根据描述,下线 drainer 的操作不正确,看下 https://pingcap.com/docs-cn/stable/reference/tidb-binlog/maintain/ 这里的介绍,正常下线流程在确认 drainer 不在需要, binlogctl 修改 drainer 状态为 offline 即可。
明白,就比如我这个drainer 机器宕机,无法启动了,我如何把pd里面的信息清理掉,彻底下线这个drainer 节点
参考这里 :https://pingcap.com/docs-cn/stable/reference/tidb-binlog/maintain/ 修改下 drainer 的状态 paused -> offine : bin/binlogctl -pd-urls=http://127.0.0.1:2379 -cmd update-drainer -node-id ip-127-0-0-1:8250 -state offline 下线之后会自动清理 PD 里面的信息
这个问题确认下一点:是监控没数据但是同步状态是正常的,数据也已经正常同步到下游了吗?如果是的话,监控里面 pump 的数据显示是否正常,还是只有 drainer 是没数据的。
1、同步状态都是正常的, drainer都正常同步dump的数据到下游的rds了, 2、监控里面的dump的数据正常,我上面已经截团了,就是 drainer 没数据
执行完-cmd update-drainer -node-id db-otter-3-vik7-prod:8249 -state offline 之后,这个节点的信息多久才能在pd里面删除,我执行完10分钟左右了,在pd里面还能看到
drainer 在 PD 里面的信息不会清理掉,但是 drainer 是已经下线了。另外监控数据不上报问题,看操作了删除 drainer 的目录以及 kill 进程,前后顺序是?
1、我删drainer 目录和kill进程,是操作的要下线的drainer 节点(172.21.244.174)
2、没监控数据的drainer 节点是正常部署并且现在正常使用的(172.21.244.175)
3、我先部署的drainer ,然后更新的监控 ansible-playbook rolling_update_monitor.yml --tags=prometheus
下面是prometheus里面drainer 的配置

- drainer 服务所在机器执行 curl http://{ip}:{port}/metrics 检查 drainer 服务是否生产监控指标
- 如果有数据,确认下 drainer 服务到 prometheus 服务的网络是否互通

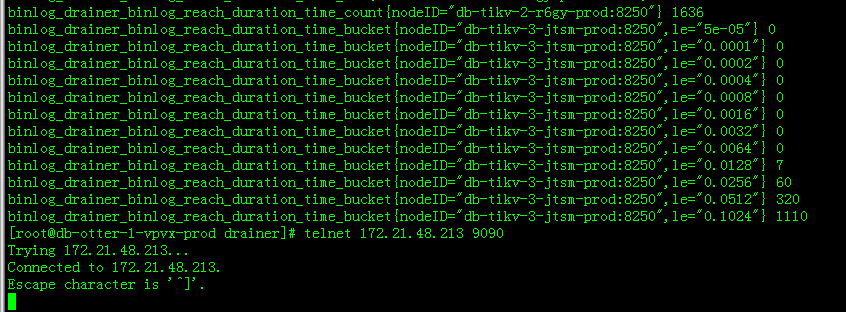
1)在查到的信息里面 greo binlog_drainer_pump_position 2)在 prometheus 页面 target 看下 drainer 服务是否正常。
非常感谢,找到原因了,是因为prometheus 无法访问drainer的端口,把网络权限打开就好, 感谢
offline状态的节点时候从pd里面彻底删除,我上午执行的-cmd update-drainer -node-id db-otter-3-vik7-prod:8249 -state offline ,现在看pd里面这条下线的记录还在,有办法从pd里面彻底删除这条记录嘛
![]()
![]()
![]()
drainer 其实已经下线了,PD 里面的信息可以忽略,不影响使用。
明白,只是看着不舒服,想把他清理干净![]()
![]() 不影响使用
不影响使用
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。