作者:朱博帅,爱奇艺资深工程师,TUG Ambassador
今天我主要和大家分享 TiDB 在爱奇艺的一些业务场景和实践,具体会从选型、测试、落地、推广、运维、应用、开发以及展望这几个方面来说一下这几年我们应用 TiDB 积累的一些经验。

爱奇艺 NewSQL 选型
爱奇艺的业务从以视频为主发展到电影票、商城、游戏和直播等多方面的业务,这几年业务数量增长非常快。业务数据量上来之后产生了很多问题,针对这些问题第一个方案就是分库分表。但是分库分表之后,随即带来的问题就是要不要提供 Proxy 服务给业务。如果提供了 Proxy,又会带来一系列的问题: SQL 的支持范围能到什么程度,性能如何等等。因此面对这种增长速度,对 NewSQL 的需求是不可避免的,所以我们对 NewSQL 数据库进行了调研,主要考虑这几个方面:

- 首先,基础的要求是能够兼容 MySQL。我们没有 PG 的服务,主要是考虑兼容 MySQL,这样业务在迁移的时候成本会很小,业务端的代码几乎不用修改。
- 其次,对事务和分布式事务的支持。
- 另外,透明的横向扩展、跨机房的高可用、活跃的社区都是我们考虑的一些要求。
- 最后,我们还希望能满足一些高级的特性,比如 HTAP、比较好的数据迁移的工具、实时同步、数据加密等。
当时我们不只是调研了 TiDB,还有市面上其他的一些开源 NewSQL 数据库。在横向对比的过程中,我们发现其他数据库有以下的一些问题:
- 有些数据库在支持横向扩展的时候需要用到 gossip 协议,但是我们担心,当集群或实例数量特别大的时候,gossip 协议这种广播的形式会给集群带来很大压力。
