本文系北京 TUG 线下活动 “全面了解转转的 TiDB 实践” 实录,分享人:转转数据库负责人 冀浩东

Ti 友好:
我是转转的数据库负责人冀浩东,今天主要和大家分享以下内容:转转引入 TiDB 主要解决什么问题;大规模线上应用遇到的问题;TiDB 集群标准化和未来展望。这些都是转转使用 TiDB 的一些经验,供大家参考。

转转引入 TiDB 首先解决了分库分表的问题。某些场景不便于分库分表, 分库分表会使业务层开发逻辑变得越来越复杂,不利于降本增效的方向。其次解决了海量数据存储的问题。单机容量有瓶颈,会影响最终集群的效果。

转转在 2018 年就开始调研 TiDB,从 1.0 到 3.0。目前集群数量 30+/数据量 200T+/数据节点 500+/日访问量 1000 亿+,主要承载用户、交易、IM、商业等业务。

随着业务的扩展,集群数量的增加,维护成本也会相应增加。我们首先遇到的第一个问题,也是我们经常会遇到的问题就是性能问题的定位。业务 SQL 响应耗时突然增加了,如何定位是哪些 SQL 导致的?下面这图大家在使用 TiDB 时会经常见到,可以明显看到某一时刻集群的响应延迟变慢了,业务也想要知道为什么变慢了,这时候我们就要定位问题。
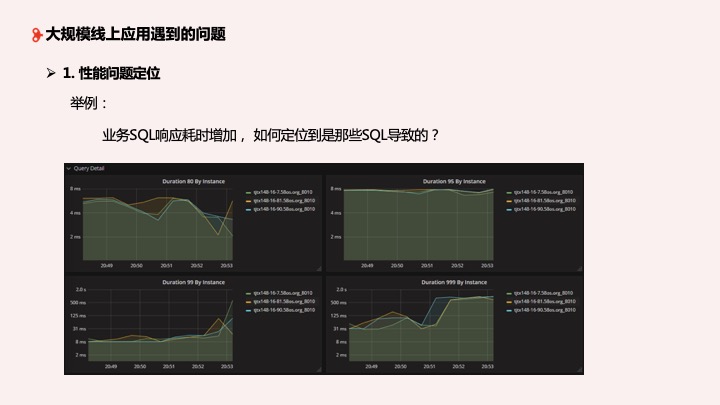
通常我们要打开 TiDB 监控平台看一些指标: Query 的指标、事务的指标等,看完之后我们再看 TiDB 日志, 监控过滤关键字后再结合上下文去了解 TiDB 发生了什么情况。最后去看 TiKV 的日志,通过关键字分析后基本上能够定位问题。
如果维护的集群只是一套或两套,没有问题。但是当集群增加到上十套或上百套,节点相应增加时,我们怎么定位问题?

接下来是集群管理。运维单套集群时没有问题,但是管理多套集群时会遇到例如集群部署、集群版本升级、配置不兼容等问题。 简单细说一下,比如在集群部署时,PD 在 Systemd 下会有问题,因为每台机器只支持一个 PD,可以通过 supervise解决,但是在起停时容易失败。版本升级时,早期两星期升一次级,和官方同步,但后来跟不上了,所以我们就会选择一个版本停下来,然后观望。在版本升级的时候,我们遇到的问题是配置不一样,小版本也不一样,由于我们做了一些自定义的配置,可能在这个版本就不生效了,导致升级时出问题、报错。因为都是线上的集群,每次成本都很高。整体来说,集群管理难度增加,每次升级版本的体验都不太友好。

第三个问题:日志规范不统一。这个问题对于刚刚使用 TiDB 的用户来说感受可能不太深,但其实 1.0 的日志和 2.0 的日志是不一样的。比如说慢日志这个日志格式,2.1 版本的关键字变化和 2.0 版本不兼容。这个对于我们运维人员来说成本很高。慢日志格式从 2.1.8 之后彻底变成 MySQL 形式,上下版本不太兼容,线上目前是多版本并存,所以极大地增加了日志处理的难度。

第四个问题:慢 SQL 对集群整体稳定性的影响。对于日常来说,线上复杂统计 SQL,大数据的 ETL 需求,以及数据临时抽取需求都很正常,但是直接在线上操作时有可能会导致整个集群响应延时变慢,最终影响整个业务的响应延时。

