为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:tidb 3.0 GA
- 【问题描述】:
1.针对大数据量数据的分组、聚合 导致db节点内存耗光,引起db节点不能正常提供服务。
2.具体描述如下
- 2.1 参数计算的数据量
参与计算的数据量为1500万。
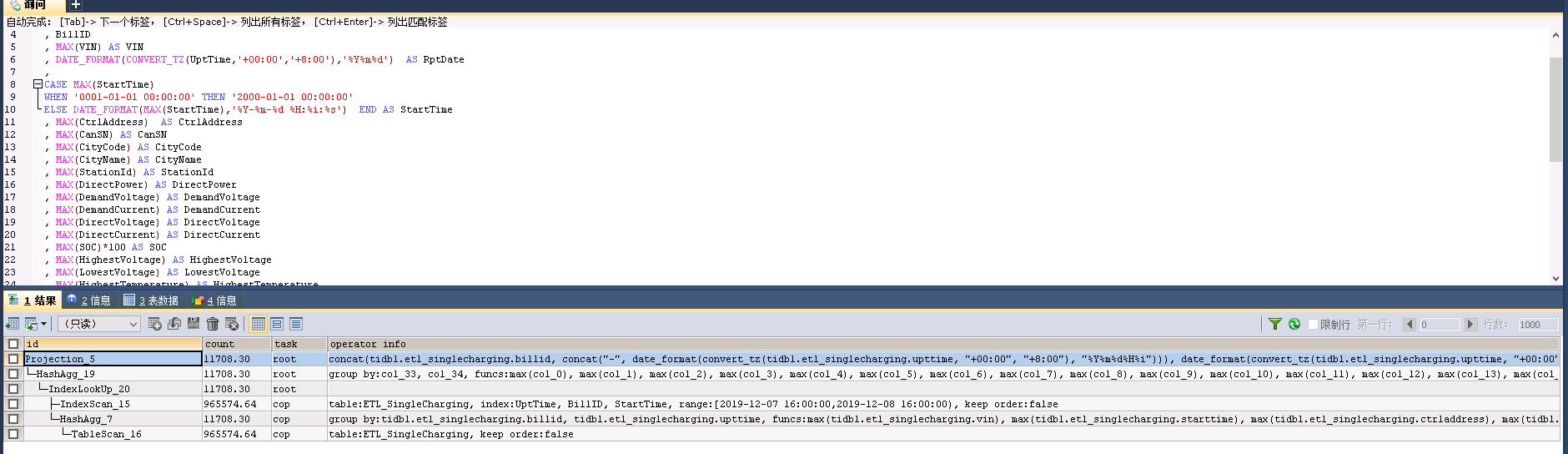
- 2.2 计算的sql
SELECT concat(BillID,concat(‘-’,DATE_FORMAT(CONVERT_TZ(UptTime,‘+00:00’,‘+8:00’),‘%Y%m%d%H%i’))) as rowkey,
DATE_FORMAT(CONVERT_TZ(UptTime,‘+00:00’,‘+8:00’),‘%Y%m%d%H%i’) as UptTime
, BillID
, max(VIN) as VIN
, DATE_FORMAT(CONVERT_TZ(UptTime,‘+00:00’,‘+8:00’),‘%Y%m%d’) as RptDate
,
case max(StartTime)
when ‘0001-01-01 00:00:00’ then ‘2000-01-01 00:00:00’
else DATE_FORMAT(max(StartTime),‘%Y-%m-%d %H:%i:%s’) end as StartTime
, max(CtrlAddress) as CtrlAddress
, max(CanSN) as CanSN
, max(CityCode) as CityCode
, max(CityName) as CityName
, max(StationId) as StationId
, max(DirectPower) as DirectPower
, max(DemandVoltage) as DemandVoltage
, max(DemandCurrent) as DemandCurrent
, max(DirectVoltage) as DirectVoltage
, max(DirectCurrent) as DirectCurrent
, max(SOC)*100 as SOC