- 还有些数据库采用混合逻辑时钟的方式来提供事务 ID,这种方式要求一个集群里所有实例的真实时间差值比较小。如果时间差值较大,混合逻辑时钟带来的一个问题就是事务性能差。
除此之外我们还考虑了数据库对操作系统兼容性的支持等问题。互联网业务对于 SQL 支持的特性要求并不是很高,比如说外键支持,存储过程,触发器等,甚至即使有这样的要求,数据库发展前期可以先不用支持,当然有是一件好的事情。
我们也很看重发展速度。如果一款数据库能有好的社区支持,我们就可以和社区有良好的互动,想要的新功能就可以很快加入进来。甚至我们自己也可以参与开发,加速社区发展,这样即使现在的数据库功能不是很完善,将来也是可期的。
综合以上几点的考虑,我们最终选择的是 TiDB。
TiDB 在爱奇艺的使用
TiDB 使用概况

下面我简单介绍一下 TiDB 在爱奇艺的使用现状。
-
我们现在总集群数是 40+ 个,这些集群中有 10+ 个升级到了 3.0 版本。总机器数近 200 个,总实例数 600 多个,其中单个集群最大的数据量达到 30-40 T。
-
简单列了一下我们线上使用过的版本。我们关注 TiDB 的时间比较早,TiDB 在 GitHub 上最早的版本是 Beta 2,我们在TiDB Pre-GA 的时候就把它用在了数据库组内部的一个业务上,之后就一发不可收拾,1.0、2.0 和 3.0 的多个版本都使用过。之所以有这么多版本,我们是这样考虑的:
- TiDB 版本发布比较快,如果它能解决我们已知的 Bug 或问题,我们就会马上升级版本。
