Spark Standalone集群升级步骤
本文主要介绍Spark Standalone集群升级步骤,Spark on YARN模式、Spark on Mesos模式以及Spark on k8s 不在本文介绍范围。
要搞明白Spark Standalone集群升级步骤,首先需要了解一下Spark Standalone集群部署原理。
Spark Standalone集群部署原理
Spark Standalone集群使用Master-Slave模式,常见的部署见下图,一个Master+N个Slave。
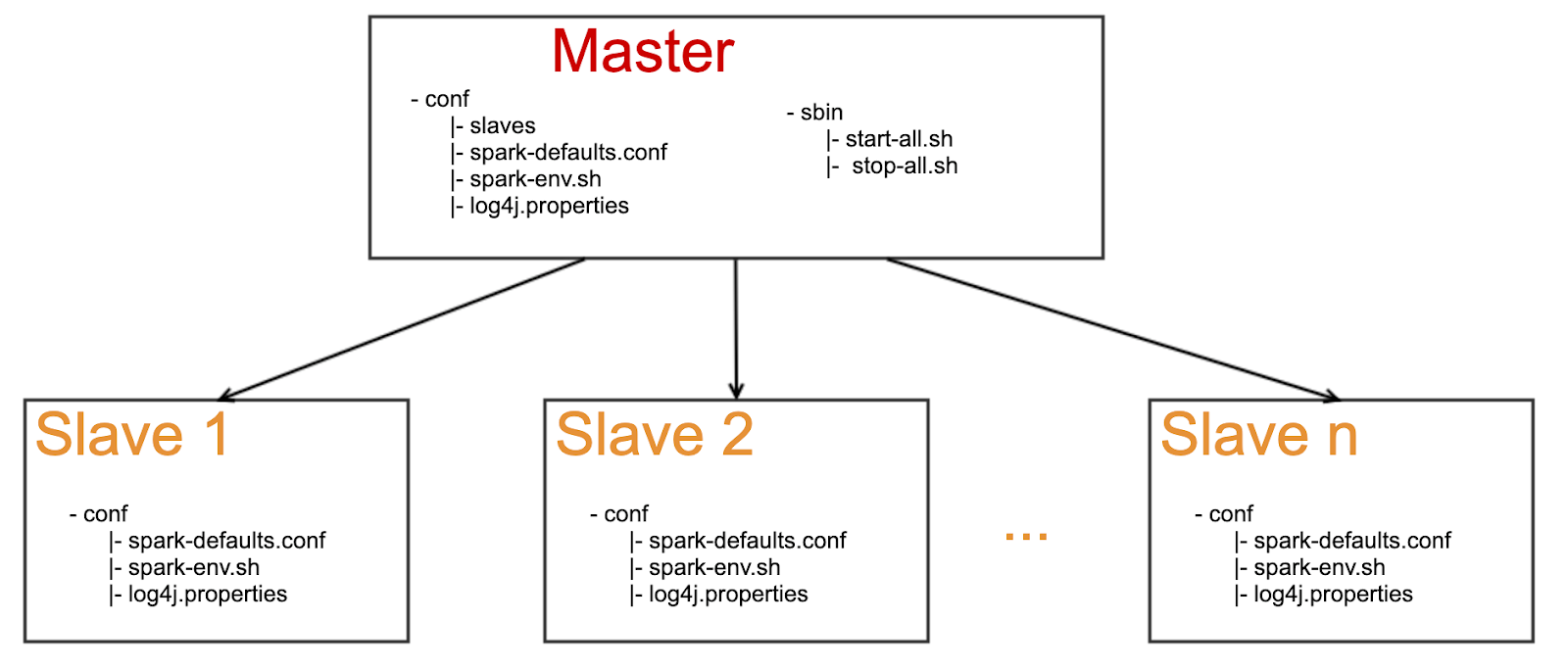
Spark Standalone集群配置文件
Spark Standalone集群的配置文件都在conf目录下面,常用的有这几个:
- conf/spark-defaults.conf
- conf/spark-env.sh
- conf/log4j.properties
一般升级spark的时候,只需要把conf目录下面的文件拷贝到新的安装目录即可。
Spark Standalone集群运维
Spark Standalone集群运维脚本都在sbin目录下面,常用的有这几个:
- sbin/start-all.sh
- sbin/stop-all.sh
Spark Master会通过JVM启动org.apache.spark.deploy.master.Master这个Class。
Spark Worker会通过JVM启动org.apache.spark.deploy.worker.Worker这个Class。
可以通过ps或者jps查看当前机器是否已经启动了对应进程。
Spark Master会开启本地8080端口,可以通过http://${master ip}:8080查看对应的网页。
Spark日志一般在安装目录的logs子目录下,如果没有,请看一下conf/spark-env.sh里面的这个配置SPARK_LOG_DIR。
Spark Standalone集群升级步骤
准备工作
先确认一下
- 需要升级的spark集群是否是standalone集群(其他模式不在本文档描述范围)
- 是否单独给TiSpark使用(如果有其他业务使用,需要让其他业务确认)
- 有没有启动其他组件,例如thriftserver、zeppelin等(需要同时升级其他组件)
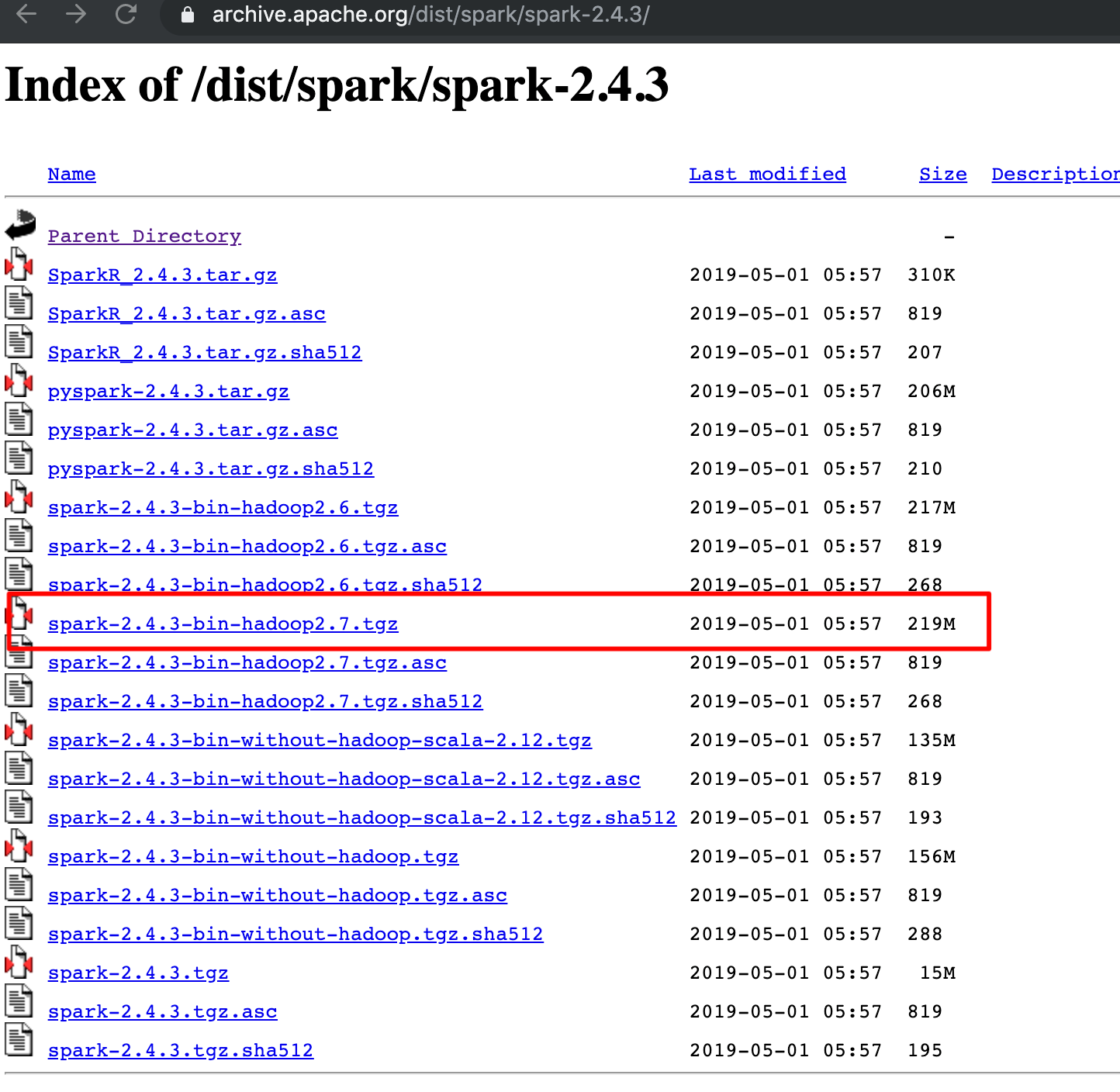
下载Spark
Spark下载地址 https://archive.apache.org/dist/spark/,
例如spark-2.4.3,建议下载