, max(HighestVoltage) as HighestVoltage
, max(LowestVoltage) as LowestVoltage
, max(HighestTemperature) as HighestTemperature
, max(LowestTemperature) as LowestTemperature
, max(Power) as Power
, max(MinutePower) as MinutePower
, max(V3RemainTime) as V3RemainTime
, max(BdpRemainTime) as BdpRemainTime
, max(StaType) as StaType
, max(StaTypeNames) as StaTypeNames
, max(PileQuickType) as PileQuickType
, max(PileQuickName) as PileQuickName
, max(OperType) as OperType
, max(OperTypeName) as OperTypeName
, max(Industry) as Industry
, max(IndustryName) as IndustryName
, max(BillInitElectricMeter) as BillInitElectricMeter
, max(CurrentElectricMeter) as CurrentElectricMeter
FROM ETL_SingleCharging
WHERE upttime>=DATE_FORMAT(DATE_ADD(current_date(),INTERVAL -2 DAY),‘%Y-%m-%d 16:00:00’)
AND upttime<DATE_FORMAT(DATE_ADD(current_date(),INTERVAL -1 DAY),‘%Y-%m-%d 16:00:00’)
group by BillID,UptTime
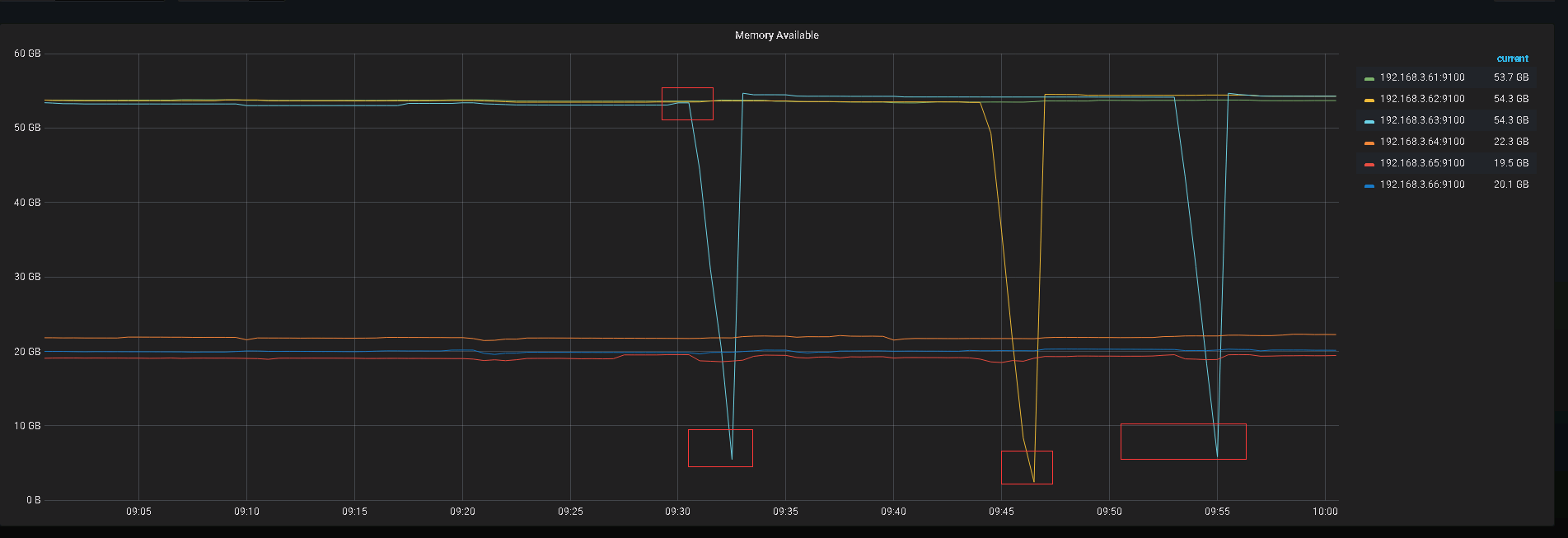
2.3 问题
tidb节点内存耗光。
2.4 疑问
1.针对这种大数据量的分组聚合,所有的数据从各个节点,汇总到db节点,然后在分组聚合,这种是无法使用分布式资源, 这种情况应该如何处理