- 另外,我们虽然达不到紧跟社区的步伐,但也不会落后太多,如果有新的集群要上线,我们会选一个比较可靠的新版本。
目前正在观察已经升级到 3.0 版本的集群状况,后续计划是将集群有序升级到 TiDB 3.0 版本。
TiDB 平台化运维

针对这么多集群,我们是怎样运维的呢?我们把 TiDB 接入了私有云平台-云数据服务平台,平台的基本功能如下:
- 自助申请和展示:
用户申请的时候,我们首先会根据用户预估的最大 QPS 以及数据量,估算需要提供的 TiDB 集群规模,根据这个规模部署新的集群。另外我们也会考虑一下,它是否需要跨机房部署,是否需要支持 Spark、是否需要 TiDB-Binlog 的部署等。
- 监控和报警:
我们的报警是基于 TiDB 的 Prometheus 和 Grafana 体系来做的。在 Grafana 里通过 Webhook 的方式,把报警信息发送到自研的 AlertBridge,AlertBridge 会接到内部运维体系里。在这里面,我们可以指定一些发送报警的手段。
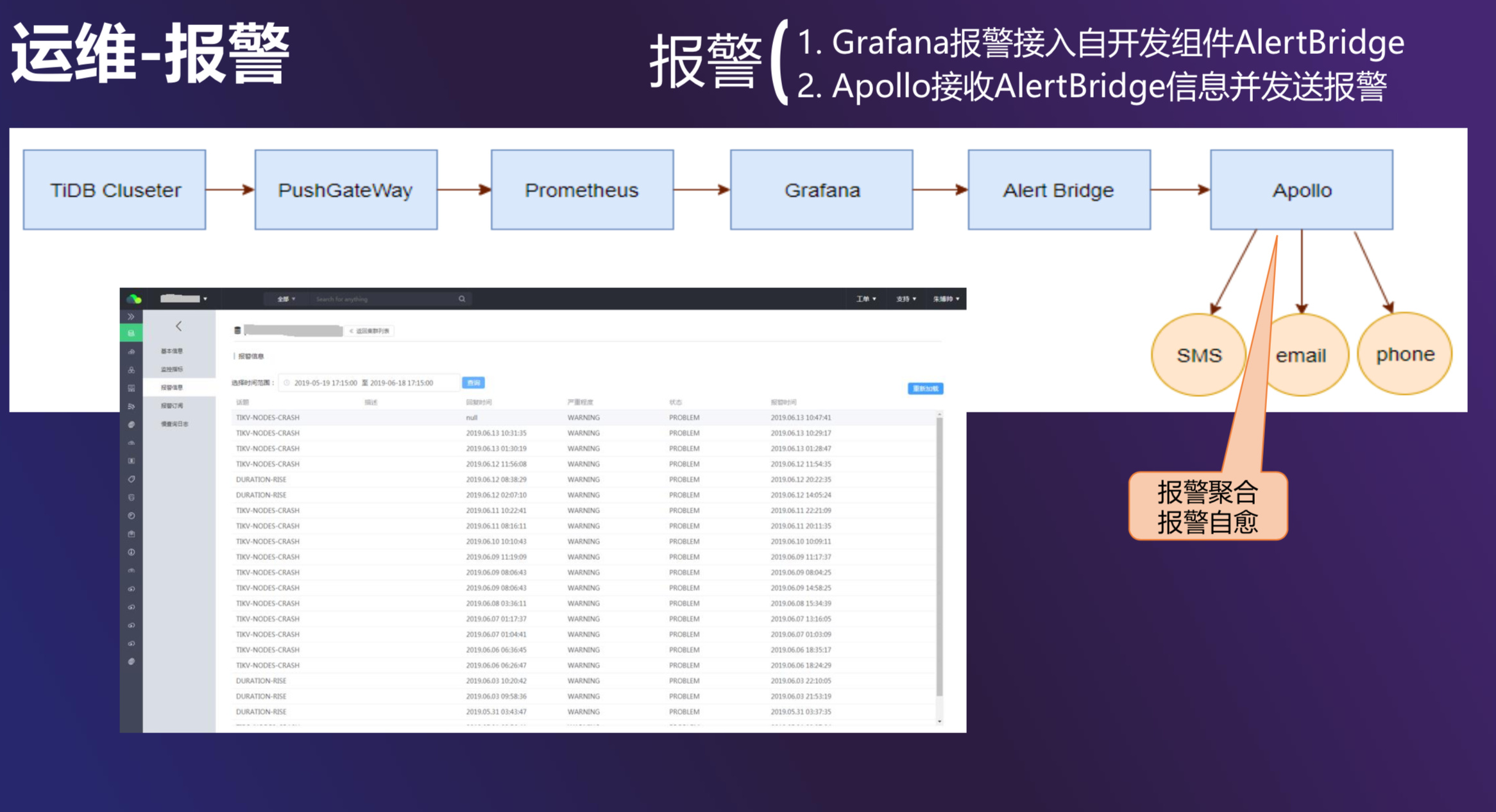
此外我们也可以做报警的聚合和报警的自愈。最新的 TiDB 版本,实际上已经去掉了 Pushgateway 这一块,因为它是一个单点。用户也可以自行查看自己的集群有过哪些报警。一开始我们配置的报警数量和种类非常多,针对 DBA、开发同学和业务同学的报警都配在一起。经过实践,我们最后把一个集群的报警种类压缩到 4-5 种,其余的我们不走这个流程,只是运维同学自己来看。
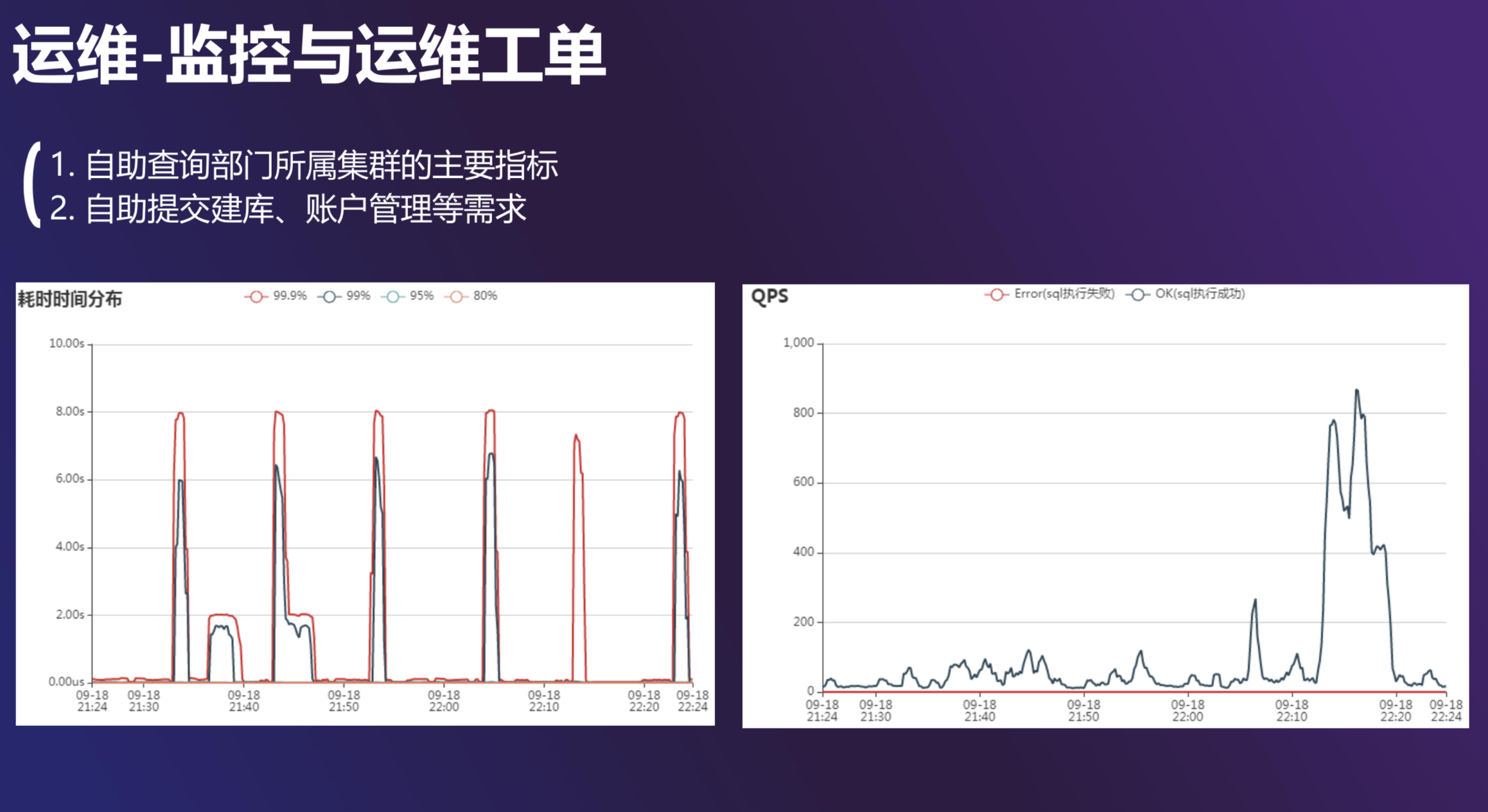