https://archive.apache.org/dist/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
下载TiSpark
TiSpark下载地址,https://github.com/pingcap/tispark/releases。
如果不知道下载哪个jar包,请看https://github.com/pingcap/tispark#how-to-choose-tispark-version。

升级步骤
-
停止老的spark集群 :运行 ./sbin/stop-all.sh,通过ps和jps确认进程已停止,同时看下进程日志进行确认
-
归档老集群:在所有master和slave机器上,将老的spark安装目录重命名
-
安装新集群:下载spark并解压到所有master和slave机器,并重命名为原来的名字
-
安装tispark jar包:tispark jar包有2中使用方式,具体用哪种需要看原来的集群是用哪种(看老的spark安装目录下jars子目录里面有没有tispark的jar包)
-
将tispark jar包拷贝到spark安装目录下面的jars子目录
-
运行bin/spark-shell的时候通过–jar命令指定tispark jar包
-
配置conf:将原来的conf目录拷贝到新的安装目录
-
启动新集群:在新的spark目录里面运行./sbin/start-all.sh
-
打开master web ui: http://${master ip}:8080,确认可以访问,确认work个数、core个数、内存数是否符合预期
-
简单测试:./bin/spark-shell --master spark://${master ip}:7077 运行一些简单的测试命令,例如看看是否能访问tidb
-
回归测试:运行客户之前的程序,看看是否有问题,结果是否正确
TiSpark兼容性
从TiSpark-1.x升级到TiSpark-2.x的时候需要特别注意一下兼容性,大概率需要客户修改代码。
TiSpark-1.x需要使用tidbMapDatabase才能访问tidb的数据,例如
import org.apache.spark.sql.TiContext
val ti = new TiContext (spark)
ti.tidbMapDatabase (“tpch_test”)
spark.sql(“select count(*) from lineitem”).show
但是到了TiSpark-2.x用户不需要调用tidbMapDatabase直接可以访问,例如
spark.sql(“use tpch_test”)
spark.sql(“select count(*) from lineitem”).show