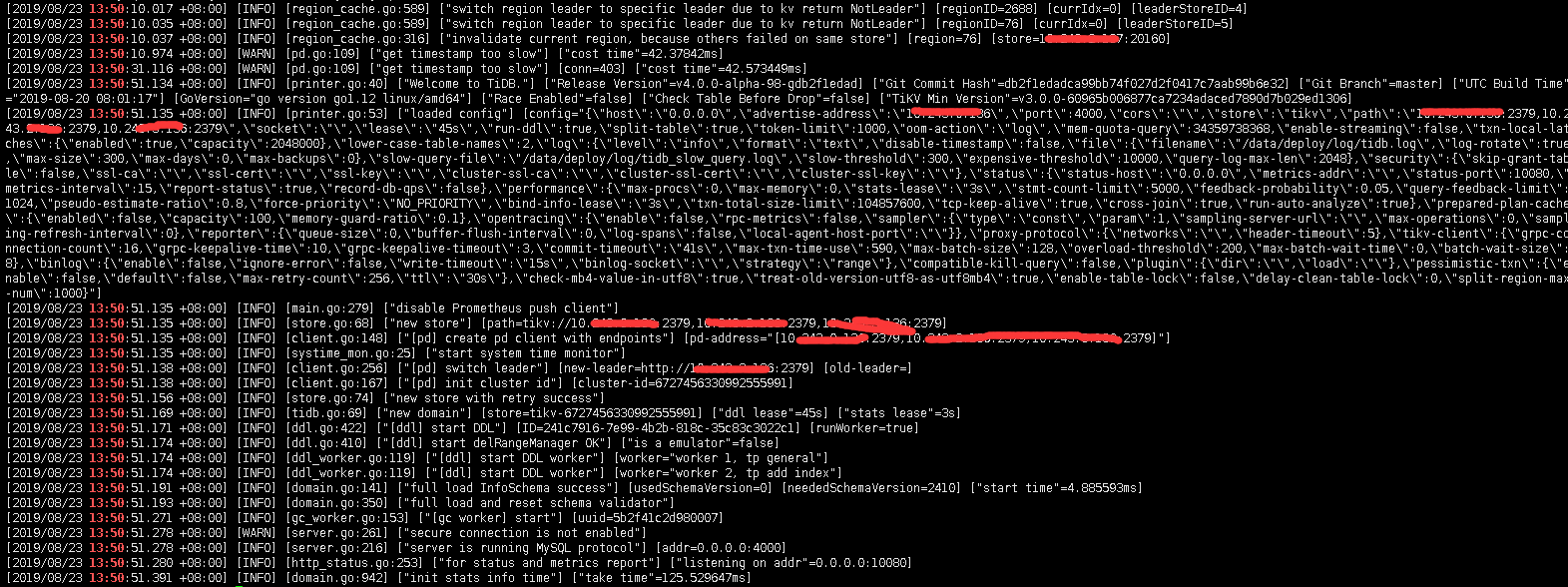
使用sysbench压测数据,/usr/local/bin/sysbench --config-file=config oltp_point_select --tables=32 --table-size=100000 prepare 线程数16 系统配置,16核32g 500SSD,每次压测一半就会报错
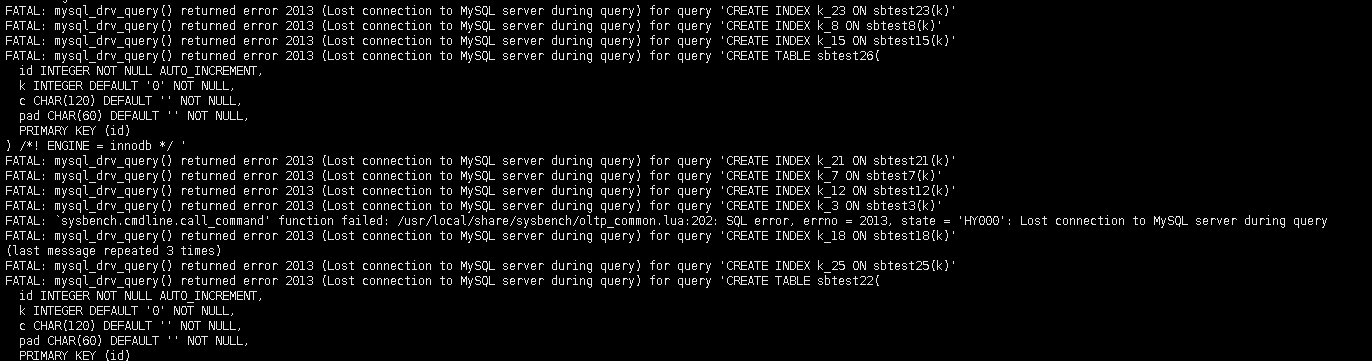