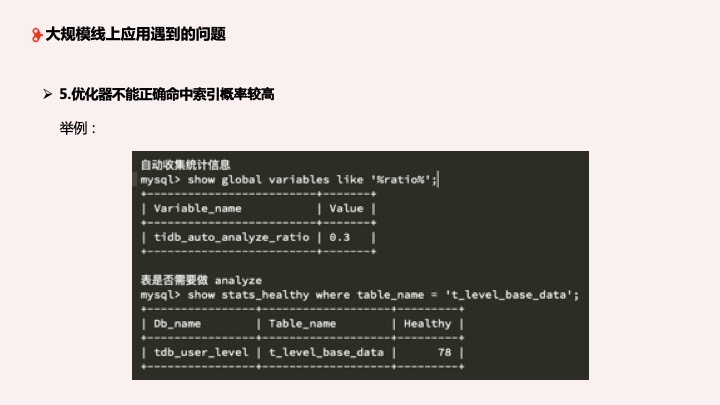
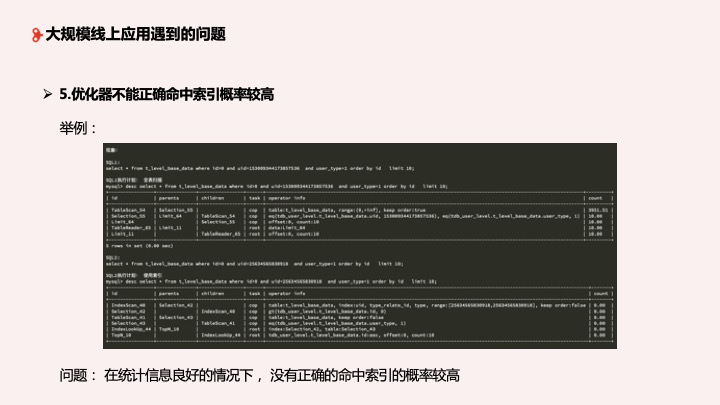
第五个问题:优化器不能正确命中索引概率较高,这个问题业务经常遇到。我的 SQL 一模一样,一个两秒,一个几十毫秒,怎么解释?比如说,在我们开启了统计信息自动统计、表的统计信息相对良好的情况下,两个一样的 SQL,一个走了索引,一个走了全程扫描,执行计划不一样。为什么在统计信息相对良好的情况下索引正确命中概率不高?大家可以先思考一下。
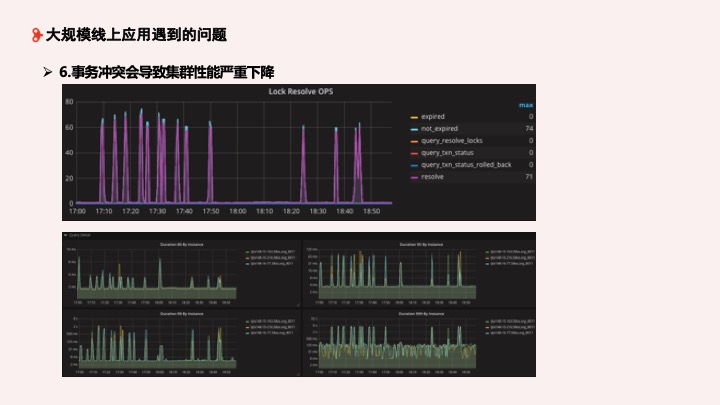
第六个问题:事务冲突会导致集群性能严重下降。例如图中的这个问题 SQL,执行时有一个并发更新的场景,在 TiDB retry_limit = 3 的情况下会严重影响集群性能。可以看到当 retry 出现时,整体锁的状态比较高,响应延时也相应增加。

刚刚我们整理了比较有代表性的六个问题,相信大家也有过思考。转转通过 TiDB 的标准化来解决:集群部署、信息收集、监控告警和业务上线中遇到的问题。
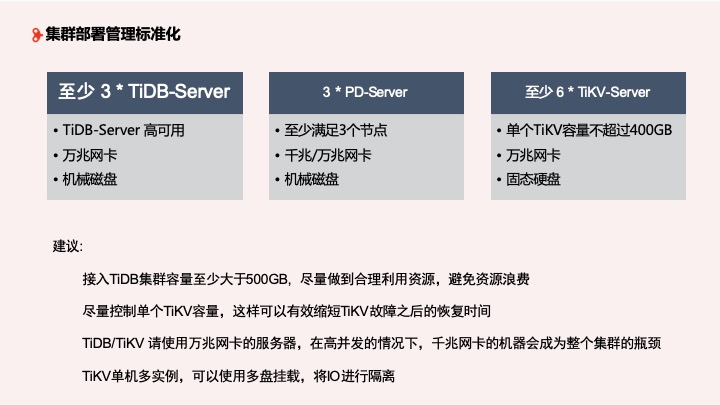
在集群部署标准化方面,转转至少部署 3 个以上的 TiDB Server,用于 TiDB 高可用,为数据提供稳定的接入,需要万兆网卡和机械磁盘。其次需要 3 个 PD Server, 千兆或万兆网卡都可以,机械磁盘。最后至少 6 个 TiKV Server,单独 TiKV 容量不超过 400GB,但这也因企业的使用而异,最好使用固态硬盘。
对于部署管理的建议:作为 MySQL 应用场景的补充,我们不建议接入 TiDB 的容量特别少,建议至少大于 500GB,避免浪费资源;单独 TiKV 容量不超过 400GB,这可以有效缩短 TiKV 故障之后的恢复时间;TiDB/TiKV 在高并发下千兆网卡会成为容量瓶颈,请使用万兆网卡;TiKV 单机多实例,可以使用多盘挂载,将 IO 进行隔离,目前应用效果较好。
接下来是信息收集的标准化。我们一直和官方吐槽日志能不能固定下来,一路从 1.0 追到 3.0,算是资深老用户。对于新上 TiDB 的用户,建议使用 2.1.8 之后的版本,日志相对稳定,做日志的 ETL 也相对容易。官方会在未来的版本中将格式固定下来,这对社区来说是一件非常好的事情。目前对于转转来说,经过我们的规范,主要问题还是在 TiDB 的慢查询这块,我们针对慢查询开发了对应的实时慢查询视图,方便业务 RD 观察集群慢查询信息。目前主要通过 Flume 进行日志采集,最终通过平台进行统一处理、展示和告警。

