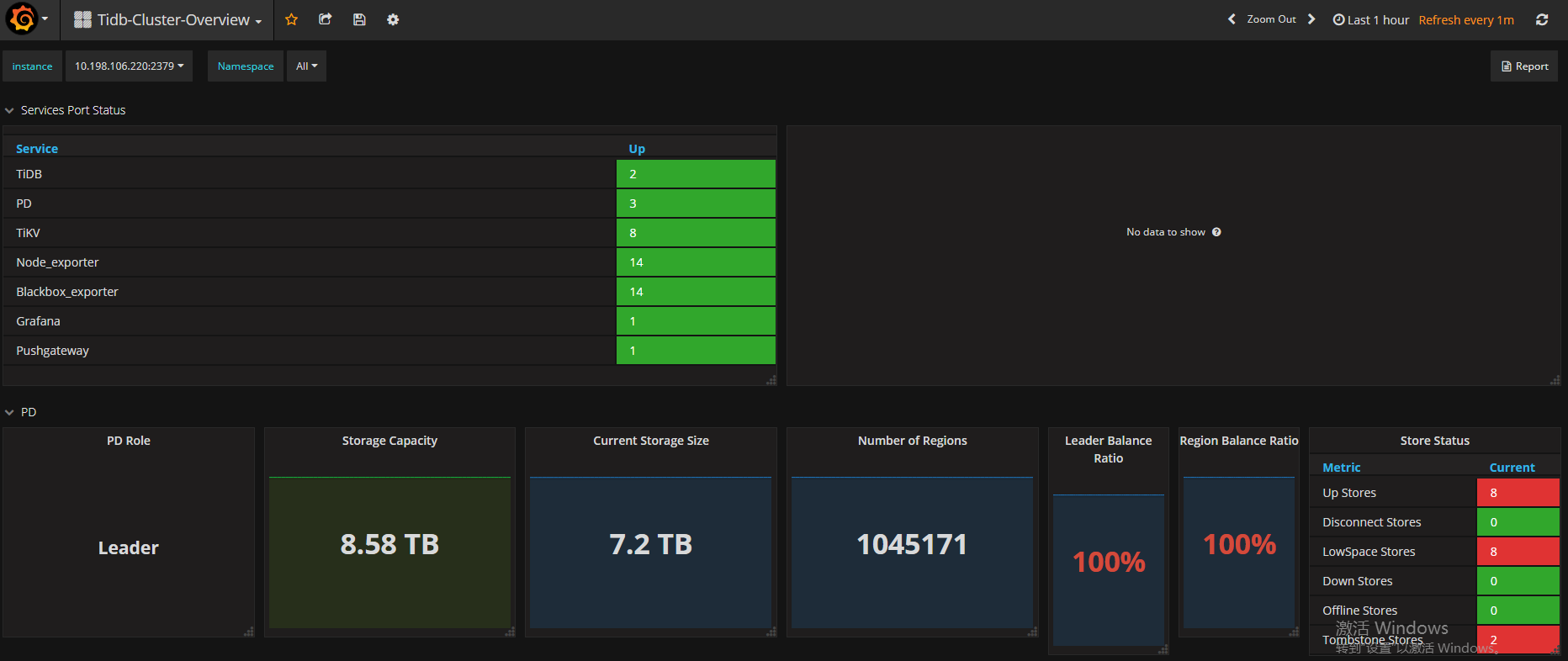
目前来看开启merge后region数量在缓慢减少,但PD页面和OVERVIEW页面显示的region数量并不一致且相差较大;
可能因为我们写入数据量比较大的问题,raft压力并没有下降;
昨天调整参数后重启了GCleader所在TiDB节点,现在看来还是GC回收慢、raft压力大的问题。
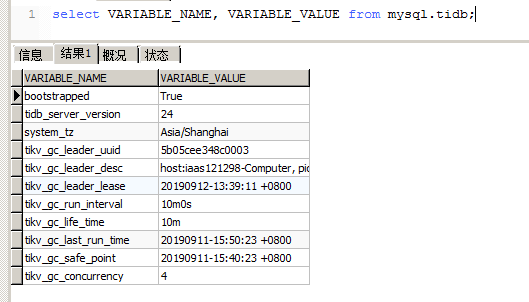
我看之前的GC回收一轮下来都要很久,是否有其他方法提高GC的速度?
tureo
(Tureo)
10
好的,那我们先修改相关参数,后续尝试升级到高版本。
system
(system)
关闭
11
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。