最大包大小修改了1G,最大连接数修改了3000尝试还是一样报错
使用sysbench压测数据,/usr/local/bin/sysbench --config-file=config oltp_point_select --tables=32 --table-size=100000 prepare 线程数16 系统配置,16核32g 500SSD,每次压测一半就会报错
排查问题思路:
检查一下 /var/log/msg 中是否有 TiDB server oom 报错

建议使用 3.0.2 或者 2.1.15 进行 sysbench 压测,master 版本不支持压测的。需要确认是不是 TiDB server 在 dmesg 里面是否有 out of memroy 报错 ? 可以 less 或者 vim 进去日志排查一下。
两个tidb之间是主从关系吗?还是,使用sysbench在pingcap官网下载的。因为我压测的数据很小,10万的数据量,32张表,早上9点多,压测了一下,成功了,想把数据压测百万,就一直报错。偶尔也成功过,不知道是怎么回事,监控看各个组件负载也不是很高。
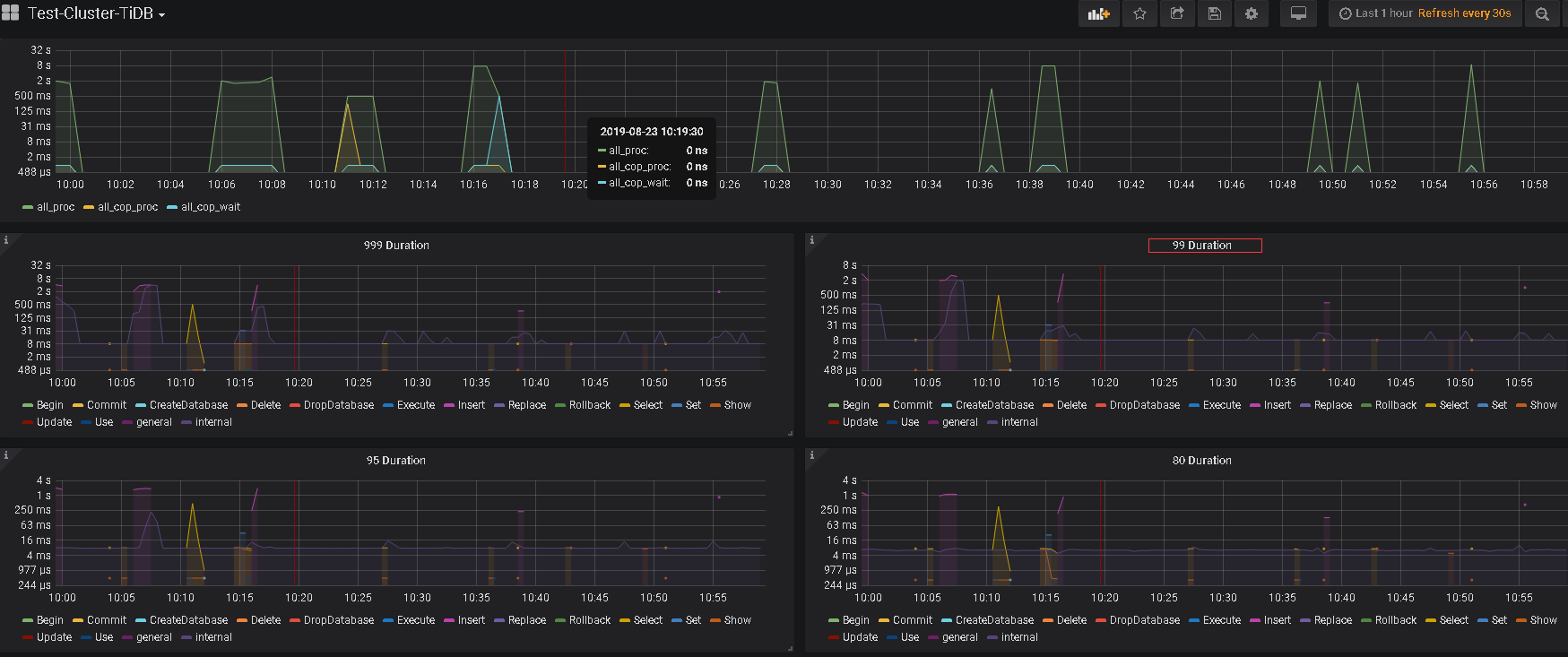
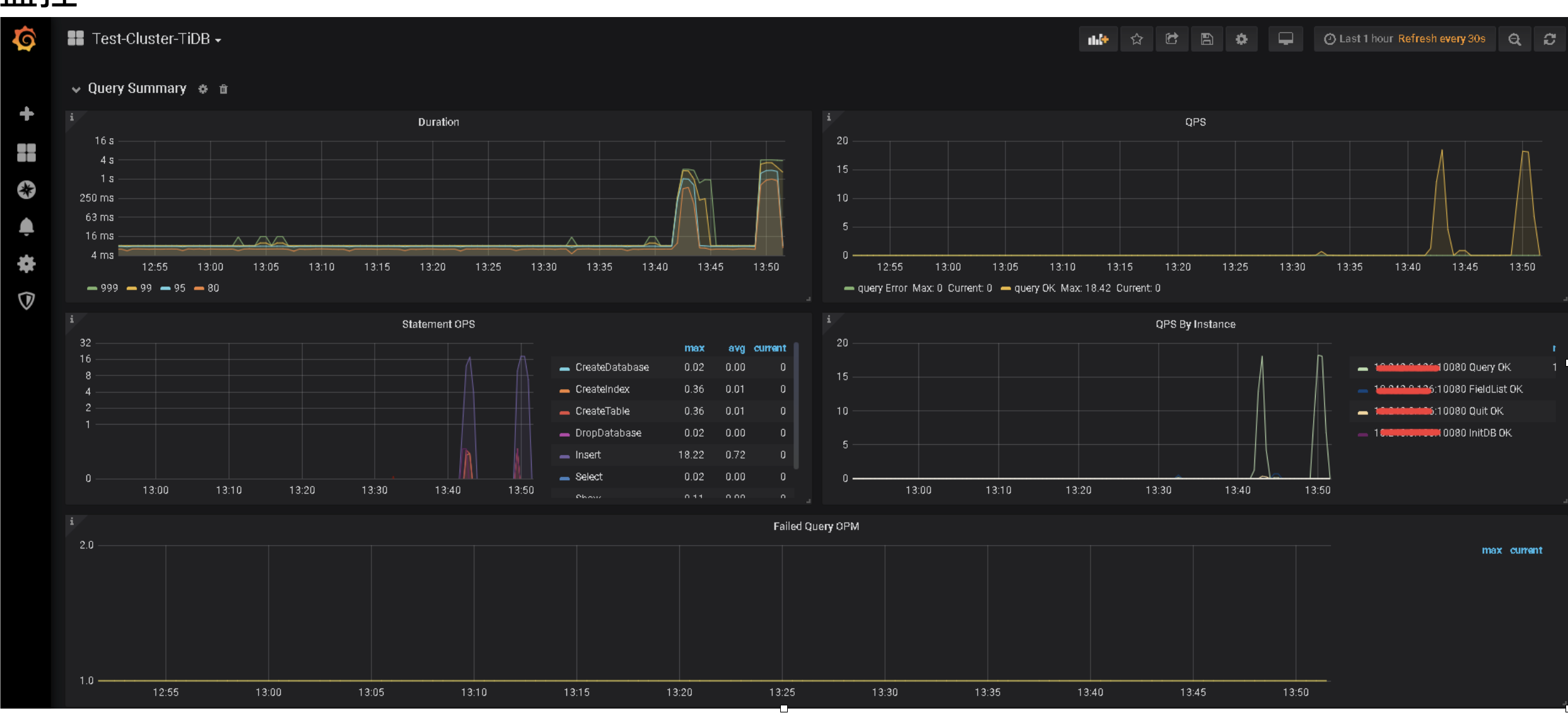
可以发一下 TiDB 的监控,帮你排查一下瓶颈。
麻烦上传一下 tidb 和 tikv 的日志,我们看一下具体的报错吧。
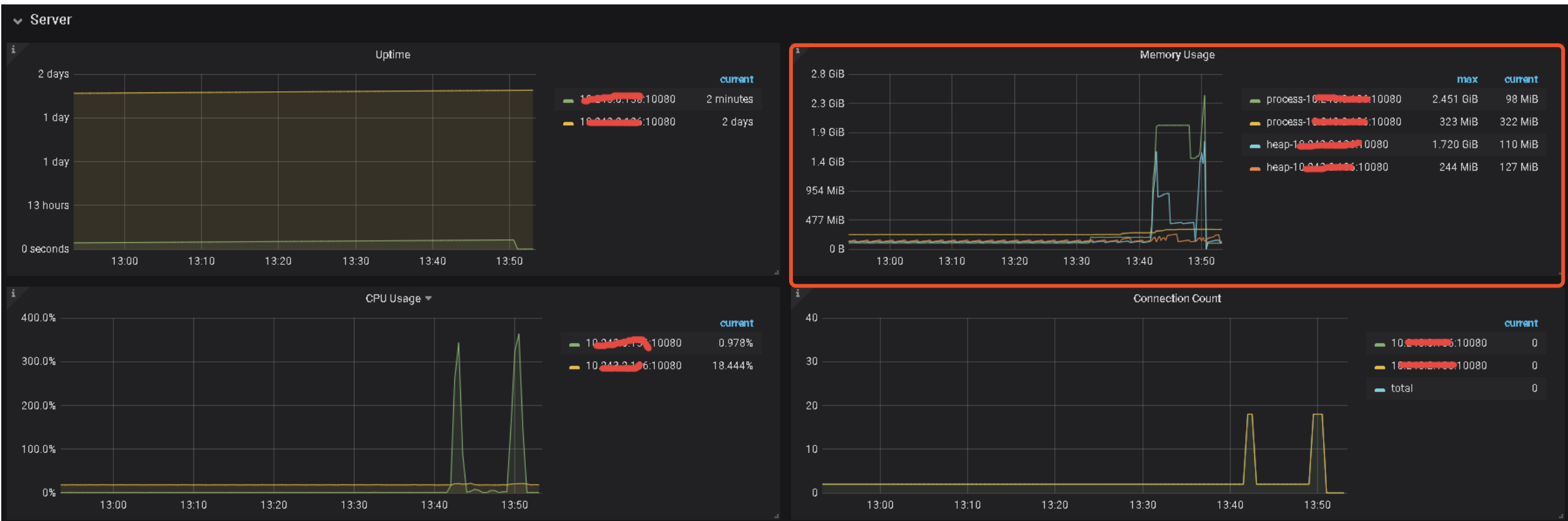
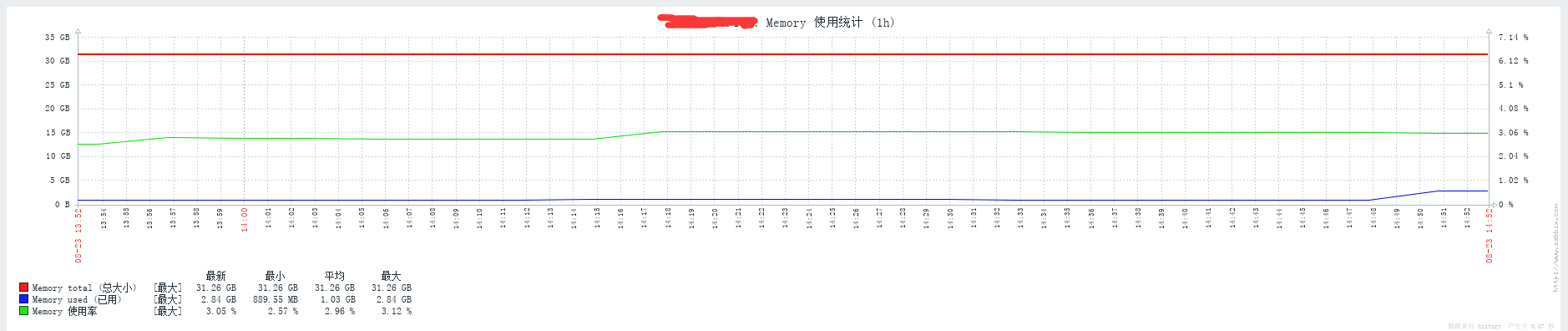