下面是告警监控标准化。 TiDB 的原生报警有很多种告警和监控,转转做了梳理,确保每次告警都能起到预警的效果,并且有意义,但不一定每次告警都需要人工干预。如果每天都在收报警,会产生疲劳,大家就不看了,所以我们希望做到告警收敛。
还有就是告警做了简化,做定制,让收到的人更容易理解信息。业务 RD 根本看不懂 TiDB 的原生报警,他们只想知道出了什么问题,所以我们做了处理。
最后就是监控简化,通过扫描关键指标获取集群瞬时状态,这个目前还在和 TiDB 的同学一起做这个事情,希望能够兼容多个版本可以获取到集群的瞬时值,以便快速了解到集群问题、状态,定位大方向故障。

最后是业务上线标准化 。第一是 SQL 优化,表结构、索引及列表全部优化。DBA 要全程参与业务上线,包括建表、SQL List,审视表结构和 SQL,也就是我们每次要上线 TiDB 集群时,都要和业务去讨论有哪些地方可能有问题。SQL 要全部使用 Force Index,用于解决优化器不能正确命中索引概率高的问题。3.0 GA 中包含 SQL Plan Management,目前虽然是实验特性,但是大家可以测一下,这个是美团和 TiDB 一起联合开发的功能。然后响应延时我们要求比较高,99.9% 控制在 100 ms 以下,99% 控制在 10 ms 以下才能上线,能解决一些常规的响应延时。接下来就是 TiDB Explain, DBA 需要熟练掌握,并且将如何解读其中的内容告诉开发后才能上线。
第二是业务逻辑。在已有的业务场景下,并发更新同一条记录的情况下会触发 TiDB retry,在当前的事务模型(乐观锁)下表现并不好,怎么解决?我们使用的是转转自研的分布式锁 ZZLock,即将乐观锁加一个分布式锁来模拟悲观锁,这样对业务响应延时没有问题,可以将冲突时间降到比较平稳的时间。

第三是数据抽取,这是非常普遍的需求,我们使用了 binlog 这个组件,将 tidb-server 变更数据写到 Pump Cluster,然后 Drainer 将数据应用到下游集群,通过访问下游集群,解决在线上进行的复杂查询、抽取等时效要求不高的需求。

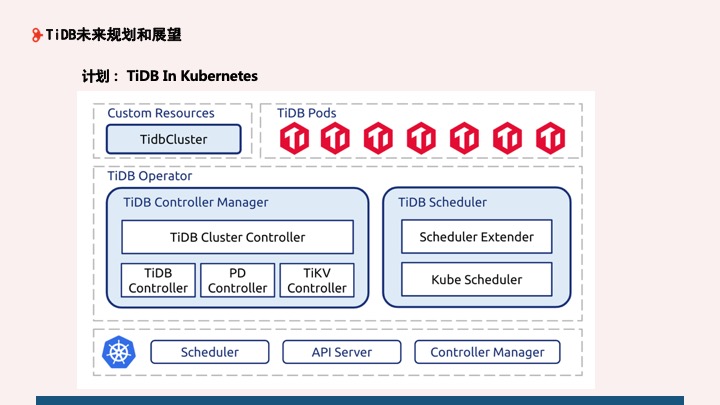
对于 TiDB 未来规划和展望,整体来说还是围绕降本增效这个主题,我们正在和 PingCAP 进行容器试点,接下来会将 TiDB 跑在云上面。
QA 环节:
美团同学:转转现在最大的集群是什么场景下的,大概有几个节点?访问 QPS 峰值有多少,数据量有多大?
冀浩东老师:目前最大的集群是 IM 集群,有上百个节点,数据量上百亿。整体来说 TiKV 集群比较多,整体响应不错,SQL 都是基于主键查询,业务方面做得很好。
美团同学:当前线上版本分布情况是什么?为什么不都升级到2.1.8?
冀浩东老师:目前有 2.0、 2.0.5、2.1.7、2.1.8,主流版本是2.1.8。2.1.8以下版本还比较稳定,有升级规划但是业务还没有什么需求,所以想和业务一起升上去。如果 3.0 测试效果较好,会考虑直接升级到 3.0。
美团同学:一个集群有多个 DB,还是只有一个 DB? 隔离怎么考虑?
冀浩东老师:一个集群只有一个 DB。
大家对冀浩东老师的分享有任何疑问欢迎在评论区留言探讨!
9 月 22 日,北京 TUG 将带大家走进爱奇艺,聊聊数据库技术选型那些事儿,欢迎大家点此报名。
相关阅读: