TiDB版本2.1.6,集群3个节点,每台机器1个pd。 集群掉电后恢复重启,pd1无法启动,pd报错日志如下: [fatal] etcdserver: [recovering backend from snapshot error: failed to find database snapshot file (snap: snapshot file does not exist)]
请问如何解决?
TiDB版本2.1.6,集群3个节点,每台机器1个pd。 集群掉电后恢复重启,pd1无法启动,pd报错日志如下: [fatal] etcdserver: [recovering backend from snapshot error: failed to find database snapshot file (snap: snapshot file does not exist)]
请问如何解决?
现在 PD Leader 是哪一个?整个集群能正常对外提供访问吗?可以把这个 PD 节点数据目录清掉,按照 新节点扩容的方式重新加入到集群中。
现集群可以对外提供服务。 还有几个问题:
1)使用 pd-ctl 连进去,执行 member,可以看到 Leader 在哪个 pd-server 上。 2)是的。建议先部署个测试环境把流程测通,不要直接操作线上。
【TiDB 版本】
2.1.6,ansible部署。
【集群节点分布】
3台机器,每台机器部署1个tidb、1个pd、2个tikv、1个pump,第2台机器多部署1个drainer。
【问题描述】
按照以下官网说明尝试先下线pd1,再扩容pd1:
https://pingcap.com/docs-cn/v2.1/how-to/scale/with-ansible/#使用-tidb-ansible-扩容缩容-tidb-集群
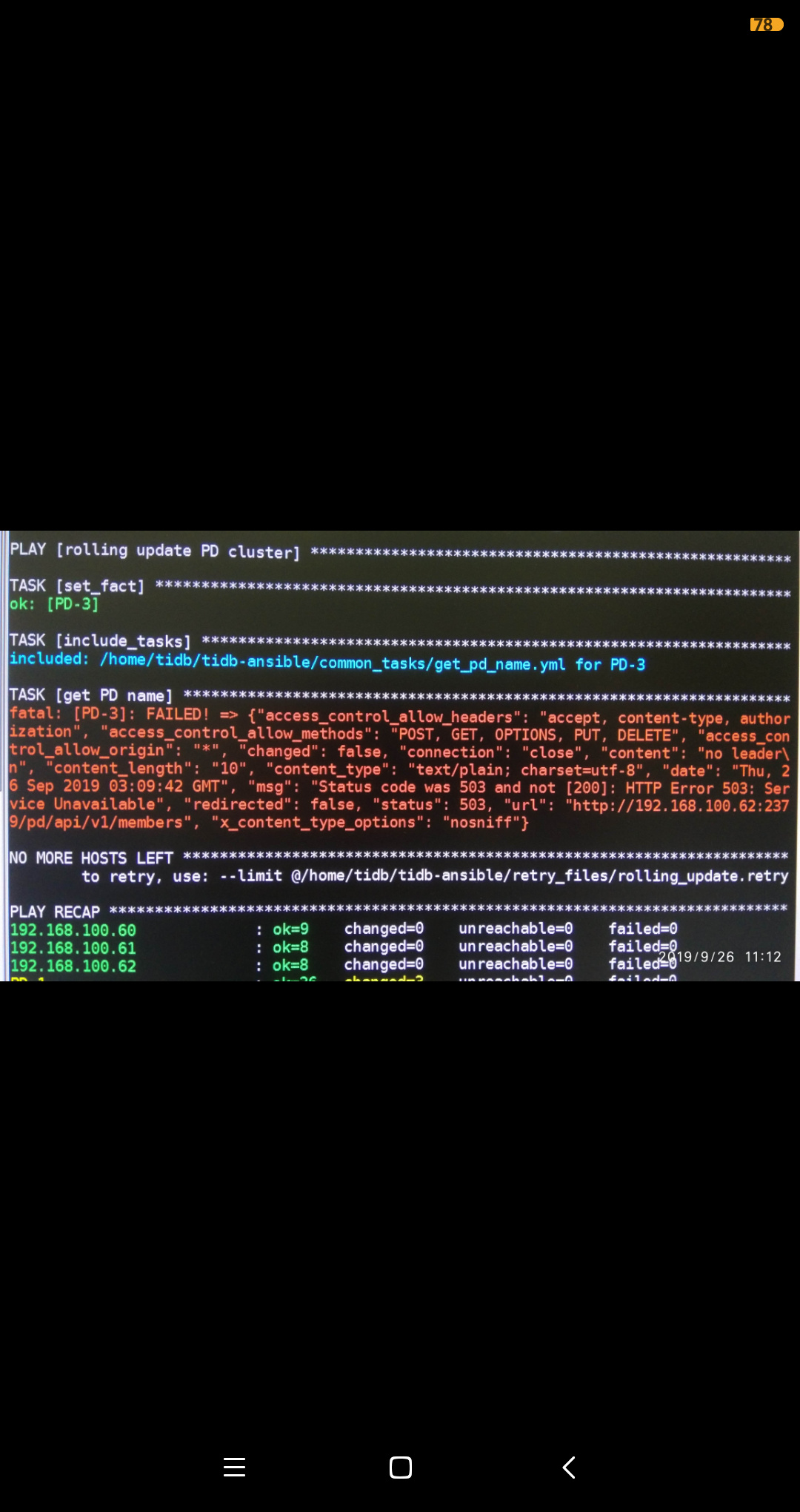
现在下线(缩容)pd1过程中出现问题,在“缩容PD节点”章节第5步执行“ansible-playbook rolling_update.yml”报错,报错截图如下:
为什么下线pd1,pd3反而报错?请问如何解决?
【补充说明】
注意到官网文档有以下这句话:
以下缩容示例中,被移除的节点没有混合部署其他服务;如果混合部署了其他服务,不能按如下操作。
现pd1所在机器的确还部署了tidb、tikv、pumpr等角色,不知道这个有没有影响?
我已经改良第3步“ansible-playbook stop.yml -l 172.16.10.2”为“ansible-playbook stop.yml -l PD1”。
下线 pd1 通过 pd-ctl member 如果确认执行成功就没问题了,后面 pd3 报错是因为执行 rollling_update 重启包括 pd3 在内的另外两个 pd 时的问题,member 确认下是否 leader 节点存在,如果正常那重试下 rolling_update 操作,如果仍然报错,可以到 github 上的 tidb-ansible 下面提 issue
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。