慢查询的收集和展示

爱奇艺内部有一个分布式日志收集系统,我们把它接到了 TiDB 的运维体系里。在这个系统里面,每一个 TiDB 的机器上都会有一个日志收集系统的 Agent,可以实时收集 TiDB 日志。通过这个系统我们可以做两件事:
- 依据日志收集系统的实时计算通路做一些基于日志的报警;
- 另外一个通路是一个全量通路,我们会把这些数据集中收集到 Elasticsearch 上,然后按条件进行查询。右图是云数据库服务平台上的展示,用户可以查看自己的集群根据时长的 SQL 分布情况,以及 Top5 的 SQL 有哪些,这样可以方便用户优化自己的业务。
典型业务中遇到的主要问题和解决方案
下面介绍一些爱奇艺使用 TiDB 的典型业务,这些业务上线的时候遇到了哪些问题,以及我们是怎么解决的。
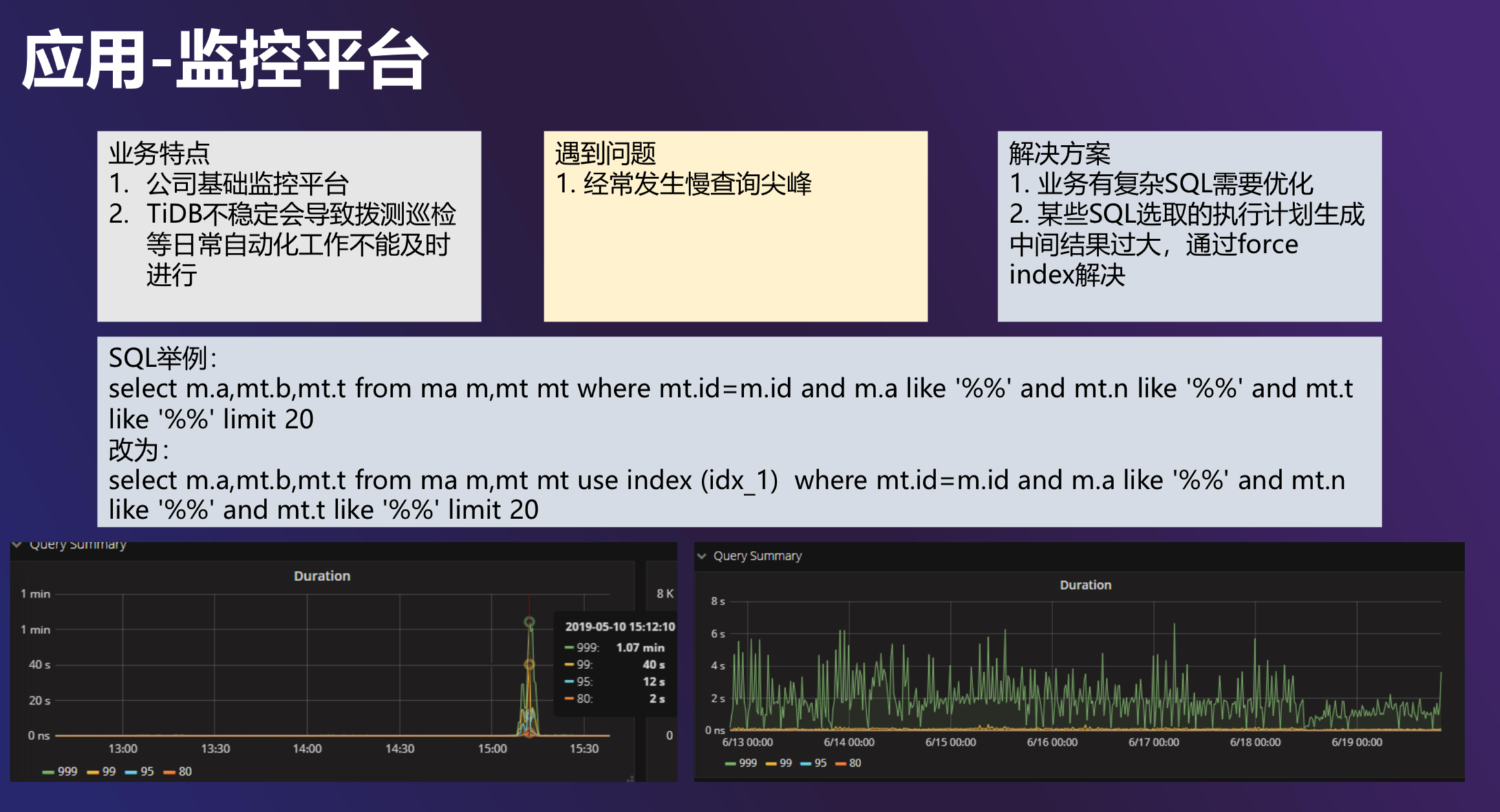
应用一 公司级监控平台
第一个业务是公司级的监控平台,我们遇到的最主要的问题是慢查询的尖峰问题。有一部分 SQL 确实特别复杂,需要业务本身去优化,比如有大量的聚合,大量的 Group by,甚至还有大量的 like,而且还没法用前缀索引。每当出现这种情况,我们 TiDB 的内存就开始爆增,之后就 OOM。所以这种导致 TiDB 中间结果特别大的复杂 SQL 肯定是需要优化的。
另外,还有一些 SQL 实际上是 TiDB 的执行器和优化器选择的索引不对造成的,这时候我们就会用强制索引的方式来解决这个问题。当然随着新版本的发布,这种情况出现的概率越来越小。
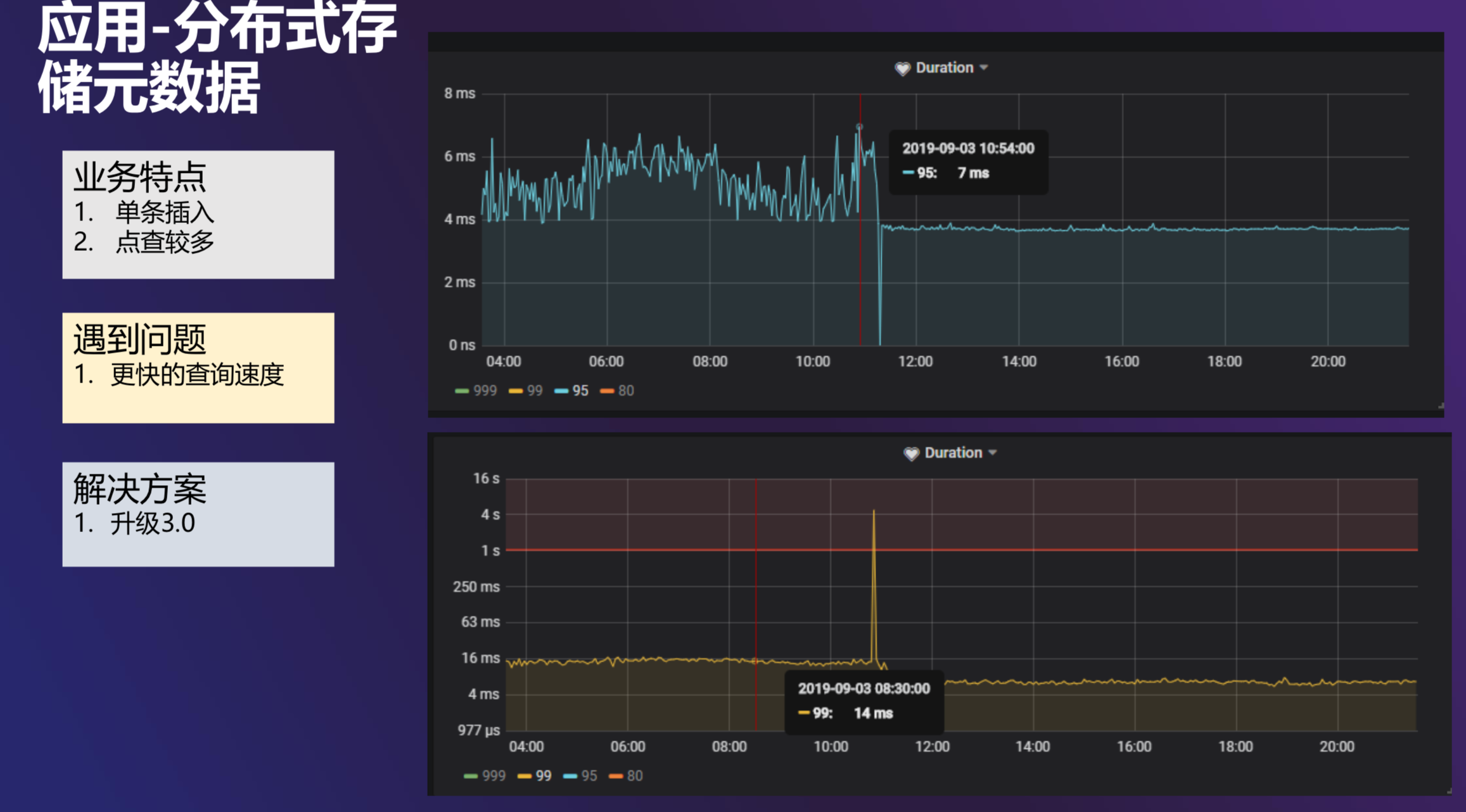