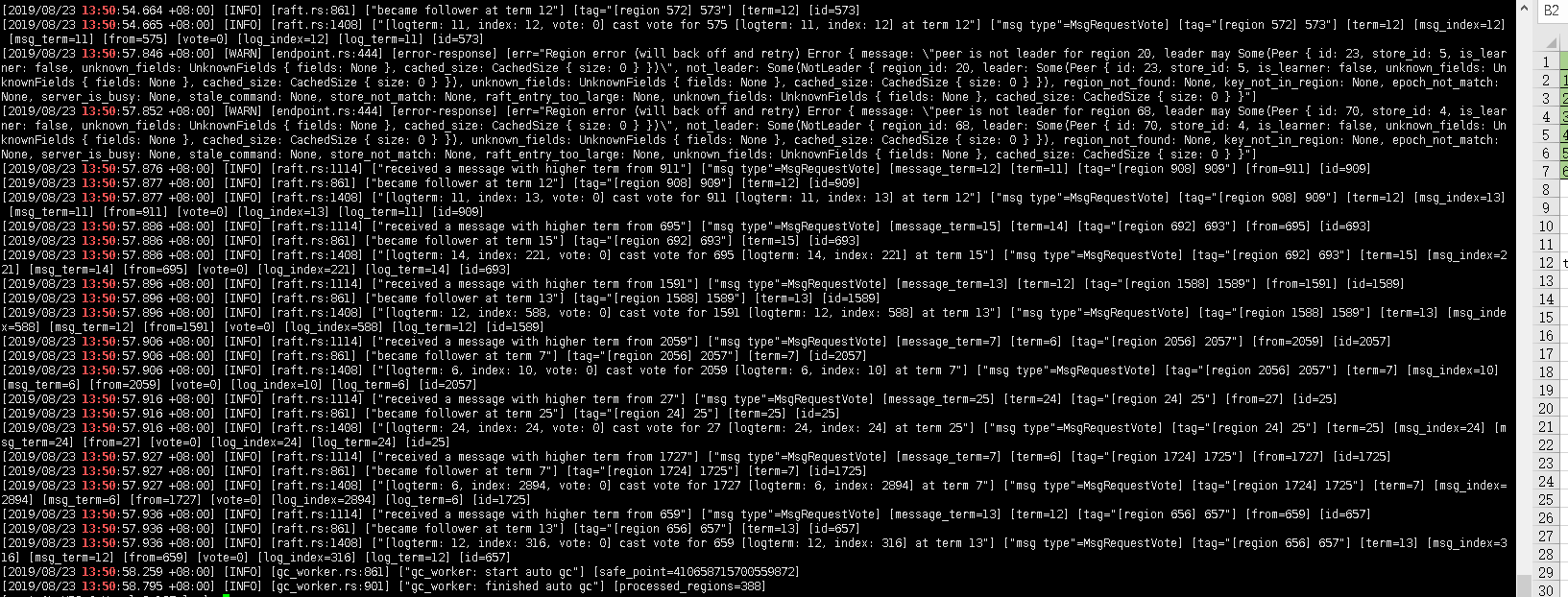
发一下 13:50 的 zabbix TiDB 服务的内存使用率截图,另外发一下 13:50 的 tidb 和 tikv 日志的情况。
万兆网卡吗 ?
千兆网卡
检查一下网络带宽是不是被占满了 ? TiDB 软硬件配置中万兆网卡是基准配置。
大概找到问题了,尝试将表设置更小,不会出现这个问题,应该是网卡的原因,多谢SUN
是千兆网卡,大量数据压测,导致网卡成为瓶颈,将数据量降低,再次进行压测,没有报错
 是集群配置
是集群配置