为提高效率,提问时请尽量提供详细背景信息,问题描述清晰可优先响应。以下信息点请尽量提供:
-
【系统版本 & kernel 版本】 centos 7.0
-
【TiDB 版本】 3.0
-
【磁盘型号】
-
【集群节点分布】 1tidb 1pd 3tikv
-
【数据量 & region 数量 & 副本数】
-
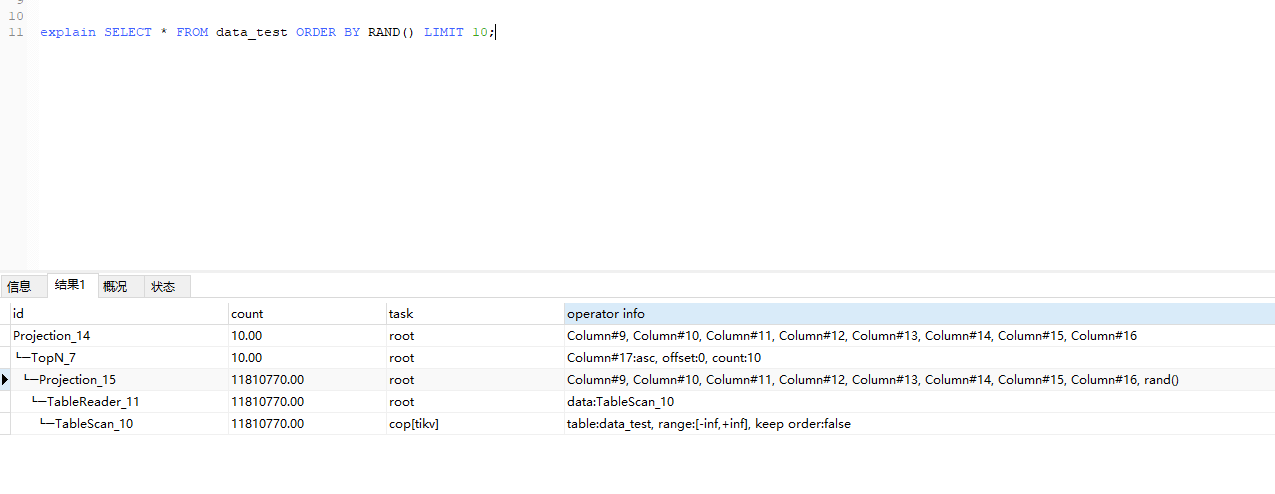
【问题描述(我做了什么)】 我库里有1100万数据,我想随机取10条数据 SELECT * FROM
data_testORDER BY RAND() LIMIT 10 用这个语句 消耗了24秒 ,太慢了 -
【关键词】