应用二 分布式存储元数据
TiDB 在爱奇艺的另外一个应用是分布式存储元数据。该业务中数据是单条插入,点查较多,我们需要更快的查询速度,解决方案是将 TiDB 从 2.0 升级到 3.0 版本。集群升级后我们观察了 Duration 的情况,提升十分明显。它的 P95 本来是在 4-7 毫秒之间振动,最后变成 4 毫秒以下非常平稳,P99 也有很大的降低,所以 TiDB 3.0 对性能的优化还是很明显的。
应用三 CDN 监控
下面重点说一下最后一个典型应用:CDN 监控。
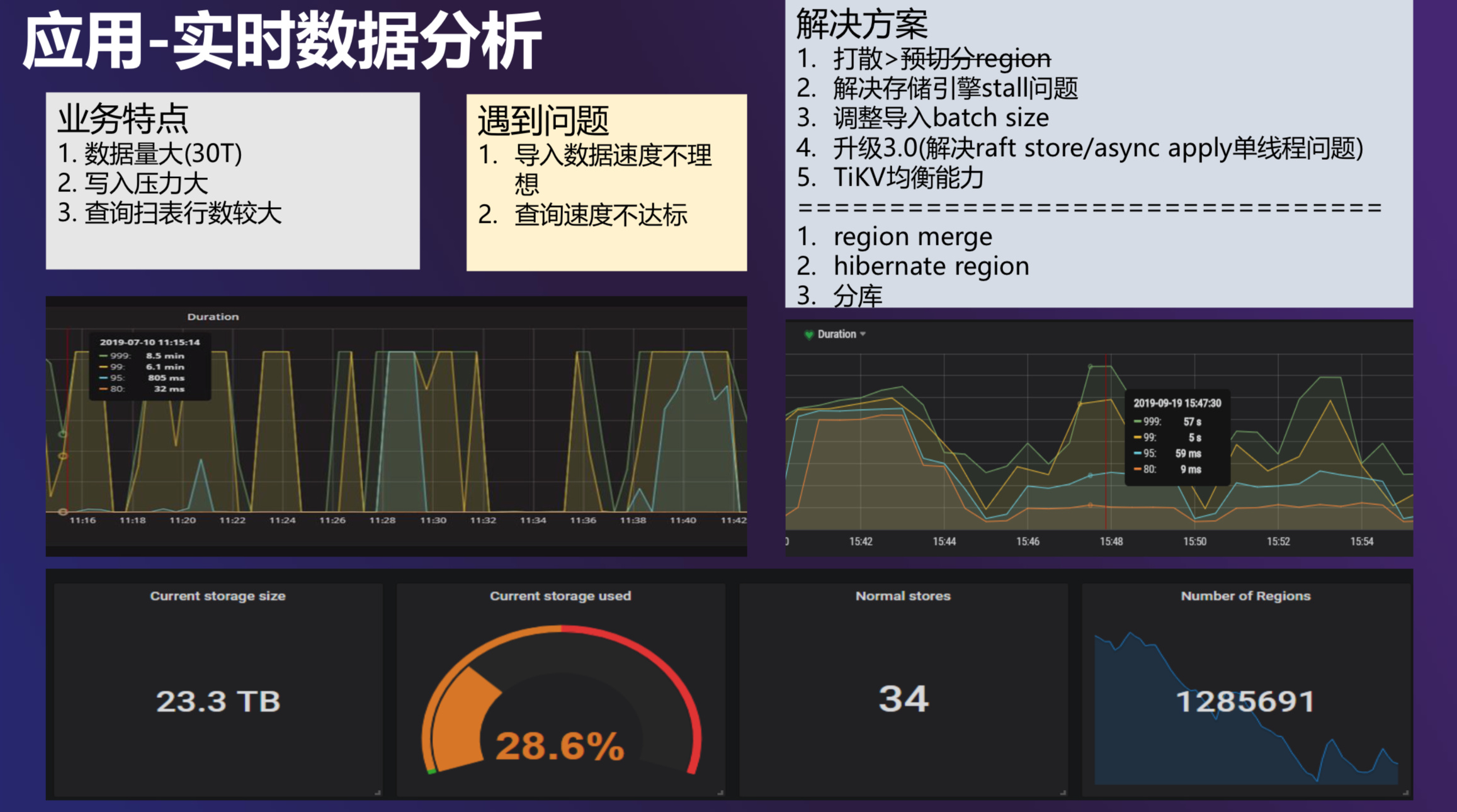
图示 CDN 监控的数据量非常大。业务预估存一年的数据,大概 90T。首先要写入数据,把数据从其他的数据库系统导入过来,这个过程中就遇到了很大的问题。业务想尽快导入进来,但是导入的速度一直上不去,我们也做了很多优化:
- 首先还是打散,但是效果并不是很大。我们从社区里也了解到,最新的 3.0 版本是支持预切分 Region 的,这个特性有助于写入速度。但是这有一个问题:只有在创建表的时候才能预切分,但是当一个大表已经开始写入,就没法再设置预切分了。
- 另外是要看一下存储引擎是不是有 stall 的问题。因为 TiDB 底层依赖的 RocksDB 是 LSM 结构,它对于 compaction 和 flush 这些线程的并发会有一个默认值,并且这个默认值是有限制的,在写入量比较大的时候,一般都会去调一系列的参数,尽量让 RocksDB 不要有 Stall 的问题。
- 第三点就是调整导入的 batch size。因为 TiDB 主要是 OLTP 场景的数据库,batch size 不能太大,我们也和业务那边反复进行实验,最终定了一个比较小的 batch size,这样写入速度会最佳。另外我们在 3.0 版本 GA 之后也进行了升级,感受最明显的是解决了 Raft Store 和 async apply 单线程问题的改善。之前这块经常会有 CPU 使用量达到 80% 甚至 100% 的问题,但是又没法解决。升级到 3.0 版本之后,能支持配置多线程,大大释放了底层磁盘的性能,TiKV 的压力均衡等等问题也得到了解决。
上面中间两幅图是简单的对比,左侧是优化之前,图中最高点大概可以到十几分钟。用户写一批次数据的时候,它的 Duration 马上就会上去。右图是优化后的结果,最高的 Duration P99 只有一分钟左右。
这是简单优化之后的结果,实际上还是可以继续提高速度的,我们继续分析这个问题。首先我们发现 Raft 这一层,在做 Apply 的时候周期很长,可能达到几十毫秒,但是性能好的一些集群里周期只是微秒级别的。经过分析发现,这个集群里的 Region 数量特别多。上图下放有一个展示,这是当时集群数据量在 23G 左右时的一个图,最右侧的 Region 的数量是 128万+,这个地方写的是 Number of Region,实际上是 Leader 的数量。如果乘以三副本,是三百多万。三百多万的 Region 我们计算一下,一个 Region 才有几 M,这是十分不正常的。这里我们也和 PingCAP 的伙伴们做了深入沟通,确实在 Region 大小的估算上有些不足,现在这个地方也在改进当中。具体到我这个集群,问题是要解决的,所以我们打开了 Region Merge 的功能,但是有一个问题: PD 集群是多目标的,如果让它同时做多件事情,每件事的效果都没有那么好。现在用户还在写入数据,同时还要做 Region Merge,所以不能把 Region Merge 的线程数开太大,所以现在 Region 下降还是一个缓慢的过程。
如果 Region 降低的速率一直都比较低怎么办?我们也想到一个 3.0的特性:Hibernate Region。因为有些 Region 在没有变更的情况之下,可以不进行频繁的心跳,这样也是安全的。我们现在是批量写入的场景,以前写入的数据不会发生变化,但是也要维持心跳,这样对整个集群都是一个无谓的压力。我们本来准备打开这个功能,但是打开之后如果同时进 Region Merge,会担心线上出问题,所以等 Region Merge 到一定程度之后,再把静默 Region 的功能开启。
未来展望

最后说一下将来的一些展望。
- 首先是我们将自己开发实现一些资源开销小、方便好用的闪回工具。原生提供的方式依赖 TiDB 本身的 GC 时间,可以把 GC 时间延长,之后去找 MVCC 里面的数据。方法可行,但是有一个问题:TiDB 集群如果数据变更特别频繁,把 GC 时间延长,数据量增加了很多,对磁盘有压力,对性能也有压力,个人感觉不太完美。我还是希望能够把 Binlog 保存在外面,想做闪回的时候就有类似 MySQL 的方式,通过闪回工具反向解析 Binlog,设定一个时间点,去做闪回。
- 透明的冷热数据迁移。我们现在正在深入去做,目标是只要用户用我们这个系统,是可以透明的做数据迁移的,也就是可以实时访问这些数据,不用管数据到底是在迁移当中,还是已经迁移完了。
- 社区展望。现在 3.0 版本已经出了好几个了,其中有几个特性我们也特别感兴趣,例如 Follower Read。希望能尽快有一个稳定的版本,估计性能会有很大的提升。
- 静默 Region。
- 除此之外,我们希望能有一个物理备份和恢复的方案。如果是逻辑备份,恢复时间很难保证,尤其对 TiDB 这样的分布式数据库来说,数据量很大,数据恢复的时间肯定是一个问题。另外我觉得磁盘压力也是一个问题。分布式数据库本身就有三副本了,还想再做一个逻辑备份,需要磁盘空间太大我觉得不合适。最好是能有一个物理的备份方案,会比较快。此外还能有一些压缩的方案,能让备份数据占用磁盘空间尽量减少。
- 另外还有一些其它想法,比如 RPC 速度这块,因为 TiDB 用的是 gRPC,所以 TiDB 寄希望 gRPC 本身能有好的优化,提高速度。我觉得应该更积极主动的去推进 gRPC 本身的发展。因为作为分布式数据库如果每次网络调用都比较慢,这必然是一个瓶颈。
- 最后是希望能够有一些 memory limit。因为有一些涉及数据行比较多的 SQL,明显占用内存空间很大,然后内存就撑爆了。如果集群比较小,TiDB 和 TiKV 还部署在一起,很有可能 TiDB 把 TiKV 直接 OOM,整个集群瞬间就不可用了。希望对于 TiDB 有内存限制,或者像 MySQL 那样,对于涉及数据行比较多的 SQL 中间结果落到磁盘,而不是全放到内存里,这样整体稳定性可以有很好的提升。